AIxiv专栏是AI在线发布学术、技术内容的栏目。过去数年,AI在线AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:[email protected];[email protected]
本论文由伦敦大学学院、上海交通大学、布朗大学、布里斯托大学、新加坡国立大学以及萨里大学的研究者合作完成。
冯熙栋是论文第一作者,即将毕业于伦敦大学学院。目前是Google DeepMind的Research Scientist,主要研究方向包括强化学习与生成模型。刘博是本推文作者,新加坡国立大学二年级博士生,研究强化学习、推理及机器学习系统在复杂现实环境中的应用。
在人工智能发展史上,强化学习 (RL) 凭借其严谨的数学框架解决了众多复杂的决策问题,从围棋、国际象棋到机器人控制等领域都取得了突破性进展。
然而,随着应用场景日益复杂,传统强化学习过度依赖单一数值奖励的局限性日益凸显。在现实世界中,反馈信号往往是多维度、多模态的,例如教练的口头指导、视觉示范,或是详细的文字说明。
来自伦敦大学学院、上海交通大学、布朗大学、新加坡国立大学和布里斯托大学的联合研究团队提出了全新的自然语言强化学习(Natural Language Reinforcement Learning, NLRL)范式,成功将强化学习的核心概念类比为基于自然语言的形式,开辟了一条通向更智能、更自然的 AI 决策学习的新道路。

论文题目: Natural Language Reinforcement Learning
论文链接: https://arxiv.org/abs/2411.14251
代码链接: https://github.com/waterhorse1/Natural-language-RL
从数值到语言:新范式的萌芽
随着大语言模型(LLM)在理解和生成自然语言方面的飞速发展,研究者们开始探索如何让 AI 系统像人类一样通过语言来理解任务、制定策略并解释决策过程。论文第一作者的早期工作 ChessGPT(https://arxiv.org/abs/2306.09200)尝试通过收集对局评论来训练语言模型并取得了一定成功。然而,这种基于人类数据的学习方式很快遇到了瓶颈:互联网数据质量参差不齐,高质量专家标注成本高昂,而对于全新任务更是无从获取相关经验数据。
这种困境促使研究团队开始探索一个更具突破性的方向:能否设计一个框架,让 AI 系统完全通过与环境的交互来学习,而不依赖任何人类标注数据?传统强化学习为这个问题提供了灵感,但其单一数值奖励的机制难以满足复杂场景的需求。团队意识到需要一个新范式,既要继承强化学习的数学严谨性,又要具备自然语言的表达丰富性。这个思路最终导向了 NLRL 的诞生。
自然语言强化学习
传统强化学习虽然在数学上严谨优雅,但其单一数值反馈机制与人类学习方式存在巨大差距。研究团队从象棋教练指导学生的场景获得启发:教练不会简单说 “这步棋的价值是 0.7”,而是会详细解释 “这个走法控制了中心,限制了对手的机动性,同时为王翼进攻创造了条件”。这种观察促使团队思考:能否将丰富的语言反馈信号整合进学习框架?
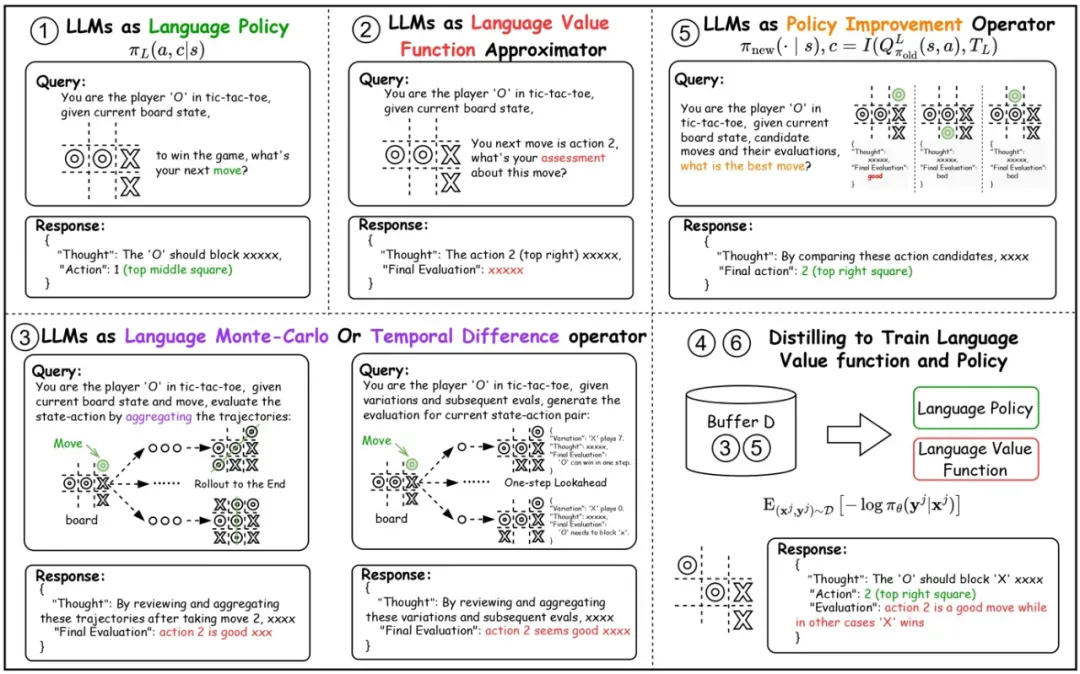
这个思路的关键突破来自对传统强化学习本质的重新思考:既然传统 RL 可以通过蒙特卡洛和时序差分等方法进行学习,这些方法是否可以扩展到语言空间?基于这一洞察,团队提出了 NLRL 框架,将传统 RL 中的数学概念类比为语言形式。以下是一个对应关系示意图。
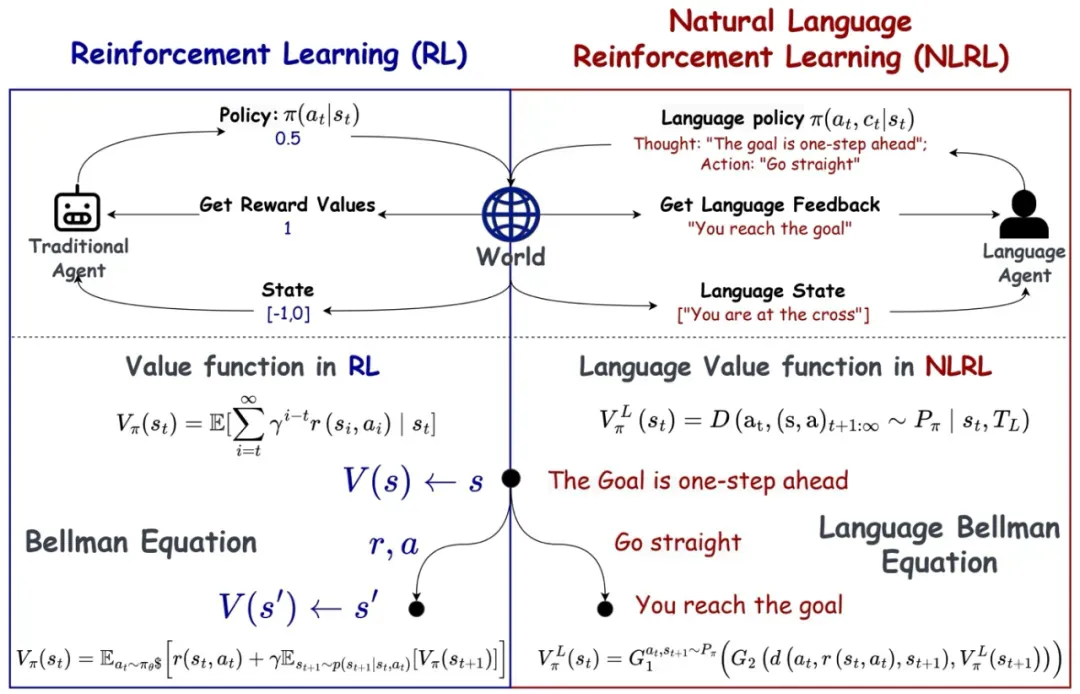
具体而言,NLRL 引入 “语言任务指令”(T_L)替代抽象的奖励函数,并设计了度量函数 F 来评估轨迹描述 D_L (τ_π) 与任务指令的完成度。
语言化的决策框架
在 NLRL 中,MDP 的每个组成部分都被重新定义为文本形式。状态变为包含完整上下文的自然语言描述,动作空间转化为带有推理过程的语言决策,而环境反馈则扩展为包含原因分析的详细评估。例如,在迷宫环境中的状态描述会包含位置、周围环境、历史探索等完整信息。
语言策略与推理
NLRL 中的策略 π_L 被创新性地分解为两个部分:π_L (a,c|s) = π_L (c|s)π_L (a|c,s),其中 c 代表思维过程。这种分解使得决策过程变得完全透明。以国际象棋为例,系统会先分析局势(“白方控制中心点,黑方王翼薄弱”),提出计划(“开展王翼进攻,同时固守中心”),最后给出具体建议(“Nf3-e5,威胁 f7 并加强中心控制”)。
语言价值评估
NLRL 将传统的标量值函数 V (s) 和 Q (s,a) 扩展为语言价值函数 V^L_π 和 Q^L_π。这种扩展使得评估变得更加丰富和可解释。评估结果不仅包含胜率,还涵盖空间利用、子力配合等多个角度的分析,并提供具体的改进建议。
从理论到实践
将强化学习的数学概念转化为语言形式是一个优雅的构想,但如何在实践中实现这种转化却是一个巨大的挑战。研究团队意识到,近年来大语言模型在自然语言处理和推理能力方面的突破,为 NLRL 的实现提供了关键工具。通过深入研究大语言模型的能力边界,团队发现 LLM 不仅能够理解和生成自然语言,还具备 information synthesis(信息综合)、reasoning(推理)和 correlation analysis(相关性分析)等能力,这些能力恰好对应了传统强化学习中的期望计算、价值估计和策略改进等核心操作。
基于这一洞察,研究团队提出了三个关键技术创新,构建了完整的 NLRL 实现框架:
语言蒙特卡洛估计
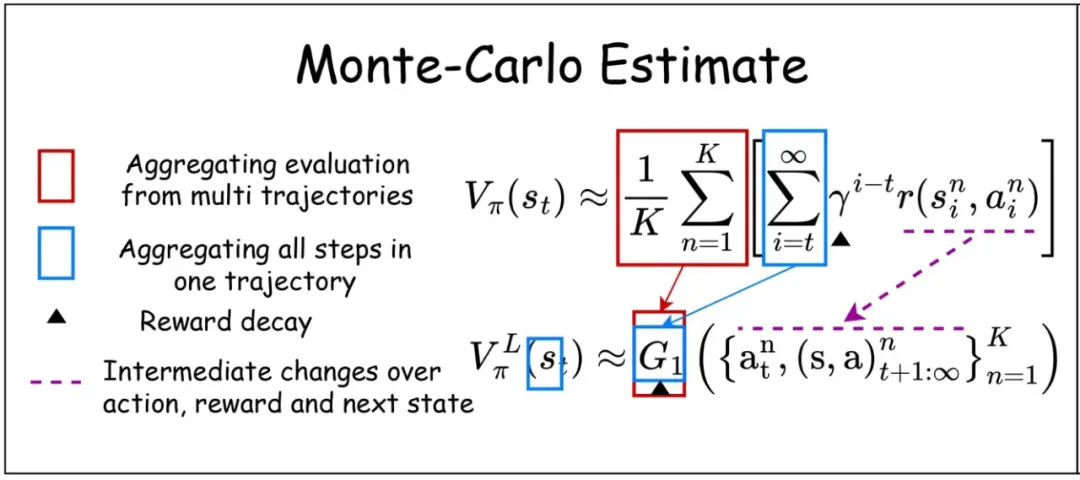
在传统强化学习中,蒙特卡洛方法通过采样多条轨迹并取平均值来估计状态价值。但在语言空间中,我们无法直接对文本描述进行算术平均。研究团队利用大语言模型作为信息聚合器 (aggregator)。
具体来说,当系统需要评估某个状态时,它会:
1. 从该状态开始采样 K 条完整轨迹
2. 将每条轨迹转化为详细的文本描述
3. 使用专门设计的提示让 LLM 扮演 “专家评估员” 的角色
4.LLM 分析所有轨迹描述,提取关键模式和见解
5. 生成一个综合性的评估报告
例如,在国际象棋中,系统可能会分析说:“基于观察到的 20 个可能发展,此位置对白方有利。在 80% 的变化中,白方能够通过控制中心格和针对 f7 的战术威胁获得优势。但需要注意的是,如果黑方成功完成王翼城堡,局势可能趋于平衡。”
语言时序差分学习
传统的时序差分学习基于贝尔曼方程,将长期价值分解为即时奖励和未来状态的折扣价值。NLRL 创新性地提出了语言贝尔曼方程,将这种时序关系扩展到语言空间。
在 NLRL 中,语言时序差分学习包含三个关键组件:
1. 文本描述生成器 d:将状态转换 (s,a,r,s') 转化为自然语言描述
2. 信息聚合函数 G1:综合多个时间步的信息
3. 语言组合函数 G2:将即时反馈与未来评估结合
这三个组件协同工作的方式如下:
首先,d 将环境反馈转化为详细的文本描述,包括采取的动作、即时反馈和到达的新状态
G2(通常是一个经过特殊提示的 LLM)将即时描述与对未来状态的语言评估结合,生成一个整体性的分析
G1 聚合多个这样的分析,得出最终的状态评估
在实践中,这种方法表现出了独特的优势:
可以捕捉到难以量化的微妙因素
评估结果具有很强的可解释性
能够处理长期依赖关系

语言策略提升
在传统强化学习中,策略提升通常通过梯度上升来最大化期望回报。但在语言空间中,我们需要一个全新的策略提升机制。研究团队提出了基于语言相关性分析的策略提升方法。
这种提升机制的工作原理是:
1. 对当前状态收集多个候选动作
2. 获取每个动作的语言价值评估
3. 使用 LLM 分析这些评估与任务目标的相关性
4. 生成改进的决策链路,包括:
详细的推理过程
对不同选项的权衡分析
最终决策的依据
例如,在迷宫导航任务中,系统可能会这样分析:“向右移动是最优选择,因为:1)根据之前的探索经验,右侧路径更可能通向目标 2)即使这条路不是最短路径,也为我们保留了回退的选项 3)相比向上移动可能遇到的死胡同,这个选择风险更小。”
实验验证
研究团队在三个具有代表性的环境中系统地验证了 NLRL 的效果。这些实验不仅展示了 NLRL 的性能优势,更重要的是证明了该框架在不同类型任务中的普适性和可扩展性。
迷宫导航 - 基于 prompt 的自然语言策略迭代
在复杂的迷宫导航任务中,研究团队测试了纯基于 prompt 的自然语言策略迭代算法。研究团队选择了两种具有挑战性的迷宫环境进行测试:双 T 型迷宫和中等复杂度迷宫。在这些环境中,智能体需要从随机初始位置导航到目标位置,同时避免撞墙。通过语言 TD 估计,在双 T 型迷宫中实现了 - 11.19±2.86 的平均奖励,远优于基线方法的 - 27.29±4.43。但 NLRL 真正的优势不仅仅体现在数字上。系统能够清晰地解释每个决策的原因,例如:“选择向南移动,因为:1)北边是死胡同,我们之前已经探索过 2)南向路径似乎更接近目标位置 3)即使这条路不是最优解,我们仍保留了向东撤退的选项。” 实验还发现,增加变化数量和前瞻步数能进一步提升性能。

突破棋 (Breakthrough)- 自然语言价值函数
在 5x5 突破棋(状态空间达 10^8)这个几乎没有人类数据的任务中,NLRL 纯依靠环境反馈训练出了高质量的语言评估器。通过混合不同水平的 MCTS 策略数据构建训练集,评估器达到了 0.85 的准确率,显著超越 LLAMA-3.1-70b 的 0.61 以及 GPT-4o 的 0.58。更重要的是,这个评估器能提供专业级别的局势分析。例如:“黑方略占优势,原因有三:1)在 d4 和 e4 形成了稳固的双兵链 2)白方右翼的兵形成了薄弱点 3)黑方的推进速度比白方快半步。建议白方通过 c3-c4 来争夺中心控制权。”

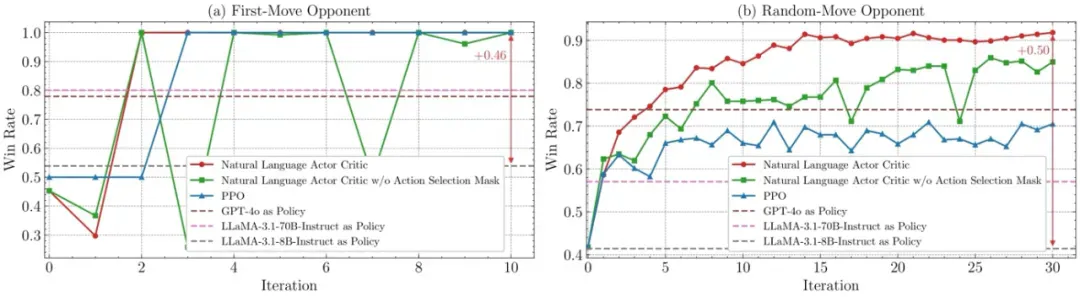
井字棋 - 自然语言 Actor-Critic
在井字棋环境中,团队实现了完整的语言 Actor-Critic 系统。通过动作选择掩码防止幻觉、经验缓冲区解决遗忘问题、持续的迭代优化等创新,系统在随机对手下实现 90% 以上胜率,面对确定性策略甚至能保持 100% 的胜率,同时保持决策过程的清晰可解释性。