Recently, a research team from the University of Hong Kong, The Chinese University of Hong Kong, and SenseTime has released a remarkable new framework - GoT-R1. This innovative multimodal large model significantly enhances AI's semantic and spatial reasoning capabilities in visual generation tasks by introducing reinforcement learning (RL), successfully generating high-fidelity and semantically consistent images from complex text prompts. This advancement marks another leap forward in image generation technology.
Currently, although existing multimodal large models have made significant progress in generating images based on text prompts, they still face many challenges when handling instructions involving precise spatial relationships and complex combinations. GoT-R1 was created to address this issue. Compared to its predecessor GoT, GoT-R1 not only expands AI's reasoning capabilities but also enables it to autonomously learn and optimize reasoning strategies.
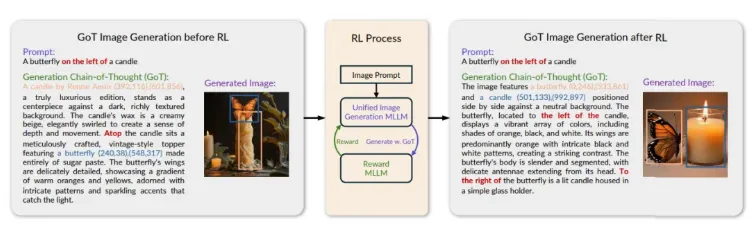
The core of GoT-R1 lies in its reinforcement learning mechanism. The team designed a comprehensive and effective reward mechanism to help the model better understand complex user instructions during image generation. This mechanism covers multiple evaluation dimensions, including semantic consistency, accuracy of spatial layout, and overall aesthetic quality of the generated image. More importantly, GoT-R1 also visualizes the reasoning process, allowing the model to more accurately assess the effectiveness of image generation.
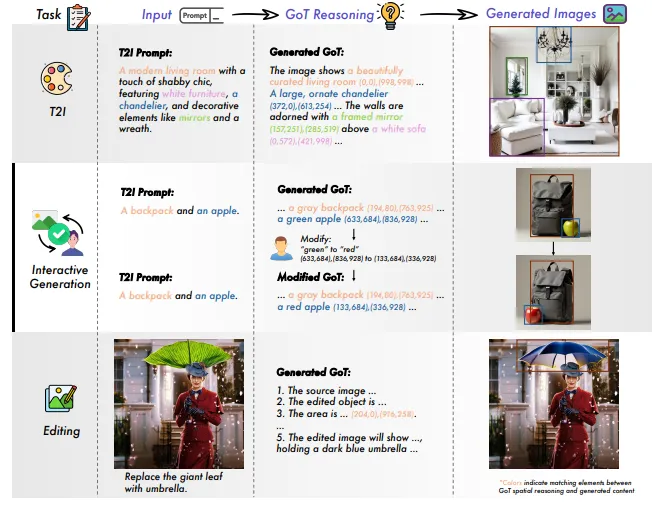
After comprehensive evaluation, the research team found that GoT-R1 performed exceptionally well in a benchmark test called T2I-CompBench, especially in handling complex multi-level instructions, demonstrating capabilities surpassing other mainstream models. For example, in the "complex" benchmark test, GoT-R1 showed outstanding performance, with its strong reasoning and generation capabilities enabling the model to achieve the highest scores in multiple evaluation categories.
The release of GoT-R1 has injected new vitality into multimodal image generation technology, showcasing the infinite possibilities of AI in handling complex tasks. With the continuous development of technology, future image generation will become more intelligent and precise.
Paper: https://arxiv.org/pdf/2503.10639