Recently, Inclusion AI and Ant Group jointly launched an advanced multimodal model called "Ming-Omni," marking a new breakthrough in intelligent technology. Ming-Omni is capable of processing images, text, audio, and video, providing powerful support for various applications. Its functions not only cover speech and image generation but also possess the ability to integrate and process multimodal inputs.
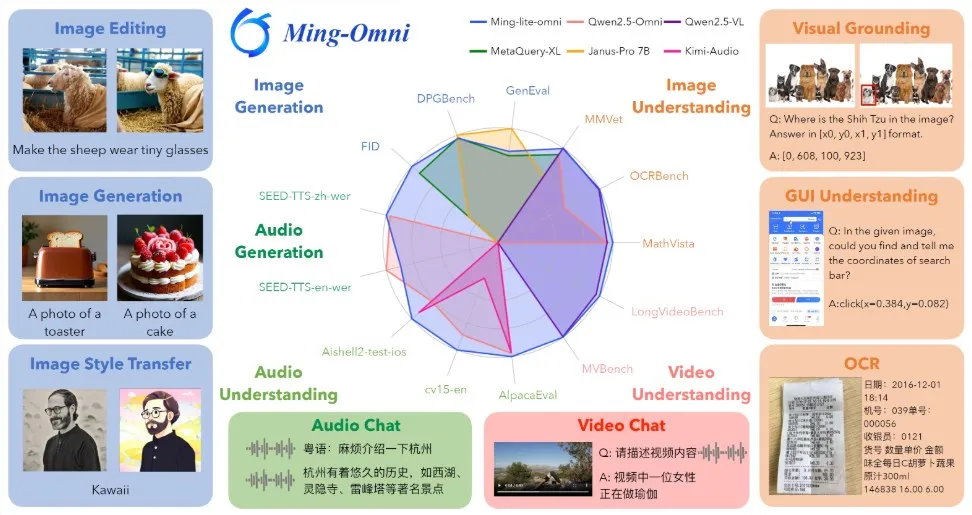
** Comprehensive Multimodal Processing Capability **
The design of Ming-Omni incorporates dedicated encoders to extract tokens from different modalities. These tokens are processed by the "Ling" module (i.e., mixture-of-experts architecture, MoE), which is equipped with newly proposed modality-specific routers. This enables Ming-Omni to efficiently handle and fuse multimodal inputs, supporting various tasks without requiring additional models, specific task fine-tuning, or structural reorganization.
** Revolution in Speech and Image Generation **
One notable highlight of Ming-Omni compared to traditional multimodal models is its support for audio and image generation. By integrating advanced audio decoders, Ming-Omni can generate natural and fluent speech. Additionally, its use of the high-quality image generation model "Ming-Lite-Uni" ensures the precision of image generation. Furthermore, the model can perform context-aware dialogues, text-to-speech conversion, and diverse image editing, showcasing its potential across multiple domains.
** Smooth Voice and Text Conversion **
Ming-Omni's capabilities in language processing are equally impressive. It has the ability to understand dialects and perform voice cloning, converting input text into speech output in various dialects, demonstrating its strong linguistic adaptability. For example, users can input different dialect sentences, and the model will be able to understand and respond in the corresponding dialect, enhancing the naturalness and flexibility of human-computer interaction.
** Open Source, Promoting Research and Development **
Notably, Ming-Omni is the first known open-source model that matches GPT-4o in terms of modality support. Inclusion AI and Ant Group have committed to making all code and model weights public, aiming to inspire further research and development within the community and drive continuous progress in multimodal intelligence technology.
The release of Ming-Omni not only injects new vitality into the field of multimodal intelligence but also provides more possibilities for various applications. As technology continues to evolve, we look forward to Ming-Omni playing a greater role in future intelligent interactions.
Project: https://lucaria-academy.github.io/Ming-Omni/