最近的 Meta 可谓大动作不断,一边疯狂裁人,一边又高强度产出论文。
10 月 20 日,他们又上线了一篇新论文《The Free Transformer》,作者只有一位,日内瓦大学教授、Meta 研究科学家 François Fleuret。有意思的是,François 所在的 FAIR 是 Meta 近日裁员最严重的部门之一。

论文标题:The Free Transformer
论文地址:https://arxiv.org/pdf/2510.17558
在这篇文章中,François 重写了 Transformer 的思维方式,造出了一个叫 Free Transformer 的新架构(一种新解码器 Transformer 扩展,它使用无监督潜在变量来提高下游任务的性能),直接打破了自 2017 年以来所有 GPT 模型赖以存在的核心规则。
在过去的 8 年里,Transformer 一直像是被蒙上眼睛的猜词机器,在生成内容时,只能一次预测一个最有可能的 next token,没有内在计划,也没有潜在思考,也不能返回来修改。
这种想什么就直接说什么的方式,会导致模型出现幻觉,也就是把编造的内容说得信誓旦旦。Transformer 其实需要具备某种反思能力,才能避免冗长、杂乱的思维链输出。
而 Meta 给了它一个。他们在解码器内部加入了随机潜在变量,让模型能在开口说话之前,先在内部秘密地决定自己要怎么生成内容。这就像是给 GPT 装上了一颗隐藏的心智。

结果显示,在 15 亿和 80 亿参数的模型上,这一方法在代码生成、数学文字题和多选任务上都取得了明显提升。
Free transformer「新」在哪里?
任何潜在的随机变量 Y_r,无论它与 token S_1,…,S_t 以及此前采样的其他潜在变量 Y_1,…,Y_r−1 之间存在怎样的统计依赖关系,在合理的假设下,都可以表示为一个函数 f_r (S_1,…,S_t, Y_1,…,Y_r−1, Z_r),其中 Z_r 是来自随机生成器的一个值。
因此,如果在生成过程中为模型提供足够多相互独立采样的随机值 Z_1, Z_2,…,那么只要模型的容量足以编码函数 f_r,合适的训练过程原则上就可以构建出具有任意依赖结构的潜在变量族。
正如在采样过程中对一个 token 的选择可以表示为随机值和 logits 函数一样,任何依赖随机值和其他激活的激活函数也可以被解释为模型在生成过程中所做出的某种决策。这样的决策使得潜在激活成为 token 的非确定性函数,而仅观察 token 只能获得关于这些潜在激活的部分信息。
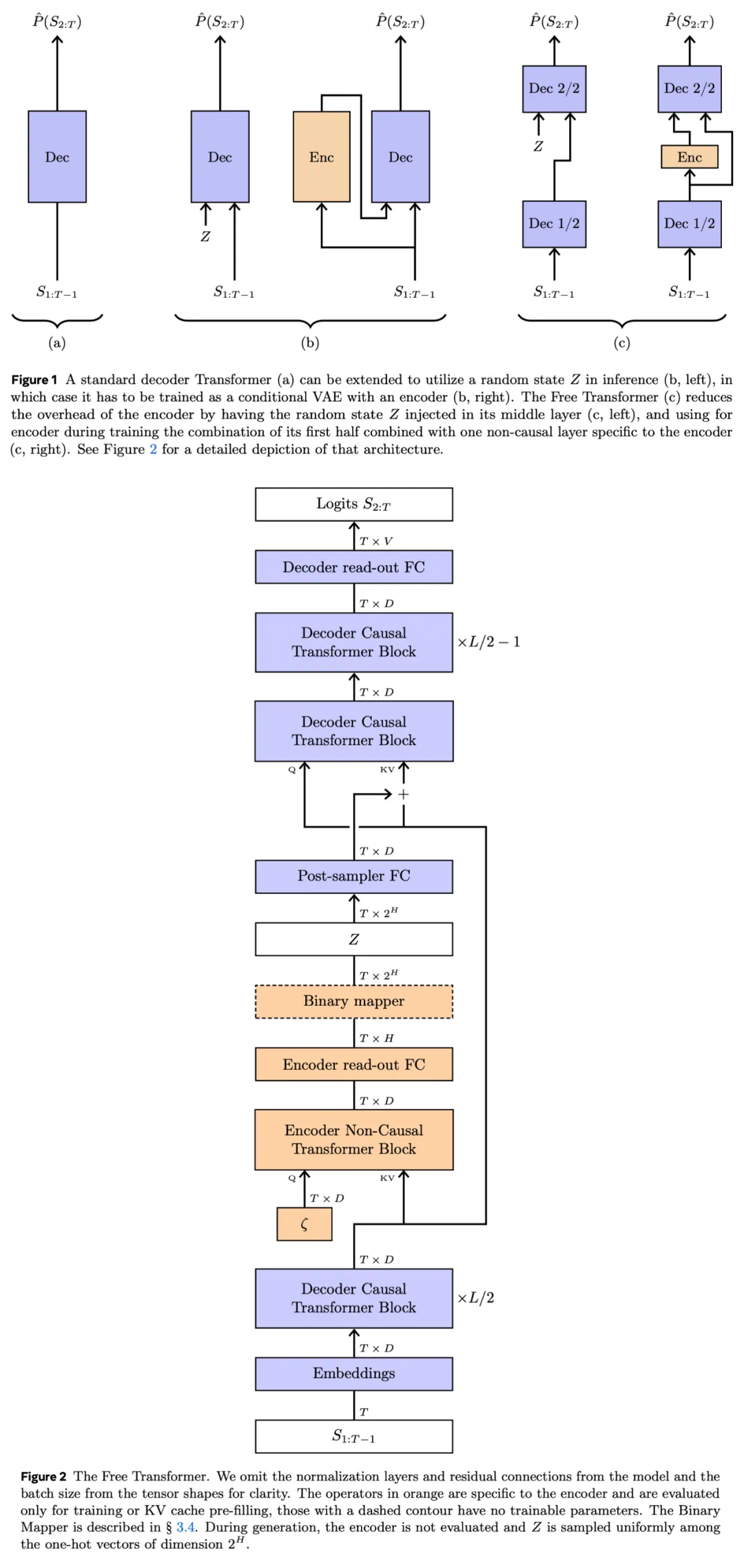
那么,Free Transformer 的模型架构是怎样的呢?作者将「Transformer Block」称为由多头注意力层和类 MLP 的逐 token 模块的常规组合,并包含归一化层与残差连接。
架构概览如下图 1 和图 2 所示,Free Transformer 是一种在中间层注入噪声 Z 的标准解码器结构。这样的设计允许与编码器共享一半的 Transformer 模块,从而显著减少计算开销,这是因为只有一个 Transformer 模块需要专门为编码器计算。
正如我们将看到的,这个模型拥有解码器 Transformer 的全部组件,同时为编码器增加了一个非因果模块和两个线性层。
作者尚未研究在何种深度注入 Z 最为合适,注入得太早会削弱编码器的表达能力,而注入得太晚又会削弱解码器处理潜在变量的能力。
接下来看编码器与损失。作者表示,在训练阶段或 KV 缓存预填充过程中,张量 Z 是与编码器一起采样得到的。
Free Transformer 拥有一个专属于编码器的 Transformer 模块,并且该模块是非因果的,使得整个编码器也是非因果结构。这一点是必要的,因为解码器的条件约束可能产生长程影响,需要考虑完整的序列信息,才能获得潜在变量的合理条件分布。
在这个编码器专用模块中,查询的输入来自一个经过训练的、可学习的常数 token 嵌入 ζ,它会被复制以匹配序列长度;而键和值的输入则来自解码器前半部分的输出。之所以使用这种可学习的常数嵌入作为查询输入,而不是输入序列的标准表示,是为了防止编码器学习到逐 token 的映射关系,使其能够捕捉到序列的全局特征,从而更具跨任务和跨数据集的可迁移性。
最终,通过一个线性读出层,从编码器模块的输出中为每个 token 计算出一个维度为 H = 16 的向量。
最后是二进制映射器。
编码器的最后一个线性层会针对正在处理的序列中每一个位置 t,计算出一个向量 L_t = (L_t,1, …, L_t,H) ∈ ℝ^H,其各个分量被解释为二进制编码中每一位的 logits。
二进制映射器会独立地对这些比特 B_t,1, …, B_t,H 进行采样(方式如下):

并根据采样结果输出一个维数为 2^H 的独热向量 Y_t,用以表示对应的二进制取值。
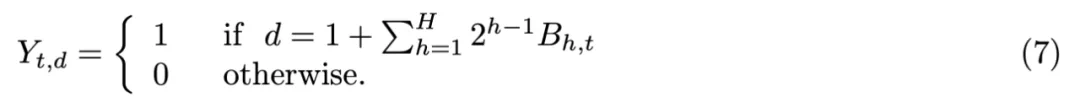
实验结果
合成数据集
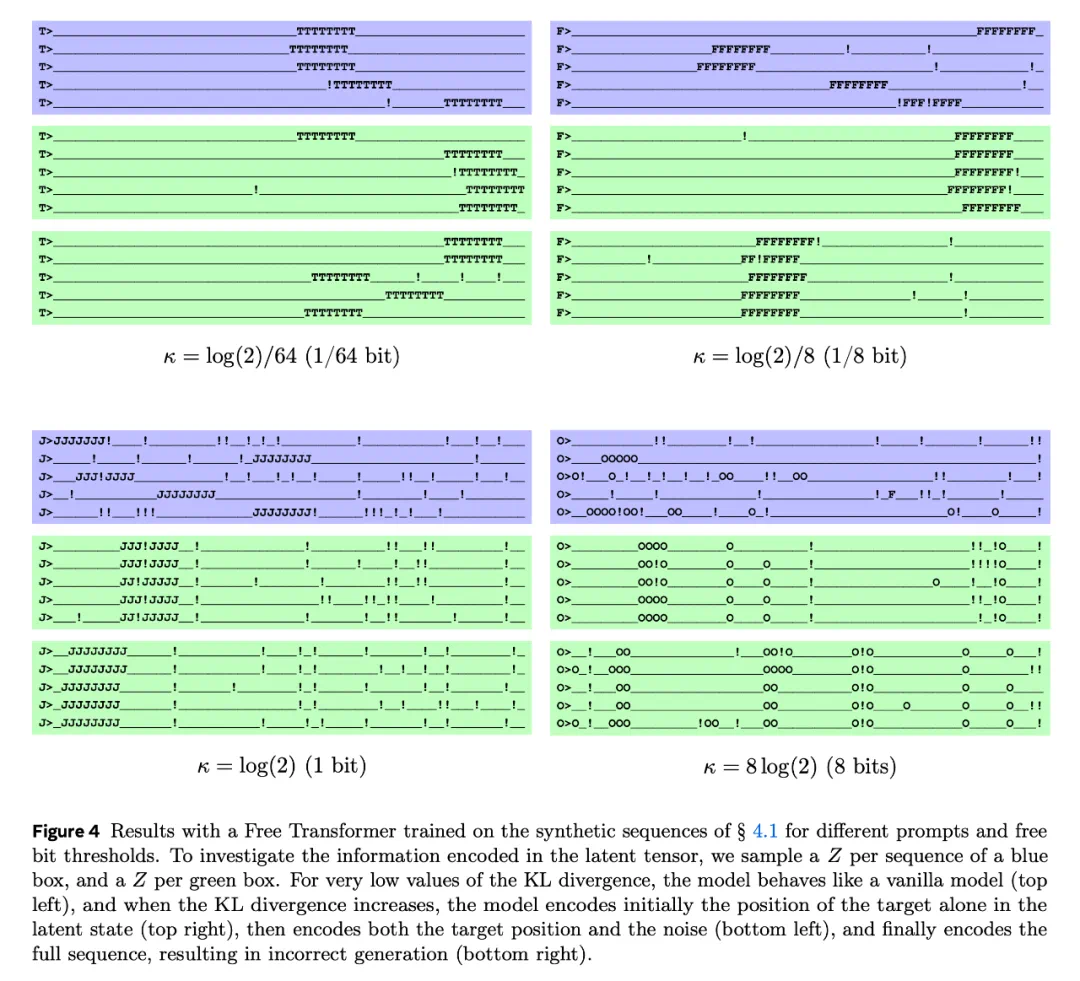
为了验证 Free Transformer 确实利用潜变量 Z 来对其生成过程进行条件化,本文设计了一个合成数据集,在合成训练集中,作者对每个序列的生成方式进行了规定,如以 1/16 的概率将任意字符替换为感叹号!。图 3 为一些示例。

接着,作者在该数据上训练了四个不同 free bits 阈值 κ 的 Free Transformer 模型,并使用相同的随机提示词生成了三组序列,如图 4 所示。
对于每个模型:蓝色组中,每个序列的噪声 Z 都是独立采样的;绿色组中,只为整组序列采样一个相同的 Z,并使用它生成全部序列。
当 KL 散度的值非常低时,模型的表现类似于普通 Transformer(见图 4 左中)。随着该值的增加,模型首先仅在潜在状态中编码目标的位置(图 4 右中);进一步增大时,模型开始同时编码目标位置和噪声(图 4 左下);当值再度升高时,模型会将整个序列都编码进潜在状态,从而导致生成结果出错(图 4 右下)。
为了在标准基准测试上评估性能,作者使用了仅解码器 Transformer。这些模型经过高度优化,采用了以下关键技术:如 SwiGLU 非线性激活函数;旋转位置嵌入等。
下游任务的性能结果如表 1(针对 15 亿参数模型)和表 2(针对 80 亿参数模型)所示,两组结果均基于四种不同的 κ 值。
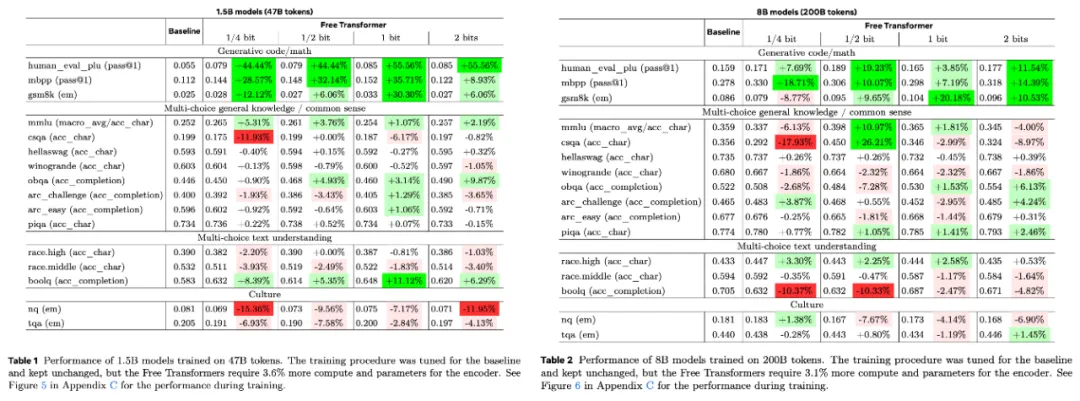
从结果可以看到,模型在 HumanEval+、MBPP 和 GSM8K 等任务上取得了显著提升 —— 这些任务普遍被认为需要一定的推理能力。
此外,在 MMLU 和 CSQA(多选题任务)上,8B 模型在 KL 散度为 0.5 比特时也表现出明显改进。
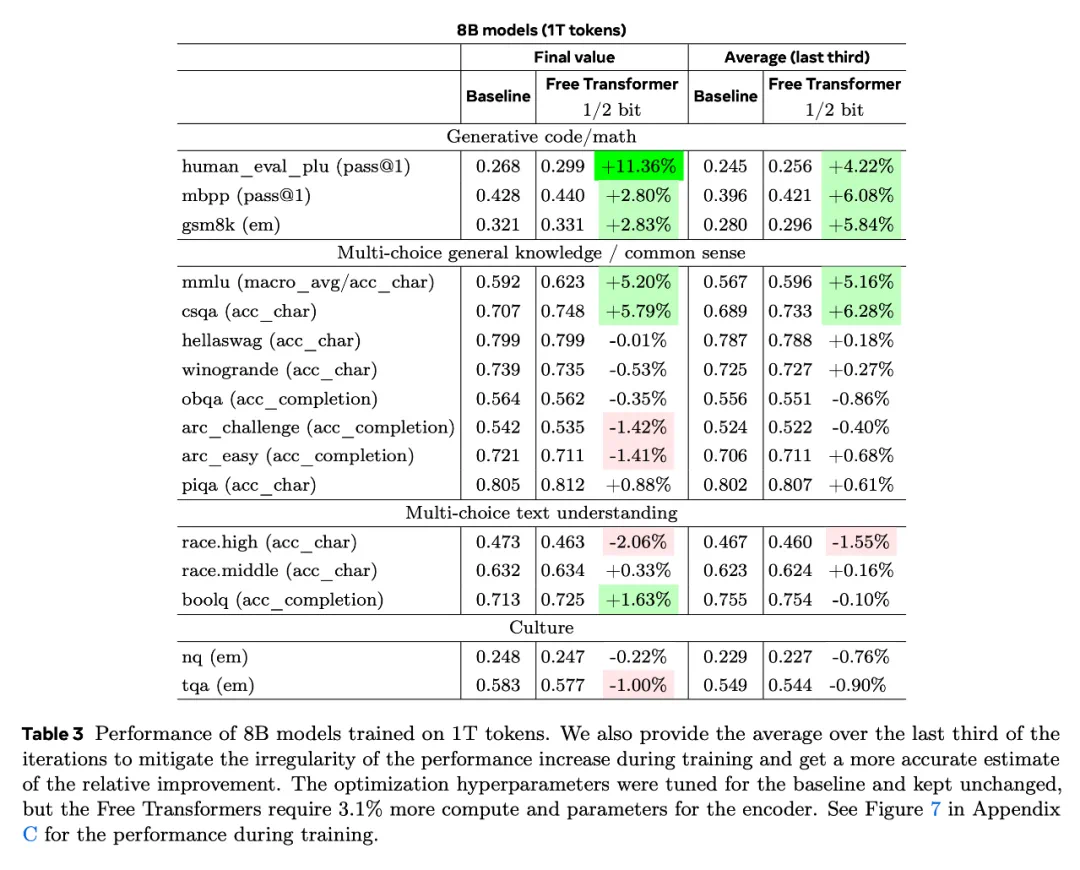
为了在更贴近真实应用场景的条件下评估模型改进效果,作者使用 1 万亿(1T)tokens 训练了 80 亿参数(8B)模型。这种大规模训练显著提升了基线模型和 Free Transformer 的性能。
下游任务的性能结果列于表 3。
训练过程中的对应曲线可见图 7。
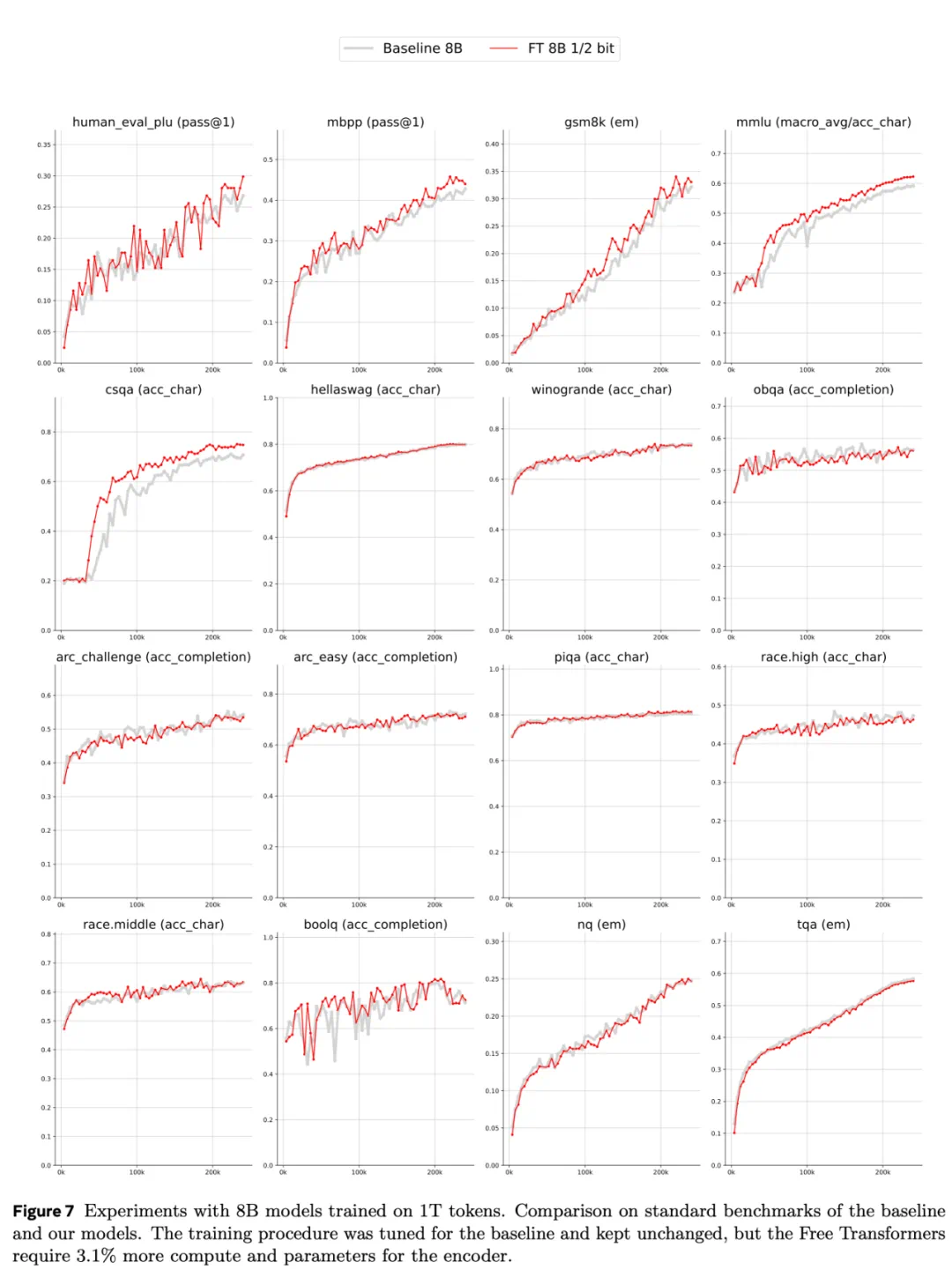
从图中可以观察到,在这一阶段模型的性能提升速率基本保持稳定,因此取平均值有助于减轻训练波动带来的影响。
最关键的结果是:模型在 HumanEval+、MBPP、GSM8K、MMLU 和 CSQA 等任务上的性能均获得显著提升,验证了在小规模实验中观察到的趋势,同时在其他任务上也表现出更高的稳定性。