
当今的 AI 智能体(Agent)越来越强大,尤其是像 VLM(视觉-语言模型)这样能「看懂」世界的智能体。但研究者发现一个大问题:相比于只处理文本的 LLM 智能体,VLM 智能体在面对复杂的视觉任务时,常常表现得像一个「莽撞的执行者」,而不是一个「深思熟虑的思考者」。
它们为什么会这样?因为它们感知世界的方式从简单的文本变成了复杂的视觉观察。它们拿到的信息往往是片面和嘈杂的(比如只能看到房间的一个角落)。这在学术上被称为「部分可观测马尔可夫决策过程」(POMDP)。
简单来说,智能体就像通过一个钥匙孔观察世界,它必须根据看到的有限信息,去猜测(构建)整个房间的全貌。这个「猜测」的能力,就是「世界模型」(World Model)。
我们不禁要问:我们能否通过强化学习(RL),教会 VLM 智能体在行动前,先在「脑中」显式地构建一个内部世界模型呢?
这就是美国西北大学(Manling Li 团队)、华盛顿大学(Ranjay Krishna)和斯坦福大学(李飞飞、吴佳俊、Yejin Choi 团队)等机构的联合研究成果 VAGEN 的核心。
论文共一作者王子涵的推文
具体而言,他们提出了一个创新的强化学习(RL)框架,不再仅仅奖励「正确的最终行动」,而是转而奖励「正确的思考过程」。
论文标题:VAGEN: Reinforcing World Model Reasoning for Multi-Turn VLM Agents
论文地址:https://arxiv.org/abs/2510.16907
项目页面:https://vagen-ai.github.io
核心思想:奖励「三思而后行」的思考过程

VAGEN 不再让 VLM 凭感觉直接输出动作(如「向左转」),而是强制它遵循一个结构化的「思考模板」,这个模板包含了构建世界模型的两个核心步骤:
StateEstimation (观现状):「我看到了什么?当前的状态是什么?」
TransitionModeling (预后路):「如果我这么做了,接下来会发生什么?」
如下图所示,智能体的「内心戏」(Agent Internal Belief)被分成了三部分:
<observation> (观测): 描述它所看到的当前状态事实 。
<reasoning> (推理): 基于观测,它计划要采取的行动 。
<prediction> (预测): 预测它执行动作后,世界将变成什么样子 。
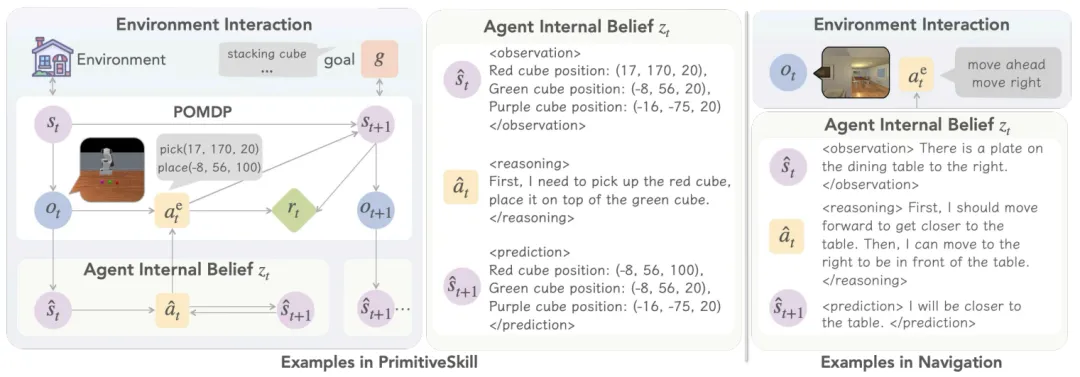 图 1:VAGEN 框架的核心循环 。智能体在行动前,必须先在内部信念 (Agent Internal Belief) 中明确地进行状态估计 (observation) 和状态预测 (prediction) 。
图 1:VAGEN 框架的核心循环 。智能体在行动前,必须先在内部信念 (Agent Internal Belief) 中明确地进行状态估计 (observation) 和状态预测 (prediction) 。
VAGEN 通过强化学习(RL)来奖励这种结构化的思考过程 。实验证明,这种 「WorldModeling」(即「现状+预后路」)的思考策略,远胜于「不思考」(NoThink)或 「自由思考」(FreeThink)的智能体 。
发现 1:「内心独白」用什么语言最好?
既然要智能体「思考」,那么它的「内心独白」(internal monologue)应该用什么格式来表达呢?研究者测试了三种不同的表示方法 :
自然语言 (Natural Language):例如,「红方块在绿方块的上面。」
结构化 (Structured):例如:{red_cube: [10, 20, 50], green_cube: [10, 20, 20]} 这样的坐标。
符号 (Symbolic): 例如:用特殊字符表示的地图网格。
该团队的发现是:最佳表示方法取决于任务的性质 。
对于通用任务(如 Sokoban 推箱子),自然语言表现最好 。
对于高精度操控任务(如 PrimitiveSkill 机械臂抓取),结构化格式(提供精确坐标)是必不可少的 。
 图 2:VAGEN 的实验环境涵盖了从 2D 网格(a, b)到 3D 导航(c)、机械臂操控(d)和 SVG 重建(e)等多种任务。
图 2:VAGEN 的实验环境涵盖了从 2D 网格(a, b)到 3D 导航(c)、机械臂操控(d)和 SVG 重建(e)等多种任务。
发现 2:如何高效奖励「好思考」?VAGEN-Full 方案
传统的 RL 奖励太稀疏了 —— 智能体可能要在一个任务(比如推箱子)中摸索几十步,最后才知道自己是成功还是失败 。这对训练「思考过程」是极其低效的 。
为了解决这个问题,VAGEN 引入了两个关键组件,构成了 VAGEN-Full 框架 :
1. 世界模型奖励 (WorldModeling Reward)
不再等到任务结束才给奖励,而是在智能体的每一步思考后都进行即时评估 。
研究者引入了一个「LLM-as-a-Judge」。在每一轮,这个「法官」会读取智能体的 <observation>(现状)和 <prediction>(预测),并将它们与环境的「真实状态」(Ground Truth)进行比较 。
如果智能体对当前状态的描述是准确的(例如,「红方块在 (10, 20)」),给个奖!
如果智能体对下一步的预测是准确的(例如,「红方块将移动到 (15, 20)」),再给个奖!
这样一来,智能体就能在「思考」的当下立刻获得反馈,极大地提高了学习效率 。
2. 双层优势估计 (Bi-Level GAE)
有了「思考奖励」还不够,还需要解决「奖励分配」问题 。
传统的 RL 方法(Token-Level GAE)试图估计智能体生成的每一个词的好坏,这非常混乱且不稳定 。
研究者提出的 Bi-Level GAE(双层 GAE) 更加高效 。它将信用分配分为两步:
回合层 (Turn-level):首先,评估这一整个回合(包含观测、推理、预测和行动)的总体价值。这个「思考-行动」组合是好是坏?
词元层 (Token-level):然后,再将这个总体的「好/坏」评价,分配回产生这个思考的每一个词元(token)上 。
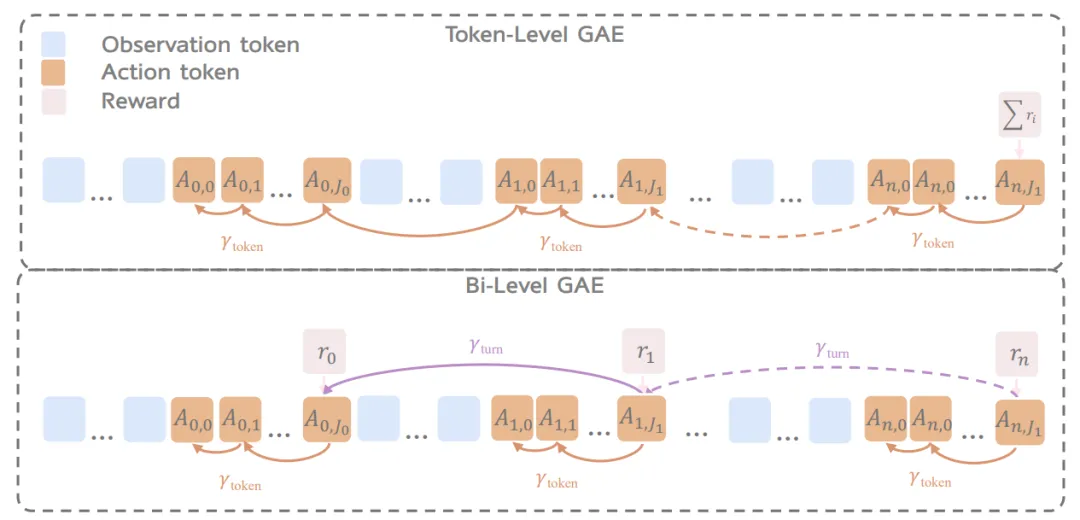 图 3:(上) 标准 Token-Level GAE 试图将稀疏的最终奖励(ΣR)分配给每一个 token,导致信号混乱 。(下) Bi-Level GAE 首先在回合层面(紫色箭头)分配奖励 (r0, r1...),然后再精细地分配到回合内的 token 上(橙色箭头),实现分层信用分配 。
图 3:(上) 标准 Token-Level GAE 试图将稀疏的最终奖励(ΣR)分配给每一个 token,导致信号混乱 。(下) Bi-Level GAE 首先在回合层面(紫色箭头)分配奖励 (r0, r1...),然后再精细地分配到回合内的 token 上(橙色箭头),实现分层信用分配 。
结果:3B 模型领先 GPT-5!
VAGEN 框架的效果非常惊人。研究者使用一个开源的 3B VLM(Qwen2.5-VL-3B) 作为基础模型进行训练。
结果显示, VAGEN-Full(3B) 模型在 5 个多样化智能体任务上的综合得分达到了 0.82 。
这是什么概念?
它远超未经训练的同一模型(0.21 )。
它超过了多款闭源大型模型,包括 GPT-5 (0.75)、Gemini 2.5 Pro (0.67) 和 Claude 4.5 (0.62) 。
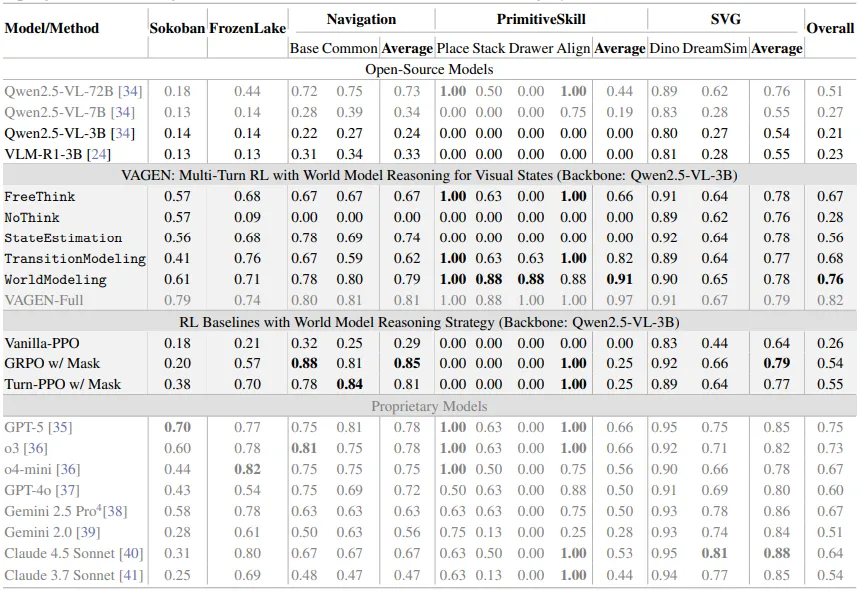 表 1:VAGEN 和其他模型与架构的性能对比。
表 1:VAGEN 和其他模型与架构的性能对比。
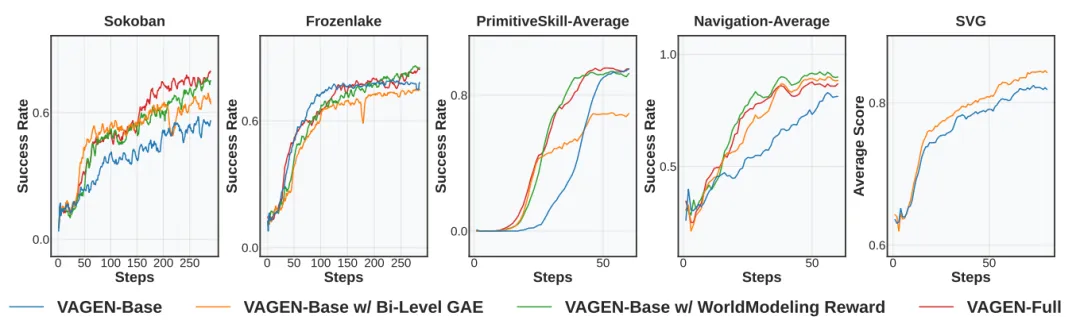 图 4:训练成功率曲线 。VAGEN-Full(橙色线)在 Sokoban、PrimitiveSkill 和 Navigation 等任务中,展现了比 VAGEN-Base(蓝线)更快、更稳定、更强的学习能力。
图 4:训练成功率曲线 。VAGEN-Full(橙色线)在 Sokoban、PrimitiveSkill 和 Navigation 等任务中,展现了比 VAGEN-Base(蓝线)更快、更稳定、更强的学习能力。
总结
VLM 智能体不应该只是被动响应的「执行器」。VAGEN 框架证明了,通过显式地强化智能体的内部世界模型推理(包括状态估计和转移建模),我们可以构建出更强大、更鲁棒、更具泛化能力的智能体 。
通过 WorldModeling Reward(LLM Judge)和 Bi-Level GAE(双层奖励分配),研究者为 VLM 智能体装上了一个「会思考的大脑」,让它们在看世界的视觉任务中,真正做到了「三思而后行」。


