在 AIGC 的下一个阶段,图像编辑(Image Editing)正逐渐取代一次性生成,成为检验多模态模型理解、生成与推理能力的关键场景。我们该如何科学、公正地评测这些图像编辑模型?
为了解决这一难题,来自得克萨斯大学奥斯汀分校、UCLA、微软等机构的研究者们共同提出了 EdiVal-Agent,一个以对象为中心的自动化、细粒度的多轮编辑(Multi-Turn Editing)评估框架。
EdiVal-Agent 的名字巧妙地融合了“Editing”(编辑)和“Evaluation”(评估),并以“Agent”(智能体)的形式呈现,寓意它是一个能够自主执行复杂评估任务的智能系统。它不仅能自动化生成多样化的编辑指令,还能从指令遵循,内容一致性,视觉质量多维度对编辑结果进行精细评估,其评估结果与人类判断的一致性显著优于现有方法。

论文题目:EdiVal-Agent: An Object-Centric Framework for Automated, Fine-Grained Evaluation of Multi-Turn Editing
论文链接:https://arxiv.org/abs/2509.13399
项目主页:https://tianyucodings.github.io/EdiVAL-page/
评测:如何定义“好”的编辑?
当前主流评测分为两类:
1、基于参考图像(Reference-based):依赖成对的参考图像,覆盖面有限,还容易继承旧模型的偏差。
2、基于大模型打分(VLM-based):用视觉语言模型(VLM)通过提示语打分,看似方便却问题重重:空间理解差,常误判物体位置与关系;细节不敏感,难察觉局部或微小修改;审美失准,对生成瑕疵(artifacts)缺乏感知。结果是,VLM 单评虽“方便”,却难以精确、可靠地衡量编辑质量。
EdiVal-Agent :图像编辑界的“评测裁判”
EdiVal-Agent 是一个面向对象的自动评测智能体。它能像人类一样,识别图像中的每个对象,理解编辑语义,并在多轮编辑中动态追踪变化。
在讲工作流之前,我们先来看一组直观的测试结果。
Base Image:两匹马
Turn 1: 添加文字 “HORSES”
Turn 2: 把棕色的马换成一只鹿
Turn 3: 把白马的毛色改成棕色
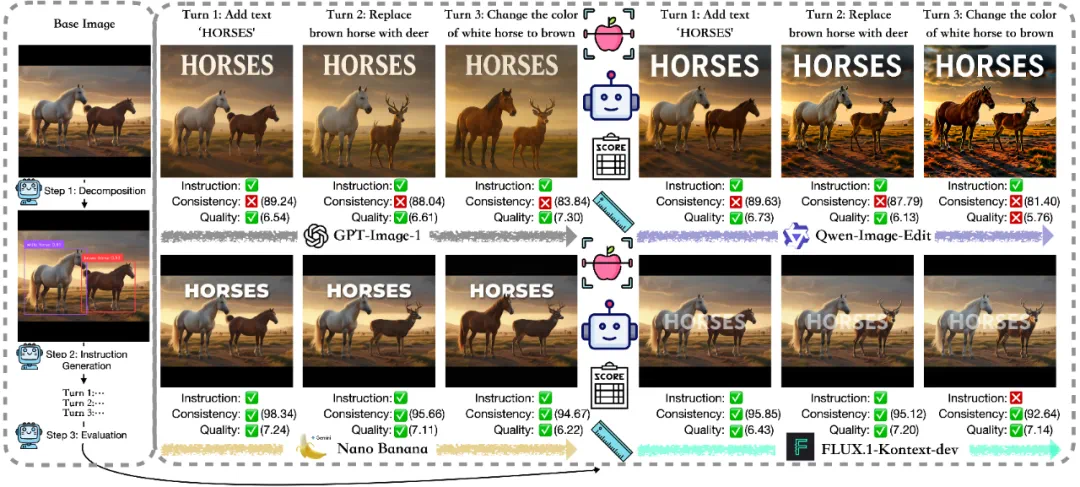
听起来很简单,对吧?但当我们让各家顶尖模型来完成这三步时,结果却大不相同。
GPT-Image-1(OpenAI) 指令执行得不错,但背景和细节越来越不一致。
Qwen-Image-Edit(阿里) 在视觉质量和一致性上双双失手,第三轮后出现明显“过曝感”。
FLUX.1-Kontext-dev(Black Forest Labs) 基本能保留背景,但理解指令有偏差,比如第三轮“白马的毛色改成棕色”执行失败。
Nano Banana(Google Gemini 2.5 Flash) 表现最平衡——稳、准、无明显短板。
在刚才的对比中,我们看到不同模型在多轮编辑下表现差异明显。那 EdiVal-Agent 是如何实现自动评测、做到“既懂图又懂语义”的呢?答案来自它精心设计的三步工作流。
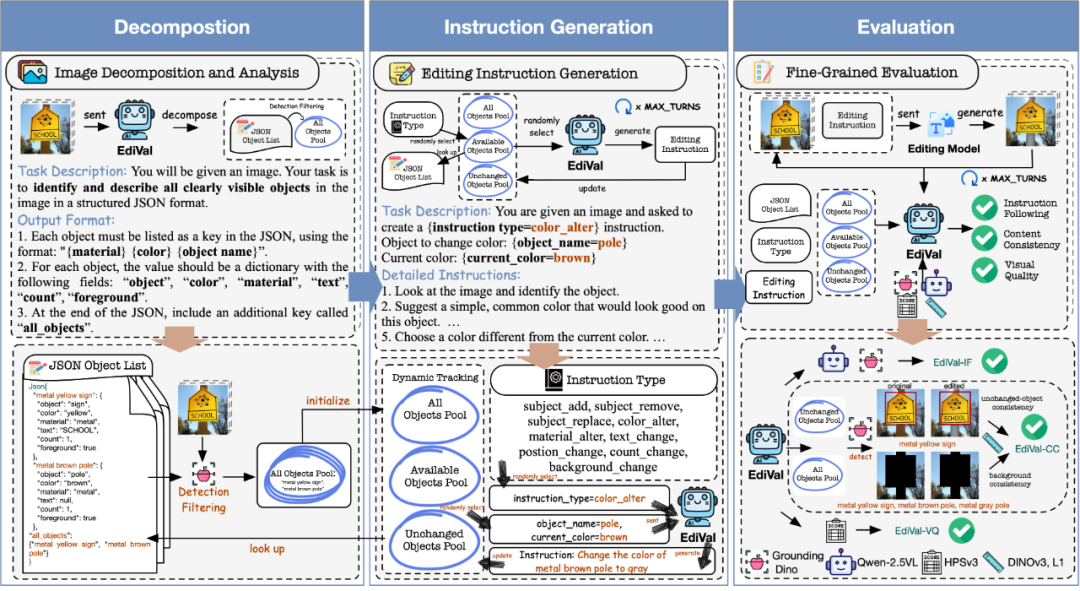
1、图像分解(Decomposition)
第一步,EdiVal-Agent 会让大模型(如 GPT-4o)先“看懂”一张图片。它会自动识别出图中所有可见对象,并为每个对象生成结构化的描述——包括 颜色 (color)、材质 (material)、物体上是否存在文字 (text)、数量 (count) 和前景属性 (foreground)。
这些对象被汇总成一个对象池(Object Pool),并通过物体检测器进行验证过滤,为后续指令生成和评测打下基础。
2、指令生成(Instruction Generation)
第二步,EdiVal-Agent 根据场景自动生成多轮编辑指令。 它拥有覆盖 9 种编辑类型、6 个语义类别 的指令体系,包括:
添加(add)、删除(remove)、替换(replace)、 改颜色(color alter)、改材质(material alter)、改文字(text change)、移动位置(position change)、改数量(count change)、换背景(background change)。
EdiVal-Agent 会动态维护三个对象池:
All Objects Pool(所有出现过的对象)
Available Objects Pool(当前可编辑的对象)
Unchanged Objects Pool(尚未被修改的对象)
在每一轮编辑中,智能体都会:
随机选取指令类型;
挑选合适对象;
生成自然语言编辑指令;
更新对象池状态。
默认设置为三轮(Turn 1 – Turn 3),也可以扩展到更长链条,实现更多轮可组合编辑。
3、 自动评测(Evaluation)
最后一步,EdiVal-Agent 从三个维度评估模型表现:
EdiVal-IF(Instruction Following) 判断模型是否准确执行指令——例如“把白马换成鹿”是否真的完成。 对于符号任务(如位置或数量变化),使用 Grounding-DINO 等开放词汇检测器进行几何验证; 对于语义任务(如颜色或背景变化),则结合物体检测器和VLM 进行语义核对。
EdiVal-CC(Content Consistency) 测量未被编辑的部分是否保持一致。 它计算背景区域(排除 All Objects Pool 中的所有物体)与未修改对象(属于 Unchanged Objects Pool 的物体)之间的语义相似度,以确保模型不会“误伤”无关区域。比如,下图中 GPT-Image-1 编辑后的 STOP 标志 发生了明显变化,而 Nano Banana 则更真实地保持了内容一致性。
EdiVal-VQ(Visual Quality) 使用 Human Preference Score v3 评估整体视觉质量,量化生成结果的美观度与自然度。
最终综合指标 EdiVal-O 通过几何平均融合 EdiVal-IF 和 EdiVal-CC,平衡“是否听话”与“是否稳定”。

为什么不把 EdiVal-VQ 纳入总体分数?
在评估中,我们发现“视觉质量(EdiVal-VQ)”虽然重要,但并不适合直接计入综合得分。以指令 “将背景换成图书馆” 为例:
GPT-Image-1 会倾向于“美化”图像,让整体更光亮、更清晰,从而提升审美得分。
FLUX.1-Kontext-max 则选择“保真”策略,尽量保持原始风格,只替换必要区域。

这说明不同模型在面对同一任务时,有的更追求视觉美感(beautification),有的更注重和保真(preservation)。由于在图像编辑中,是否应追求“美化”仍存在争议,因此我们未将 EdiVal-VQ 纳入最终评测指标。
EdiVal-Agent 的人类一致性验证
EdiVal-Agent评测结果能否“想法与人一致”?
我们设计了一项人类一致性实验(Human Agreement Study),来检验 EdiVal-Agent 的评测结果,是否真正符合人类判断。结果如下:
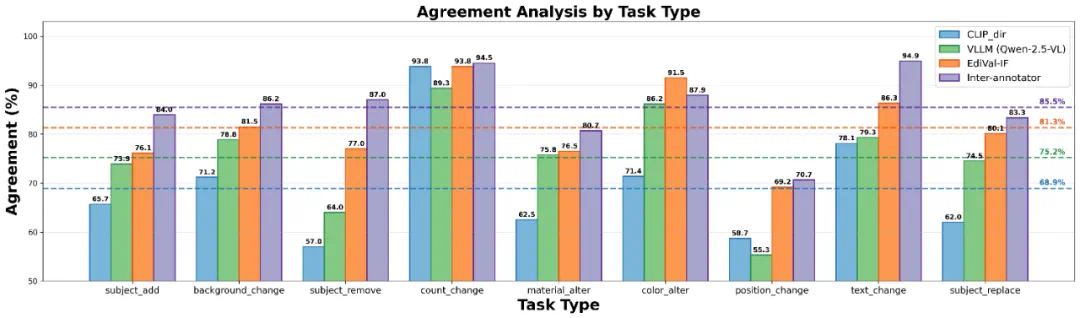
EdiVal-Agent 的指标 EdiVal-IF 与人类判断的平均一致率高达 81.3%。相比之下,传统评测方法的表现明显更低:
VLM-only(Qwen-2.5-VL):75.2%
CLIP-dir(CLIP-directional similarity):68.9%
换句话说,EdiVal-Agent 不仅能“算得对”,更能“想得像人”。此外,人工之间的一致率为 85.5%,这意味着——EdiVal-Agent 的表现已接近人类评测的上限。
为什么 EdiVal-IF 与人类判断更为一致?
符号任务更精准。对于 “添加 / 删除 / 替换 / 移动 / 改数量” 等符号(symbolic)任务,EdiVal-IF 使用 Grounding-DINO 精确检测目标是否真的出现、移动或消失,几乎没有歧义。相比之下,VLM 模型则容易受到 幻觉(Hallucination) 与 空间推理(Spatial Reasoning) 的限制。
语义任务更智能。 对于 “改颜色 / 改材质 / 改文字 / 换背景” 等语义(semantic)任务,EdiVal-IF 将 VLM(Qwen-2.5-VL) 与 对象检测(Object Detection) 相结合,先定位,再推理,让模型真正做到“对着图回答问题”。
结果表明,这种检测 + 推理融合的方式,比单纯让大模型“看图说话”更加稳定、可靠。
谁才是最强图像编辑模型?
在本文提出的多轮图像编辑 EdiVal-Bench 上,EdiVal-Agent系统对比了 13 个代表性模型,涵盖闭源与开源、in-context和context-free,Flow Matching与Diffusion等不同范式。结果如下:
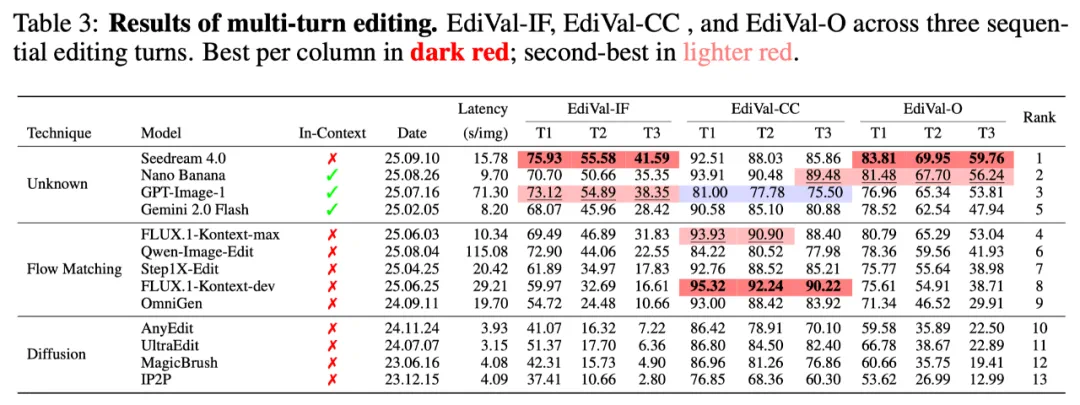
其中EdiVal-IF衡量的是模型指令遵循的能力,EdiVal-CC衡量的是模型内容一致性的能力。EdiVal-O是两者的几何平均值,为最终评分。可以看到:
🇨🇳 Seedream 4.0 在指令遵循能力上遥遥领先,并且在最终评分上全面超越国际闭源模型,排名第一;
Nano Banana 在速度(Latency)与质量上达成完美平衡,在内容一致性上尤为出色,排名第二;
GPT-Image-1 在指令遵循能力上出色,因追求美观(见上文)而牺牲一致性,位列第三;
Qwen-Image-Edit 出现典型“曝光偏差(exposure bias)”:在编辑次数变多时越改越偏,其在开源模型中排名第一,总排名第六。
评测结果也解释了为什么ChatGPT-4o在吉卜力风格迁移指令遵循和美化效果出圈,而Nano Banana在OOTD这些背景/物体一致性要求比较高的任务上出圈。
更多实验结果与详细分析(比如关于in-context和complex editing),欢迎阅读原文。
关于作者
论文作者成员来自UT-Austin, UCLA,Microsft GenAI 以及Lambda Inc,两位共同一作分别是陈天钰,张雅思。
陈天钰,得克萨斯大学奥斯汀分校(UT-Austin)统计系博士生(三年级),导师为周名远教授。硕士毕业于芝加哥大学,本科毕业于复旦大学统计系。研究方向涵盖生成模型、强化学习、因果推断与表示学习等,目前与 Microsoft GenAI 开展长期合作研究。
张雅思,加州大学洛杉矶分校(UCLA)统计与数据科学系博士生(四年级),师从吴英年教授与 Oscar Leong 教授。研究方向聚焦生成式人工智能、多模态学习、大模型后训练与计算机视觉,曾在 Amazon AWS AI Labs 与 Google Research 从事相关研究工作。
值得一提的是,两位共一本科均毕业于复旦大学。

陈天钰

张雅思