图像

反超Nano Banana!OpenAI旗舰图像生成模型上线
Jay 发自 凹非寺量子位 | 公众号 QbitAIOpenAI的红色预警,还在发力。 憋了大半年的图像生成模型——GPT-Image-1.5,终于发布。 官方表示,本次更新主要有四个亮点:更严谨的指令遵循;.

谷歌“蕉”傲登场!AI生图告别“走钟”时代
嘿,各位AI圈的朋友们,最近有没有被一个叫做“Nano Banana”的名字刷屏? 别误会,这可不是什么新型水果,而是谷歌在2025年8月底丢下的一枚重磅炸弹——正式名称为Gemini 2.5 Flash Image的AI图像生成与编辑模型。 说它是“炸弹”一点不为过,因为它似乎在悄悄地,或者说,是大张旗鼓地,改写着我们对AI生图的认知。

谷歌"香蕉"模型震撼发布!图像编辑能力一骑绝尘
最近有个感觉特别强烈:AI图像生成领域正在迎来一个全新的时代。 谷歌悄悄发布了代号为"Nano Banana"的Gemini 2.5 Flash Image模型,这个有着可爱名字的模型,可能要彻底改写图像编辑的游戏规则。 说实话,刚看到"香蕉"这个名字时,我还以为谷歌是在开玩笑。

AI疯狂进化6个月,一张天梯图全浓缩!30+模型混战,大神演讲爆火
半年之期已到,AI龙王归位! (AI卷成啥样了? )就在刚刚,AI圈大神Simon Willison在旧金山AI工程师世博会(AI Engineer World’s Fair)上带来爆笑又干货满满的主题演讲:「过去六个月中的LLM——由骑自行车的鹈鹕来解释」。

OpenAI Responses API新增MCP支持与多项功能升级,助力智能体开发
OpenAI宣布其核心API——Responses API现已支持**Model Context Protocol(MCP)**,并对图像生成、Code Interpreter以及文件搜索工具进行了重大更新。 这些升级极大简化了智能体开发流程,使开发者能够通过几行代码将AI智能体连接到外部工具和服务,进一步提升了API的灵活性和功能性。 MCP支持:简化智能体开发OpenAI通过Responses API新增对MCP的支持,标志着其在AI智能体开发领域的又一重大突破。

纯靠“脑补”图像,大模型推理准确率狂飙80%丨剑桥谷歌新研究
不再依赖语言,仅凭图像就能完成模型推理? 大模型又双叒叕迎来新SOTA! 当你和大模型一起玩超级玛丽时,复杂环境下你会根据画面在脑海里自动规划步骤,但LLMs还需要先转成文字攻略一格格按照指令移动,效率又低、信息也可能会丢失,那难道就没有一个可以跳过“语言中介”的方法吗?

谷歌Imagen 4与Imagen 4 Fast亮相GCP Vertex配额菜单,AI图像生成迈向新高度
谷歌云平台(GCP)Vertex AI的配额下拉菜单中新增了Imagen4和Imagen4Fast选项,预示着这两款下一代AI图像生成模型即将迎来更广泛的推广。 继Imagen3的成功后,Imagen4系列以更强大的多模态生成能力和低延迟特性,为开发者与企业用户带来了前所未有的视觉创作体验。 AIbase综合最新社交媒体动态,深入解析Imagen4的技术亮点及其对AI图像生成领域的深远影响。
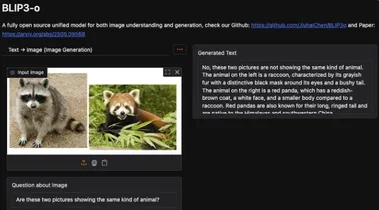
Salesforce BLIP3-o重磅登陆Hugging Face!全开源多模态模型,图像理解与生成一统江湖!
Salesforce AI Research在Hugging Face平台正式发布BLIP3-o应用,这款全开源的统一多模态模型家族以其卓越的图像理解与生成能力引发业界热议。 BLIP3-o通过创新的扩散变换器架构,结合语义丰富的CLIP图像特征,不仅提升了训练效率,还显著优化了生成效果。 AIbase综合最新社交媒体动态,深入解析BLIP3-o的技术突破及其对AI生态的影响。
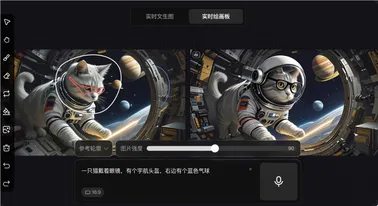
腾讯混元图像 2.0 发布:实时生图毫秒级速度与超写实画质
腾讯正式发布其最新的混元图像2.0模型(Hunyuan Image2.0),标志着 AI 图像生成技术迈入 “毫秒级” 响应时代。 新模型在速度上有了显著提升,相比于前代产品,混元图像2.0的参数量提高了一个数量级,结合了高效的图像编解码器和全新的扩散架构,能够在同类商业产品通常需要5到10秒的推理速度下,实现毫秒级的快速响应。 用户在生成图像时,可以一边输入文本或进行语音指令,一边获得实时图像输出,极大地改变了传统的 “抽卡 - 等待 - 抽卡” 模式,提升了用户的交互体验。

Manus推出图像生成Agent:从文字到视觉 AI任务执行新革命
人工智能领域的先锋企业Manus于宣布推出其全新图像生成Agent,进一步扩展其作为全球首个人工智能通用代理的强大功能。 这一创新工具不仅能够生成高质量图像,还能理解用户意图、规划解决方案,并结合多种工具完成复杂任务。 AIbase通过整合社交媒体最新动态及官方信息,为您深度解析这一技术突破的意义与潜力。

逆天改命!Flow-GRPO 让图像生成模型秒变 “大神”
家人们,今天必须给你们唠唠科研界的一项超酷新成果 ——Flow-GRPO!这东西可不得了,它就像是给图像生成模型打了一针 “超级进化剂”,直接让它们从 “青铜” 一路飙升到 “王者”。 想知道它是怎么做到的吗?快搬好小板凳,听我细细道来!图像生成模型的 “成长烦恼”现在的图像生成模型,比如基于流匹配(Flow matching)的那些,理论基础那叫一个扎实,生成的高质量图像也让人眼前一亮。 但它们也有自己的 “小烦恼”,遇到复杂场景,像要安排好多物体、处理各种属性和关系,或者是在图像里准确渲染文本的时候,就有点 “抓瞎” 了。
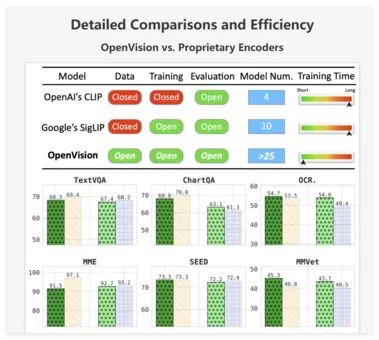
新一代开源视觉编码器 OpenVision 发布:超越 CLIP 与 SigLIP 的强大选择
加州大学圣克鲁兹分校近日宣布推出 OpenVision,这是一个全新的视觉编码器系列,旨在为 OpenAI 的 CLIP 和谷歌的 SigLIP 等模型提供替代方案。 OpenVision 的发布为开发者和企业带来了更多灵活性和选择,使得图像处理和理解变得更加高效。 什么是视觉编码器?视觉编码器是一种人工智能模型,它将视觉材料(通常是上传的静态图像)转化为可被其他非视觉模型(如大型语言模型)理解的数值数据。

颠覆传统ISP,Glass Imaging用AI“重塑摄影”:AR、手机、无人机市场全面瞄准
人工智能成像技术公司 Glass Imaging 宣布完成2000万美元A轮融资,由全球知名软件投资机构 Insight Partners 领投,GV(谷歌风投)、Future Ventures 和 Abstract Ventures 等老股东继续加码。 此轮融资将用于加速 GlassAI 技术的开发,并拓展其在智能手机、无人机、可穿戴设备等平台的应用。 Glass Imaging 总部位于加州洛斯阿尔托斯,致力于通过人工智能技术解决镜头像差、传感器缺陷和光学模糊等问题,以显著提升图像质量。

突破性技术MCA-Ctrl:中科院团队引领AI图像定制化新范式
中国科学院计算技术研究所研究团队近日推出的MCA-Ctrl技术在生成式AI领域引发广泛关注,这一文本到图像(T2I)新方法正为图像定制化市场带来革命性变革。 在个性化需求日益增长的当下,该技术通过独特的多方协同注意力控制机制,让用户无需繁琐的模型微调,即可根据文本或图像条件生成高度个性化的图像内容。 MCA-Ctrl最大的技术亮点在于其三大核心应用能力:主题替换、主题生成和主题添加。

苹果放大招!FastVLM 让视觉语言模型在 iPhone 上飞速 “狂飙”
苹果最近又搞了个大新闻,偷偷摸摸地发布了一个叫 FastVLM 的模型。 听名字可能有点懵,但简单来说,这玩意儿就是让你的 iPhone 瞬间拥有了“火眼金睛”,不仅能看懂图片里的各种复杂信息,还能像个段子手一样跟你“贫嘴”!而且最厉害的是,它速度快到飞起,苹果官方宣称,首次给你“贫嘴”的速度比之前的一些模型快了足足85倍!这简直是要逆天啊!视觉语言模型的 “成长烦恼”现在的视觉语言模型,就像个不断进化的小天才,能同时理解图像和文本信息。 它的应用可广了,从帮咱们理解图片里的内容,到辅助创作图文并茂的作品,都不在话下。

八秒极速生成!复杂场景图像定制低成本轻松驾驭,已开源丨字节北大联合发布
可控图片生成,如今已经不是什么新鲜事。 甚至也不需要复杂的提示词,用户通过简单的文本描述,就能快速生成符合个人需求的创意图像。 不过仍然有一些局限:比如说,虽然可以实现单一任务(如身份、主体、风格、背景等)的定制化设计,可是一旦条件增多,就会出现“鱼和熊掌不可兼得”的问题。

解锁笔记新维度:AI多模态技术让Obsidian图像管理效率暴增
在数字笔记的世界里,文字一直是主角,而图像却常常被冷落在角落。 作为一名AI方向研究生兼Obsidian重度用户,我深知这种不平衡的痛点。 当我们谈论知识管理时,往往只关注文本处理,却忽略了图像这一同样重要的信息载体。

Gemini2.0Flash图像生成升级:视觉质量大幅提升,文字更清晰
Google于近日宣布,旗下Gemini2.0Flash图像生成功能迎来重要升级,用户现可通过Google AI Studio体验最新模型:gemini-2.0-flash-preview-image-generation。 据介绍,本次升级带来三大核心改进:更高的视觉质量,相较于早期实验版本整体图像表现更自然、细节更丰富;文字渲染更精准,解决了AI生成图像中文字扭曲、不清晰等问题;内容安全机制优化,减少了不必要的生成内容拦截,提高生成效率与可用性。 此次更新体现了Google持续推动Gemini模型在多模态生成能力上的突破,也为AI创作者提供了更实用、更精确的图像生成工具。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI绘画
AI新词
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
智能体
技术
Gemini
英伟达
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
代码
AI for Science
苹果
腾讯
算法
Agent
Claude
芯片
Stable Diffusion
具身智能
xAI
蛋白质
开发者
人形机器人
生成式
神经网络
机器学习
AI视频
3D
RAG
大语言模型
字节跳动
Sora
百度
研究
GPU
生成
工具
华为
AGI
计算
AI设计
生成式AI
大型语言模型
搜索
视频生成
亚马逊
AI模型
特斯拉
DeepMind
场景
深度学习
Copilot
Transformer
架构
MCP
编程
视觉