图像

智谱开源文生图模型 CogView3-Plus,相关功能上线智谱清言 App
感谢智谱技术团队今天宣布开源文生图模型 CogView3 及 CogView3-Plus-3B ,该系列模型的能力已经上线“智谱清言”App。据介绍,CogView3 是一个基于级联扩散的 text2img 模型,其包含如下三个阶段:第一阶段:利用标准扩散过程生成 512x512 低分辨率的图像。第二阶段:利用中继扩散过程,执行 2 倍的超分辨率生成,从 512x512 输入生成 1024x1024 的图像。

AIGCRank:2024年9月出海AI网站流量排行榜
AI在线 发布 2024年9月全球和国内AI网站流量排行榜、全球AI网站增长率排行榜,并联合 哥飞的朋友们出海社群 发布出海AI网站流量排行榜!

阿里妈妈开源全新 AI 图像修复模型 FLUX-Controlnet-Inpainting
阿里妈妈创意团队宣布开源 FLUX-Controlnet-Inpainting AI 图像修复模型。该模型宣称结合了 FLUX.1-dev 和 ControlNet 的优势,能高质量修复图像。模型可以理解用户语言描述,并修复图像且支持改变风格,官方示例如下:FLUX-Controlnet-Inpainting 与 SDXL-Inpainting 相比,生成内容效果对比如下(输入图像 | 蒙版图像 | SDXL 修复 | 最终效果):FLUX-Controlnet-Inpainting 目前处于 Alpha 测试阶段

准确率87.6%,南农、国防科大、苏大等发布显微图像分类AI新方法
编辑 | 萝卜皮在医学显微图像分类(MIC)领域,基于 CNN 和 Transformer 的模型得到了广泛的研究。然而,CNN 在建模长距离依赖关系方面存在短板,限制了其充分利用图像中语义信息的能力。相反,Transformer 受到二次计算复杂性的制约。为了解决这些挑战,南京农业大学、国防科技大学、湘潭大学、南京邮电大学、苏州大学组成的联合研究团队提出了一个基于 Mamba 架构的模型:Microscopic-Mamba。具体来说,该团队设计了部分选择前馈网络(PSFFN)来取代视觉状态空间模块(VSSM)的最

阿里提出结构保持的AI视觉算法:显著提升HDR图像转LDR图像质量
9月21日,记者在2024云栖大会上获悉,阿里巴巴达摩院计算技术实验室提出了一种基于结构保持网络的AI视觉算法,可将高动态范围(HDR)场景图像自动转换为低动态范围(LDR)图像并保持其纹理细节,在常规显示设备上的图像质量相比业界提升7%。HDR图像同时包含强光源照射下的极亮区域和阴影、逆光下的极暗区域,容易出现明亮区域过曝、或者黑暗区域纯黑的情况,必须经过宽动态技术处理才能适配常规显示设备。传统的宽动态技术由于缺失自适应的局部与全局处理方法,会损失大量信息,生成结果局部粗糙或者全局锐化。业界也在探索基于AI的宽动

文生图 AI Midjourney 雄心:7.0 版未来 1-2 月登场、开发新图像编辑器、探索 3D 系统、踏足硬件领域
科技媒体 The Decoder 昨日(9 月 12 日)发布博文,报道称在最近的“Office Hours”活动中,Midjourney 创始人兼首席执行官 David Holz 在 Discord 分享了当前项目的最新进展,并回答了社区的提问。Midjourney 7.0 版本Holz 更新了 Midjourney 7.0 版本时间表,表示将会在未来 1-2 月内发布。让更多人体验 MidjourneyHolz 表示公司并不急于推出新的 AI 模型,而是提高现有技术的易用性,让工具深入融入到专业人士的日常工作中

阿里通义千问推出 Qwen2-VL:开源 2B / 7B 模型,处理任意分辨率图像无需分割成块
通义千问团队今天对 Qwen-VL 模型进行更新,推出 Qwen2-VL。Qwen2-VL 的一项关键架构改进是实现了动态分辨率支持(Naive Dynamic Resolution support)。与上一代模型 Qwen-VL 不同,Qwen2-VL 可以处理任意分辨率的图像,而无需将其分割成块,从而确保模型输入与图像固有信息之间的一致性。这种方法更接近地模仿人类的视觉感知,使模型能够处理任何清晰度或大小的图像。另一个关键架构增强是 Multimodal Rotary Position Embedding(M-

谷歌将重新开放 Gemini 生成人物图像功能,此前因“种族描述不当”引争议
感谢北京时间 29(今)日,据彭博社报道,谷歌宣布将恢复 AI 模型 Gemini 生成人物图像的功能,部分消费者将可以重新使用。谷歌表示,将开始向订阅 Gemini Advanced 套餐的英语用户推出生成人物图像功能。企业也将能够使用该工具,该功能将在未来几天内上线。谷歌产品管理高级总监戴夫・西特伦(Dave Citron)表示,该公司在通过 Imagen 3 生成人物描写方面取得了“重大进展”。“我们一直在努力对产品进行技术改进,并改进了评估集、红队练习和明确的产品原则。当然,Gemini 创建的每张图像都不

Freepik Mystic 发布,号称目前最先进的 AI 图像生成器
Magnific AI 和 Freepik 今日联合推出了 Freepik Mystic,宣称是目前最先进的 AI 图像生成器,也是唯一可以直接生成全高清图像的 AI 图像生成器。与 Midjourney 和 OpenAI 的 Dall-E 不同,Mystic 并非基础模型,而是一个结合 Flux 基础模型、微调、高分辨率图像生成技术和参数调整的流程。Mystic 能够生成高质量的图像,包括写实肖像、动物、风景、奇幻场景、室内设计和建筑概念、像素艺术、游戏元素、表情包等多种类型的图像。这些图像由顶尖摄影师、数字艺术

防止黑客重建人脸,浙大 & 阿里推出人脸隐私保护新方案 FaceObfuscator
对人脸数据安全的担忧,有新解了!浙江大学与阿里安全部联手,推出了新的人脸隐私保护方案 FaceObfuscator。不法分子即使从数据库中获取到人脸特征,也无法使用各类重构攻击还原人脸数据、窃取人脸隐私。新型重构攻击,威胁人脸隐私人脸识别是一项基于人脸特征信息进行身份识别的生物识别技术,广泛应用于金融、安防与民生。在使用人脸识别系统前,首先需要录入人脸信息,这些人脸信息会以人脸特征的形式被保存在服务商的人脸数据库中用于之后的实时人脸识别与身份认证。▲ 主流的人脸识别架构然而,网络和数据安全保障机制的欠缺容易导致人脸

云知声推出山海多模态大模型:实时生成文本、音频和图像
云知声于 23 日宣布推出山海多模态大模型。通过整合跨模态信息,山海多模态大模型能够接收文本、音频、图像等多种形式作为输入,并实时生成文本、音频和图像的任意组合输出。▲ 云知声山海助手微信小程序AI在线获悉,山海多模态大模型有如下特点:实时秒回,自由插话:与现实对话中人类的响应时间相似;支持对话随时打断,用户可在对话中任意插话感知情绪,表达情绪:通过语音文本判断用户情绪,还能捕捉用户语音的语气、节奏和音调等微妙变化,感知对方情绪状态音色自由切换:根据用户的个性化需求,自由切换音色;学习用户的音色、风格,复刻用户声音

Meta 发布 Sapiens 视觉模型,让 AI 分析和理解图片 / 视频中人类动作
Meta Reality 实验室最新推出了名为 Sapiens 的 AI 视觉模型,适用于二维姿势预估、身体部位分割、深度估计和表面法线预测 4 种以人为中心的基本视觉任务。这些模型的参数数量各不相同,从 3 亿到 20 亿不等。它们采用视觉转换器架构,任务共享相同的编码器,而每个任务有不同的解码器头。二维姿势预估:这项任务包括检测和定位二维图像中人体的关键点。这些关键点通常与肘、膝和肩等关节相对应,有助于了解人的姿势和动作。身体部位分割:这项任务将图像分割成不同的身体部位,如头部、躯干、手臂和腿部。图像中的每个像

Meta 研发新方法:整合语言和扩散 AI 模型,降低计算量、提高运算效率、优化生成图像
Meta AI 公司最新推出了 Transfusion 新方法,可以结合语言模型和图像生成模型,将其整合到统一的 AI 系统中。AI在线援引团队介绍,Transfusion 结合了语言模型在处理文本等离散数据方面的优势,以及扩散模型在生成图像等连续数据方面的能力。Meta 解释说,目前的图像生成系统通常使用预先训练好的文本编码器来处理输入的提示词,然后将其与单独的扩散模型结合起来生成图像。许多多模态语言模型的工作原理与此类似,它们将预先训练好的文本模型与用于其他模态的专用编码器连接起来。不过 Transfusion

Meta 公司发布 Imagine Yourself:无需为特定对象微调的个性化图像生成 AI 模型
从社交媒体到虚拟现实,个性化图像生成因其在各种应用中的潜力而日益受到关注。传统方法通常需要针对每位用户进行大量调整,从而限制了效率和可扩展性,为此 Meta 公司创新提出了“Imagine Yourself” AI 模型。传统个性化图像生成方法挑战目前的个性化图像生成方法通常依赖于为每个用户调整模型,这种方法效率低下,而且缺乏通用性。虽然较新的方法试图在不进行调整的情况下实现个性化,但它们往往过度拟合,导致复制粘贴效应。Imagine Yourself 创新Imagine Yourself 模型不需要针对特定用户微

Midjourney 官宣网页版免费用,前谷歌大佬祭出 AI 生图 Ideogram 2.0
Midjourney 一度稳居 AI 生图的第一梯队,甚至是很多人心中的 Top1。但是 Ideogram 2.0 的发布,抢夺了 Midjourney 的荣光,不仅一举拉高了图像生成质量,还打起了价格战。曾经在 AI 图像生成领域无可匹敌的领导者 Midjourney,终于听劝了,上周五推出了网页版图像编辑器。新编辑器巧妙集成了重绘、缩放等核心功能。不仅提高了操作效率,而且使整体交互逻辑更加清晰,对于高频使用 Midjourney 的用户来说,绝对欣喜!今天,Midjourney 宣布,将升级后的新工具向所有人免
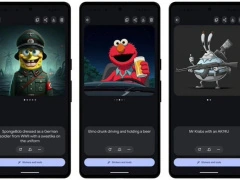
谷歌 Pixel 9 手机的 AI 图像生成工具“放飞自我”,或成“造假利器”
谷歌上周发布了 Pixel 9 系列智能手机,其中包含一系列以人工智能为核心的新功能。所有 Pixel 9 手机均支持 Gemini 人工智能,谷歌还加入了基于人工智能的图像生成和编辑工具。然而,评测人员测试了这些新功能后发现,人工智能图像生成很可能会成为谷歌的公关噩梦。据AI在线了解,谷歌为 Pixel 手机推出了一个名为 Pixel Studio 的人工智能图像生成应用,其能够通过文本提示创建贴纸和图像,功能与苹果计划推出的 Image Playground 非常相似。目前,评测人员能够使用 Pixel Stu

特朗普持枪火拼、哈里斯扮作小丑……发布不到一天的Grok 2,摊上大事了!
机器之能报道编辑:杨文Grok 2,你是懂如何背刺自家老板的。Grok 2 刚发布不到一天,就摊上事了。事情是这样的:昨天,马斯克旗下的 xAI 发布新一代大模型 Grok 2,并称已与初创公司 Black Forest Labs 展开合作,试验他们的 FLUX 模型。本来是强强联合的一件好事,但由于 FLUX 模型对于生成的图像没有严格的限制,导致 X 上充斥着大量让人瞠目结舌的图像。例如,扮作小丑的哈里斯开怀大笑:颇具喜感的特朗普持枪火拼:还有更离谱的,特朗普的枪口对准了一个黑人小男孩:要知道,现在正值美国大选

号称 Elo 评分“凌驾竞品”,Black Forest Labs 推出文生图 AI 模型 FLUX.1
美国初创公司黑森林实验室(BlackForestLabs)在 8 月 1 日推出了 AI 文生图模型 FLUX.1,该模型据称在“潜在扩散、稳定扩散及对抗性扩散蒸馏”方面较为突出,能够即时根据用户提示词生成各种图像。官方将该模型与其他友商产品进行比拼,结果显示系列模型的 Elo 评分(AI在线注:Elo 评分系统是一种在国际象棋等竞技游戏中广泛使用的评分方法,主要用于计算比赛对手实力等级)“凌驾” Stable Diffusion 3 Ultra、Ideogram、Midjourney 6.0、DALL・E 3 等
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI绘画
AI新词
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
智能体
技术
Gemini
英伟达
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
代码
AI for Science
苹果
腾讯
算法
Agent
Claude
芯片
Stable Diffusion
具身智能
xAI
蛋白质
开发者
人形机器人
生成式
神经网络
机器学习
AI视频
3D
RAG
大语言模型
字节跳动
Sora
百度
研究
GPU
生成
工具
华为
AGI
计算
AI设计
生成式AI
大型语言模型
搜索
视频生成
亚马逊
AI模型
特斯拉
DeepMind
场景
深度学习
Copilot
Transformer
架构
MCP
编程
视觉