图像

OpenAI 为 DALL-E 3 引入编辑功能:进一步精细化调整已生成图片
OpenAI 公司近日发布公告,宣布为 DALL-E 3 引入全新的编辑界面,在基于用户文本生成图片之后,可以继续根据用户描述精细化调整已生成的图片。DALL-E 编辑器提供两种主要编辑方法:基于选择区域的编辑:在 DALL-E 3 生成图片之后,用户可以选中已生成图片中的特定区域,然后再在聊天界面,输入提示词要求 DALL-E 3 进行微调。对话式编辑:在 DALL-E 3 生成图片之后,用户无需选择特定区域,在聊天窗口中直接描述自己的编辑内容,这种方法适用于编辑调整整个图像。OpenAI 表示通过引入该编辑器,

麻省理工学院携手 Adobe 演示 DMD AI 技术:每秒可生成 20 幅图像
主流文生图模型固然已经能生成非常逼真的图片,但通常渲染时间非常缓慢。麻省理工学院携手 Adobe 公司近日研发了 DMD 方法,在尽量不影响图像质量的情况下,加快图像生成速度。DMD 技术的全称是 Distribution Matching Distillation,将多步扩散模型简化为一步图像生成解决方案。团队表示:“我们的核心理念是训练两个扩散(diffusion)模型,不仅能预估目标真实分布(real distribution)的得分函数,还能估计假分布(fake distribution)的得分函数。”研究

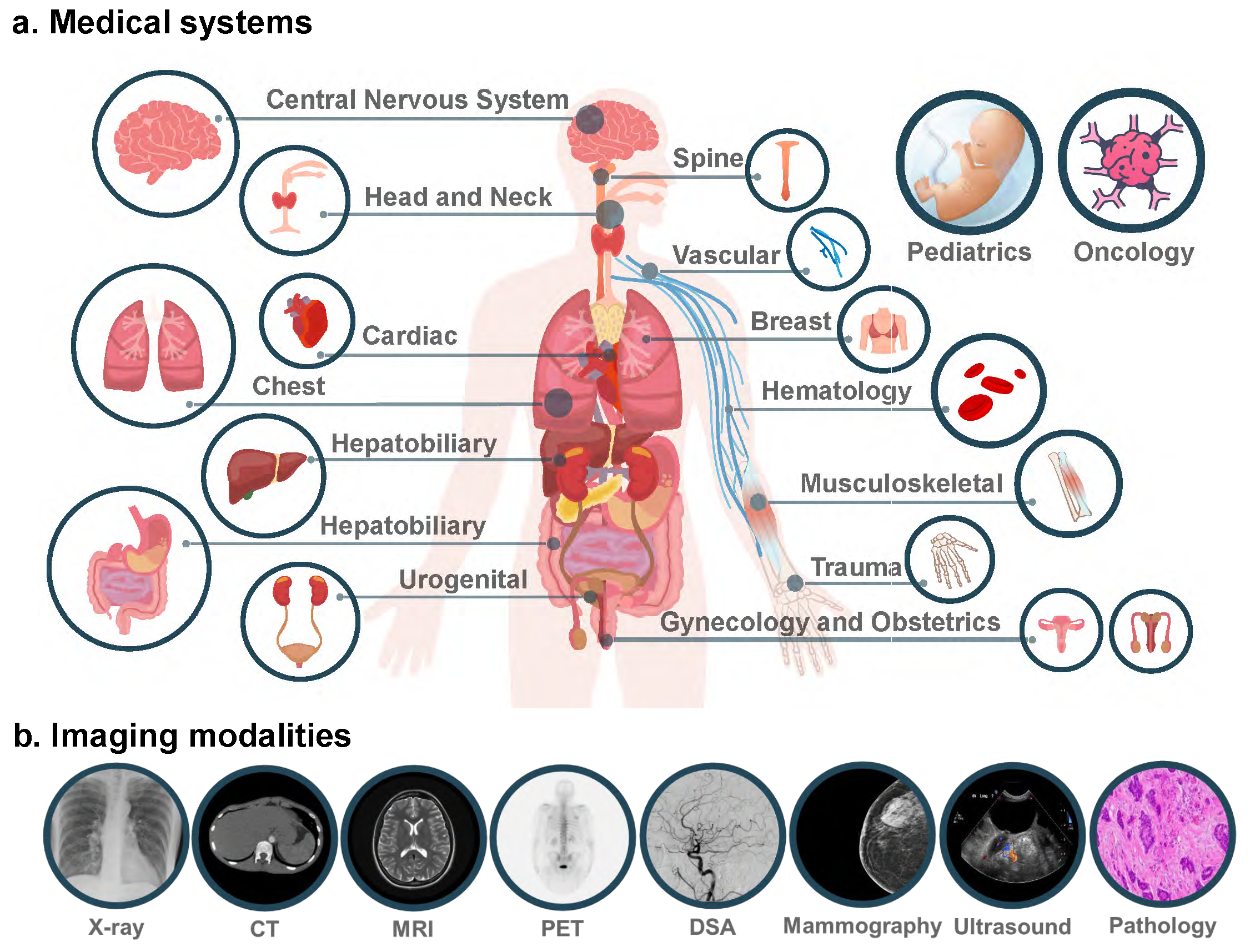
登Nature子刊,哈佛医学院发布迄今最大计算病理学基础模型,适用30+临床需求
编辑 | X基础模型有望为医学领域带来前所未有的进步。在计算病理学 (CPath) 中,基础模型在提高诊断准确性、预后以及预测治疗反应方面发挥着关键作用。近日,美国麻省总医院(Massachusetts General Hospital)、哈佛医学院等组成研究团队设计了迄今为止最大的两个 CPath 基础模型:UNI 和 CONCH。这些基础模型适用于 30 多种临床和诊断需求,包括疾病检测、疾病诊断、器官移植评估和罕见疾病分析。新模型克服了当前模型的局限性,不仅在研究人员测试的临床任务中表现良好,而且在识别新的、

无需提示词,Stability AI 演示 MindEye:目标想什么就能生成什么
AI 浪潮席卷而来,此前不少人认为“提示词工程师”会成为新兴工种,而 MindEye 的问世表明,这个岗位或许没有存在的价值了。此前不少人认为,未来 AI 时代并不在于某个模型是否强大,而是在于人类是否能够更高效利用这些 AI 模型,完成特定任务。这也诞生了“提示词工程师”概念,该工程师能够比普通人更能理解 AI,能够提出更准确的提示词,从而让 AI 满足其要求输出。而 StabilityAI 于 2023 年 7 月推出 MindEye1,近日再次推出了 MindEye2,让“提示词工程师”的价值大幅降低,该模型
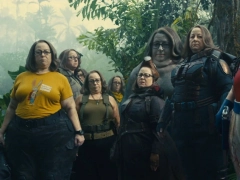
Midjourney 能让角色保持一致了!网友实测称直呼“改变游戏规则”
Midjourney 发布新功能,网友直呼“不可思议”!现在你可以让生成的图像几乎保持角色一致,belike:所有超级英雄长一个模样盯着你。甚至动漫风、写实风等跨风格生成也同样适用:保持同一风格,感觉配上文字可以讲一个故事了:面部、着装、发型可调控,换装玩法 get:新功能名为角色参照(Character Reference),和之前的风格参照类似,不过这次不是保持风格一致,而是保持生成图像的角色与给定的参照角色一致。网友们已经玩嗨了,纷纷表示这是迄今为止 Midjourney 最大的更新:还有网友认为生成式 AI

微软 Microsoft Designer 屏蔽特定提示词,避免 Copilot 生成不良价值导向图片
Microsoft Designer 是一款基于 Copilot / DALLE 3.0 的视觉设计应用,可以仅用几个提示词让 AI 为你生成所需图像,还能帮用户去除图片背景,生成个性化贴纸等。CNBC 发现,Microsoft Designer 在遇到一些特定的提示词时,例如“pro-choice”“four twenty” “pro-life”等,会生成一些涉及色情、暴力方面的不良图片,目前这些特定的提示词已经被微软禁用。注:pro life 与 pro choice 是伴随堕胎合法权而产生的一组词,可以理解为

阿里巴巴推出 AtomoVideo 高保真图生视频框架,兼容多种文生图模型
感谢阿里巴巴研究团队近日推出了 AtomoVideo 高保真图生视频(I2V,Image to Video)框架,旨在从静态图像生成高质量的视频内容,并与各种文生图(T2I)模型兼容。 ▲ 图源 AtomoVIdeo 团队论文IT之家总结 AtomoVideo 特性如下:高保真度:生成的视频与输入图像在细节与风格上保持高度一致性运动一致性:视频动作流畅,确保时间上的一致性,不会出现突兀的跳转视频帧预测:通过迭代预测后续帧的方式,支持长视频序列的生成兼容性:与现有的多种文生图(T2I)模型兼容高语义可控性:能够根据用

美图AI局部重绘技术大揭秘!想怎么改,就怎么改!美图局部重绘让你随心所欲
最近,靠着出其不意的扩图效果,“AI扩图”功能凭借搞笑的补全结果频频出圈,火爆全网。网友们踊跃尝试,180度的大反转也让网友们直呼离谱,话题热度高居不下。在带来欢笑和热度的背后,也代表人们在时刻关注着AI究竟能不能真正帮助他们解决实际问题,优化使用体验。但可以预见的是,随着AIGC技术的快速发展,正在加速推动AI应用场景落地,我们也将迎来一场全新的生产力变革。近日,美图公司旗下WHEE等产品上线AI扩图及AI改图功能,只需简单的提示性输入,用户就可以任意修改图像、移除画面元素、扩充画面,凭借便捷的操作与惊艳的效果,
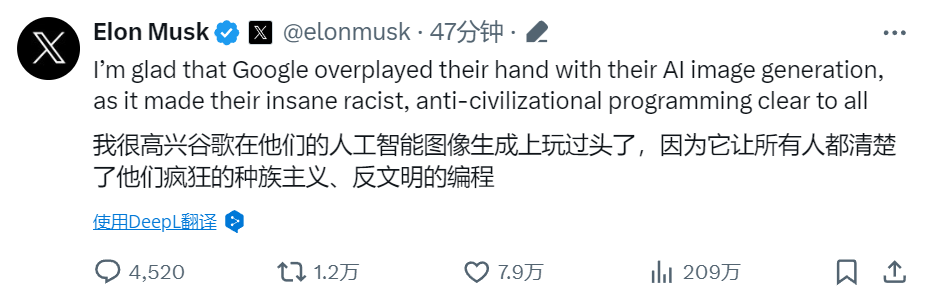
推出不到一个月,谷歌Gemini翻车了
机器之能报道编辑:Sia谷歌下架 Gemini 人物图像生成服务。三月前,谷歌 Gemini 轰轰烈烈亮相,被描述为谷歌“最大、最有能力和最通用”的 AI 系统,并补充说它具有复杂的推理和编码能力。2 月 8 日,谷歌聊天机器人 Bard 正式更名为 Gemini,以反映新聊天机器人的“使命”——提供对“最有能力的模型系列”的访问。结果,推出不到一个月,Gemini 就捅了个大篓子。用户使用人像生成服务时发现,让 Gemini 承认白人的存好像非常困难,AI 拒绝在图像中描绘白人,以至于生成不少违背基本事实(性别、
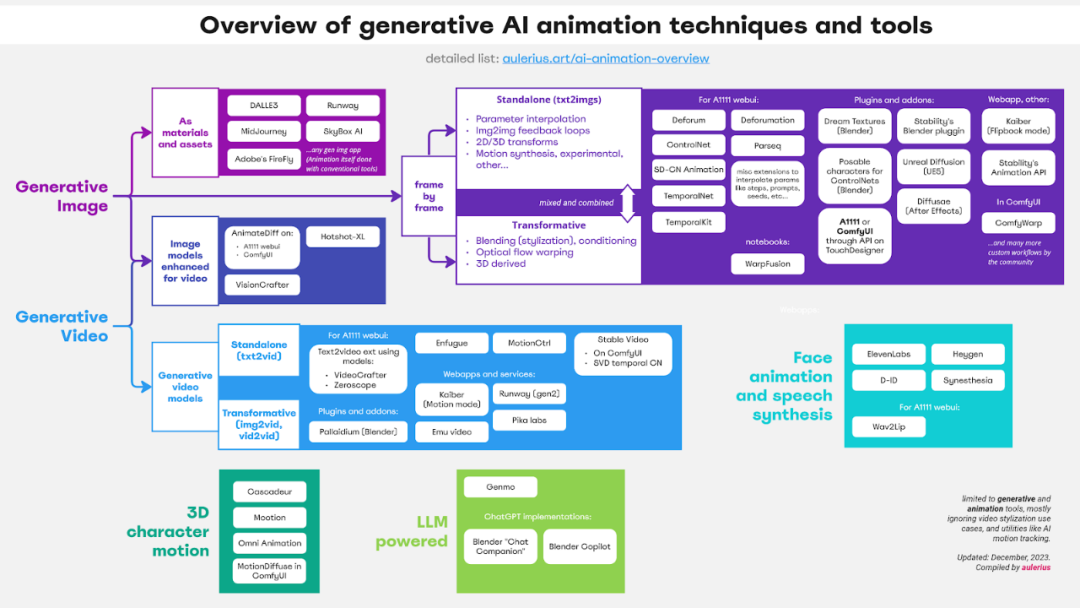
盘点如何用AI做动画,还有各种工具等你取用
图像生成、视频生成、整合语音合成的人脸动画、生成三维的人物运动以及 LLM 驱动的工具…… 一切都在这篇文章中。生成式 AI 已经成为互联网的一个重要内容来源,现在你能看到 AI 生成的文本、代码、音频、图像以及视频和动画。今天我们要介绍的文章来自立陶宛博主和动画师 aulerius,其中按层级介绍和分类了动画领域使用的生成式 AI 技术,包括简要介绍、示例、优缺点以及相关工具。他写道:「作为一位动画制作者,我希望一年前就有这样一份资源,那时候我只能在混乱的互联网上自行寻找可能性和不断出现的进展。」本文的目标读者是
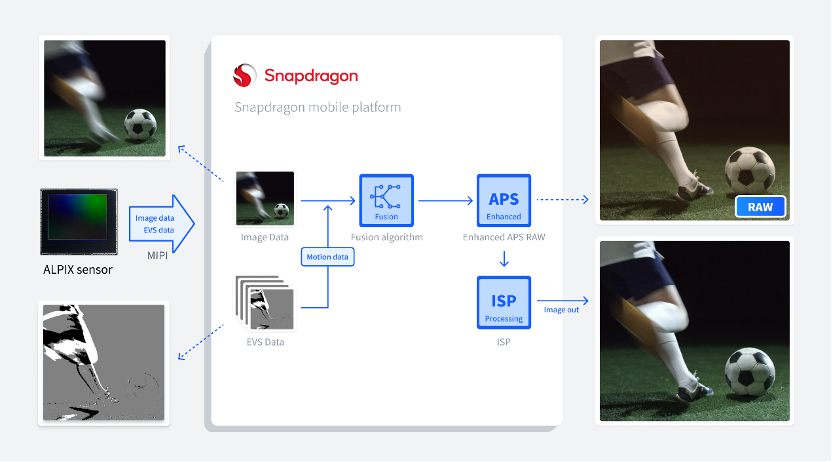
OPPO、锐思智芯、高通三方携手,共同推动智能手机影像AI Motion变革
2024年1月11日——OPPO,锐思智芯,高通近期发布,合作推动创新性融合视觉传感(Hybrid Vision Sensing,HVS®)技术在智能手机领域应用。通过HVS®传感器来更高效地提取运动信息和图像数据,从而帮助进一步改善拍照性能并实现影像的AI Motion功能。三方将合作开发一套完整方案,包括从Hybrid Vision Sensor获取原始视觉信息,传输至骁龙® 移动平台,并搭配专用算法。该合作方案将帮助实现智能手机影像创新功能,如拍照去模糊,超分辨率,和视频超慢动作重建等需要基于图像和运动信息结

超详细的 Stable Diffusion ComfyUI 基础教程(五):局部重绘+智能扩图
前言:我们上一节讲了图生图,也提到了“遮罩”这个节点;
我们想一下在使用 Web UI 进行局部重绘的时候都用到了那些功能?上期回顾:内容补充:
在开始之前我先给大家补充个知识点,怎么在图生图的时候批量出图“右键-新建节点- Latent-批处理-复制 Latent 批次”,把“复制 Latent 批次”节点串联在“VAE 编码”和“K 采样器”之间,然后设置次数就可以了。一、创建流程
①我们打开上节课“图生图”的流程图,我们可以看到“加载图像”节点是没有地方连接的,点住“遮罩”往外拉,松开然后选择“VAE 内补编

Nature | 一场人工智能革命正在医学领域酝酿,它会是什么样子?
编辑 | 绿萝10 月 24 日,《Nature》发布了一篇题为《An AI revolution is brewing in medicine. What will it look like?》的新闻专稿。文章指出 AI 模型应用于医疗的当前局限性,新兴的通才模型可以克服第一代机器学习工具在临床使用中的一些局限性。为了解决医学人工智能工具的一些局限性,研究人员一直在探索具有更广泛功能的医学人工智能。并介绍了一些大型科技公司在医疗成像的基础模型。Jordan Perchik 在美国阿拉巴马大学伯明翰分校(The U
178页!GPT-4V(ision)医疗领域首个全面案例测评:离临床应用与实际决策尚有距离
上海交大&上海AI Lab发布178页GPT-4V医疗案例测评,首次全面揭秘GPT-4V医疗领域视觉性能。

还记得让马斯克一键「穿越」的利器吗?现在面向所有人开放!免费!
机器之能报道编辑:吴昕还记得一周前我们介绍过的那个文生图工具吗?对,让马斯克「穿越」,变身古风大侠的那个。也是让 Blackpink Jennie 「变胖」的那个:当时, Ideogram 官宣成立并公开了测试版 v0.1 。机器之能赶紧排队注册,试用了一下。据说,短短一周内,积累了超过 90,000 名用户,生成了超过 300 万张图像!今天, Ideogram 进一步宣布向地球上的每个人开放 Ideogram !免费的,没有任何限制!(传送门 )官方博客也第一次介绍了 Ideogram v0.1 —— 「它是
解锁Midjourney隐藏技能:改改Prompt,四宫格就「裂变」了
我们离真正的「AI 电影」不远了?
全面开放,无需排队,Runway视频生成工具Gen-2开启免费试用
国内外其他公司也纷纷发力,把手里的技术封装成一个个人人可用的 AIGC 产品,Runway 前几个月发布的 Gen-1、Gen-2 便是其中之一。

苹果、俄勒冈州立提出AutoFocusFormer: 摆脱传统栅格,采用自适应下采样的图像分割
AFF 在小物体识别上向前再迈一步。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI绘画
AI新词
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
智能体
技术
Gemini
英伟达
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
代码
AI for Science
苹果
腾讯
算法
Agent
Claude
芯片
Stable Diffusion
具身智能
xAI
蛋白质
开发者
人形机器人
生成式
神经网络
机器学习
AI视频
3D
RAG
大语言模型
字节跳动
Sora
百度
研究
GPU
生成
工具
华为
AGI
计算
AI设计
生成式AI
大型语言模型
搜索
视频生成
亚马逊
AI模型
特斯拉
DeepMind
场景
深度学习
Copilot
Transformer
架构
MCP
编程
视觉