图像

UIUC提出InstructG2I:从多模态属性图合成图像,结合文本和图信息生成内容更丰富有趣!
今天给大家介绍的这项工作是伊利诺伊大学厄巴纳-香槟分校的研究者们提出的一个新任务 Graph2Image,其特点是通过调节图信息来合成图像,并引入了一种名为InstructG2I的新型图调节扩散模型来解决这个问题。 在INSTRUCTG2I的工作中,研究者们开发了一种新方法来生成图像,这种方法不仅依赖于文本描述,还考虑到图中其他相关信息。 想象一下,如果你要画一幅画,除了有一个简单的描述,比如“雪中的房子”,你还可以参考与这个房子相关的其他房子或景物的信息。

Retinex-Diffusion:让图像照明更加自然、细腻、富有层次感。
本文经AIGC Studio公众号授权转载,转载请联系出处。 这项研究主要是针对如何智能控制图像中的光照,采用了一种不需要重新训练模型的新方法。 简而言之,研究人员利用一种叫作Retinex理论的方法,先识别出图像中的光照元素,然后用这些元素来指导图像生成模型。

Adobe发布TurboEdit:可以通过文本来编辑图像,编辑时间<0.5秒!
今天给大家介绍Adobe研究院新的研究TurboEdit,可以通过文本来编辑图像,通过一句话就能改变图像中的头发颜色、衣服、帽子、围巾等等。 而且编辑飞快,0.5秒。 简直是图像编辑的利器。

北大开源全新图像压缩感知网络:参数量、推理时间大幅节省,性能显著提升 | 顶刊TPAMI
压缩感知(Compressed Sensing,CS)是一种信号降采样技术,可大幅节省图像获取成本,其核心思想是「无需完整记录图像信息,通过计算即可还原目标图像」。 CS的典型应用包括:降低相机成本:利用廉价设备就能拍摄出高质量图像;加速医疗成像:将核磁共振成像(MRI)时间从40分钟缩短至10分钟内,减少被检查者的不适;探索未知世界,助力科学研究:将「看不见」的事物变为「看得见」,如观测细胞活动等转瞬即逝的微观现象,以及通过分布式射电望远镜观测银河系中心的黑洞。 CS的两个核心问题是:如何设计采样矩阵,从而尽可能多地保留图像信息?

图像领域再次与LLM一拍即合!idea撞车OpenAI强化微调,西湖大学发布图像链CoT
OpenAI最近推出了在大语言模型LLM上的强化微调(Reinforcement Finetuning,ReFT),能够让模型利用CoT进行多步推理之后,通过强化学习让最终输出符合人类偏好。 无独有偶,齐国君教授领导的MAPLE实验室在OpenAI发布会一周前公布的工作中也发现了图像生成领域的主打方法扩散模型和流模型中也存在类似的过程:模型从高斯噪声开始的多步去噪过程也类似一个思维链,逐步「思考」怎样生成一张高质量图像,是一种图像生成领域的「图像链CoT」。 与OpenAI不谋而和的是,机器学习与感知(MAPLE)实验室认为强化学习微调方法同样可以用于优化多步去噪的图像生成过程,论文指出利用与人类奖励对齐的强化学习监督训练,能够让扩散模型和流匹配模型自适应地调整推理过程中噪声强度,用更少的步数生成高质量图像内容。

CCF-CV携手合合信息打造技术分享论坛,聚焦大模型时代中的视觉安全前沿热点
近期,《咬文嚼字》杂志发布了2024年度十大流行语,“智能向善”位列其中,过去一年时间里,深度伪造、AI诈骗等话题屡次登上热搜,AI技术“野蛮生长”引发公众担忧。 今年9月,全国网络安全标准化技术委员会发布了《人工智能安全治理框架》,指出人工智能既面临自身技术缺陷、不足带来的内生风险,也面临不当使用、滥用甚至恶意利用带来的外部风险。 为探寻AI安全治理道路,近期,由中国计算机学会计算机视觉专委会主办,合合信息承办,中国运筹学会数学与智能分会协办的《打造大模型时代的可信AI》论坛(简称“论坛”)顺利举行。

写给小白的大模型入门科普
什么是大模型? 大模型,英文名叫Large Model,大型模型。 早期的时候,也叫Foundation Model,基础模型。
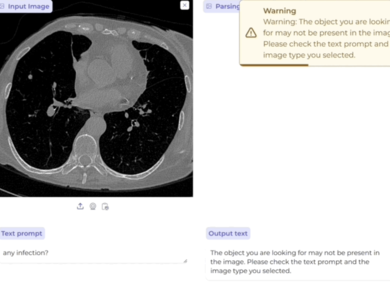
九大成像模式一键解析,生物医学图像AI再迎突破!微软、UW等BiomedParse登Nature子刊
作者 | BiomedParse团队编辑 | ScienceAI生物医学图像解析在癌症诊断、免疫治疗和疾病进展监测中至关重要。 然而,不同的成像模式(如MRI、CT和病理学)通常需要单独的模型,造成资源浪费和效率低下,未能充分利用模式间的共性知识。 微软团队最新发布的基础模型BiomedParse,开创性地通过文本驱动图像解析将九种成像模式整合于一个统一的模型中,通过联合预训练处理对象识别、检测与分割任务,实现了生物医学图像解析的新突破。

2024年10月出海AI网站流量排行榜
AI在线 发布 2024年10月全球和国内AI网站流量排行榜、全球AI网站增长率排行榜,并联合 哥飞的朋友们出海社群 发布出海AI网站流量排行榜!

智源推出全能视觉生成模型 OmniGen:支持文生图、图像编辑等
北京智源人工智能研究院(BAAI)推出了新的扩散模型架构 OmniGen,这是一种用于统一图像生成的多模态模型。 ▲ 文本生成图像,编辑生成图像的部分元素,根据生成图像的人体姿态生成重绘图像,从另一图像中提取所需对象与新图像融合官方表示,OmniGen 具有以下特点:统一性:OmniGen 天然地支持各种图像生成任务,例如文生图、图像编辑、主题驱动生成和视觉条件生成等。 此外,OmniGen 可以处理经典的计算机视觉任务,将其转换为图像生成任务。

图像伪造照妖镜:北大发布多模态 LLM 图像篡改检测定位框架 FakeShield
北京大学的研究人员开发了一种新型多模态框架 FakeShield,能够检测图像伪造、定位篡改区域,并提供基于像素和图像语义错误的合理解释,可以提高图像伪造检测的可解释性和泛化能力。 随着生成式人工智能(AIGC)的迅猛发展,图像编辑与合成技术变得愈加成熟与普及。 这一趋势为图像内容创作带来了便捷的同时,也显著增加了篡改检测的难度。

谷歌 Fluid 颠覆共识:两大因素被发现,AI 文生图领域自回归模型超越扩散模型
科技媒体 The Decoder 昨日(10 月 22 日)发布博文,报道称谷歌 DeepMind 团队携手麻省理工学院(MIT),推出了全新的“Fluid”模型,在规模达到 105 亿参数时候,能取得最佳的文生图效果。 目前在文生图领域,行业内的一个共识是自回归模型(Autoregressive Models)不如扩散模型(Diffusion Models)。 AI在线简要介绍下这两种模型:扩散模型 (Diffusion Models): 这是一种最近非常热门的内容生成技术,它模拟的是信号从噪声中逐渐恢复的过程。

AIGC时代如何打击图片造假诈骗?合合信息文档篡改检测有妙招
近日,第七届中国模式识别与计算机视觉大会(简称“PRCV 2024”)在乌鲁木齐举办。大会由中国自动化学会(CAA)、中国图象图形学学会(CSIG)、中国人工智能学会(CAAI)和中国计算机学会(CCF)联合主办,新疆大学承办。作为模式识别和计算机视觉领域学术盛会,PRCV 2024吸引了众多国内外科研工作者及行业从业者参与,分享最新理论研究进展和技术研发成果,促进产学研交流与合作。

Midjourney 下周上线新图像编辑器:让“二创”AI 图片变得更简单
首席执行官 David Holz 昨日在 Discord 平台宣布,将于下周为 Midjourney 推出全新的 AI 图像编辑器工具。用户上传图像后可展开包括放大、缩小、调整角度等多种操作,这些操作不再需要 Discord,只需简单命令即可完成;用户可以使用数字画笔进行修补,进行更精细的修改。此外该 AI 图像编辑器还可以基于上传图像的深度信息生成新图片,保留原始构图和内容不变的情况下,彻底改变纹理、颜色和细节。

智源发布原生多模态世界模型 Emu3,宣称实现图像、文本、视频大一统
感谢智源研究院今日发布原生多模态世界模型 Emu3。该模型只基于下一个 token 预测,无需扩散模型或组合方法,即可完成文本、图像、视频三种模态数据的理解和生成。官方宣称实现图像、文本、视频大一统。

RTX 4090 笔记本 0.37 秒直出大片:英伟达联手 MIT 清华祭出 Sana 架构,速度秒杀 FLUX
一台 4090 笔记本,秒生 1K 质量高清图。英伟达联合 MIT 清华团队提出的 Sana 架构,得益于核心架构创新,具备了惊人的图像生成速度,而且最高能实现 4k 分辨率。一台 16GB 的 4090 笔记本,仅需 0.37 秒,直接吐出 1024×1024 像素图片。

Adobe 推出多款 AI 工具:可构建 3D 场景、消除路人、清洁镜头
据 The Verge 今天凌晨报道,Adobe 近期展示了多款实验性的 AI 工具,可用于动画制作、图像生成、照片及视频的优化等领域,未来有望被整合到 Creative Cloud 中。Project Scenic:该工具可让用户在使用 Firefly 模型生成图像时拥有更大的控制权。其能够生成一个完整的 3D 场景,用户可以自由添加、移动、调整场景中的物体大小,最终结果会根据 3D 场景生成相应的 2D 图像。

微软探索音生图 AI 模型,实时视觉化会议演讲者语音讲述的场景
科技媒体 MSPoweruser 昨日(10 月 14 日)发布博文,报道称微软公司获得了一项新的专利,描述了基于用户实时输入的语音来生成图片。根据美国商标和专利局最新公示的清单,该专利共计 20 页,微软于 2023 年 4 月 5 日提交申请,于 10 月 10 日获批。根据专利描述,该系统可以在会议或讲座中实时捕捉音频,随后通过语言模型进行总结,并生成相应的 AI 图像。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI绘画
AI新词
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
智能体
技术
Gemini
英伟达
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
代码
AI for Science
苹果
腾讯
算法
Agent
Claude
芯片
Stable Diffusion
具身智能
xAI
蛋白质
开发者
人形机器人
生成式
神经网络
机器学习
AI视频
3D
RAG
大语言模型
字节跳动
Sora
百度
研究
GPU
生成
工具
华为
AGI
计算
AI设计
生成式AI
大型语言模型
搜索
视频生成
亚马逊
AI模型
特斯拉
DeepMind
场景
深度学习
Copilot
Transformer
架构
MCP
编程
视觉