图像

OpenAI 的新 GPT-4o 图像生成技术绝对会改变游戏规则
GPT-4o 的图像生成功能刚刚发布就直接开始摧毁传统行业,甚至让 OpenAI 的 CEO 山姆·奥特曼(Sam Altman)都直呼:“我也看不懂眼前发生的一切! ”图片传统的设计软件,比如 Photoshop,现在可真是如临大敌了。 一、图像融合的能力彻底超越传统工具 来看一个让人震惊的图像融合实例:图片传统的 Photoshop 顶多就是简单地将人物图层叠加到背景图上,对光影和角度的细节通常还要手动调整。

我下下决心再给老板发哈哈哈
编辑 | 萝卜皮原子结构的高分辨率可视化对于理解材料微观结构与宏观性质之间的关系具有重要意义。 然而,在原子分辨率显微镜中,快速、准确、稳健地自动解析复杂模式的方法仍然难以实现。 北京大学、厦门大学、中南大学以及深势科技等组成的研究团队,提出了一种基于 Trident 策略增强的解缠结表示学习方法(生成模型)。

GPT-4o骗了所有人,逐行画图只是前端特效?!底层架构细节成迷,奥特曼呼吁大家别玩了
GPT-4o玩家太疯狂,奥特曼紧急呼吁别再生成图片了:OpenAI团队为此一直在熬夜。 为什么需要熬夜呢,自原生图像生成推出以来,必须一直有人守着才能保持服务器在线。 与此同时,有人通过分析ChatGPT前端代码,发现用户看到的逐行生成效果只是浏览器端的动画。

不止吉卜力!GPT-4o新玩法全网疯传,网友:AI成精了
万万没想到,GPT-4o图像生成功如此火爆,奥特曼在线直呼太疯狂! 前有「吉卜力风」一夜爆火,今有「文艺复兴」席卷全网。 GPT-4o直接让外国网友Cosplay「文艺复兴名场面」!
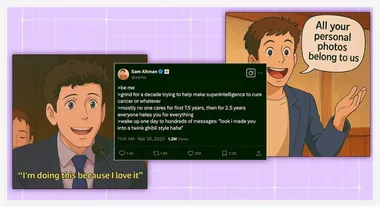
刷屏网络后,ChatGPT 开始屏蔽模仿吉卜力风格的图像生成请求
日前,随着 OpenAI 推出其新款 GPT-4o 图像生成能力,网络上涌现出大量模仿日本著名动画公司吉卜力风格的 AI 生成卡通和表情包,引起了广泛关注。 用户们在社交平台上分享了许多恶搞作品,其中有一幅描绘肯尼迪遇刺事件的作品尤为引人注目。 此外,许多人将自己的照片转化为吉卜力电影风格的图像,进一步推动了这一潮流。

OpenAI在图片领域站起来了!
出品 | 51CTO技术栈(微信号:blog51cto)26日凌晨,OpenAI推出了GPT4o图像生成,可以说解决了此前Midjourney等扩散模型很难解决的问题,业内为之大为赞叹。 这是用手机拍摄的玻璃白板的广角图像,拍摄地点是一间俯瞰海湾大桥的房间。 视野中可以看到一位女士正在写字,她身穿一件印有大型 OpenAI 标志的 T 恤。

ChatGPT拒绝生成玫瑰图像引发网络热议,AI禁忌词再添新例
近日,一位网友在社交平台 X 上发现,ChatGPT 的最新版本 GPT-4o 在尝试生成一朵玫瑰花的图像时,竟然一口回绝,声称 “我无法生成这朵玫瑰的图像,因为它未能符合我们的内容政策”。 这一意外的拒绝迅速引起了众多网友的关注和讨论,许多人开始探究其中的原因,甚至试图找到绕过这一限制的方法。 为了验证这个现象,网友们纷纷进行了一系列实验。
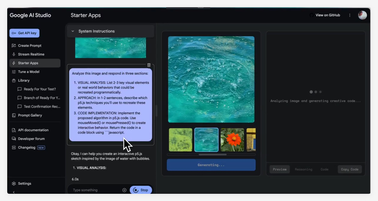
Gemini或将新增功能Image to Code 应用亮相AI Studio
2025 年 3 月 6 日消息,根据X平台用户最新爆料,一款名为“Image to Code”的隐藏初创应用悄然出现在AI Studio中。 这款应用由Gemini技术驱动,能够以图像作为输入,通过分析和推理,最终生成相应的程序代码,绘制出程序化的图像。 这一消息迅速引发了科技爱好者和开发者的广泛关注。

微软开源图片模型ART,可生成多图层透明图片
在图像生成领域,多层图像生成技术正逐渐改变用户与生成模型的互动方式,允许用户隔离、选择并编辑特定的图像层。 近日,微软研究人员推出了一种名为 “Anonymous Region Transformer”(ART)的新型技术,它能够根据全球文本提示和匿名区域布局,直接生成可变多层透明图像。 ART 的设计灵感来源于 “图式理论”,通过采用匿名区域布局,使生成模型可以自主决定哪些视觉信息与哪些文本信息对齐。
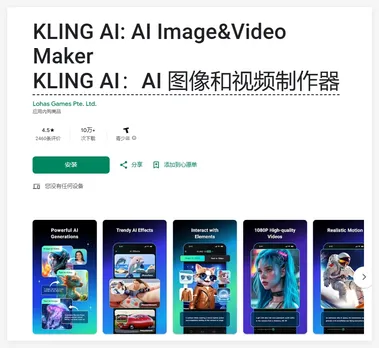
官宣!可灵 AI 安卓应用正式上线
日前,可灵 AI 官方宣布,备受期待的安卓应用终于上线。 这款应用将用户所喜爱的 Kling AI 功能集中于一处,用户只需轻轻点击,即可体验丰富多样的功能,包括 Frames、Elements 等。 根据官方页面介绍,KLING AI 的核心功能包括 AI 视频生成和 AI 图像生成。

智谱发布首个能生成汉字的开源文生图模型CogView4
2025年3月4日,北京智谱华章科技有限公司宣布推出首个支持生成汉字的开源文生图模型——CogView4。 该模型在DPG-Bench基准测试中综合评分排名第一,成为开源文生图模型中的SOTA(State of the Art),并遵循Apache2.0协议,是首个支持该协议的图像生成模型。 CogView4具备强大的复杂语义对齐和指令跟随能力,支持任意长度的中英双语输入,并能生成任意分辨率的图像。

重磅!MiniMax推全新图像生成模型 Image-01,使用成本仅为 1/10
日前,AI科技公司MiniMax 宣布推出其首款文本到图像生成模型 ——Image-01,用户现在可以通过 MiniMax 的 API 平台访问这一服务。 Image-01的几个主要特点令人瞩目。 该模型具有精确的提示控制能力,基于 MiniMax 在开发 Hailuo AI Video-01系列中的行业领先经验,Image-01能够提供优越的提示与图像之间的保真度。

谷歌发布 SpeciesNet AI 模型 助力野生动物识别
近日,谷歌宣布开源一款名为 SpeciesNet 的人工智能模型,该模型旨在通过分析相机捕捉到的照片来识别动物种类。 随着科研工作者在全球范围内使用相机陷阱(连接红外传感器的数字相机)进行野生动物研究,这些设备虽然提供了宝贵的数据,但同时也会产生大量数据,处理这些数据往往需要耗费数天到数周的时间。 为了解决这一问题,谷歌在六年前启动了 “野生动物洞察” 项目,属于其谷歌地球外展慈善计划的一部分。

PhotoDoodle AI 只需几个提示即可将您的照片变成异想天开的艺术作品
字节跳动携手中国和新加坡大学研究团队推出的新型AI图像编辑系统PhotoDoodle,正在重新定义我们对图像创作的理解。 这款基于Flux.1模型的创新技术,能够从少量样本中学习艺术风格,并精准执行特定编辑指令,为创意表达开辟了全新可能。 以 Flux.1为基础PhotoDoodle的核心是研究团队首先开发的OmniEditor系统,它巧妙地利用LoRA(低秩自适应)技术对德国初创公司Black Forest Labs的Flux.1图像生成模型进行了改良。

ImageNet-D 详解:严格评估神经网络的鲁棒性
神经网络在零样本图像分类中取得了惊人的成就,但它们真的能“看”得有多好呢? 现有的用于评估这些模型鲁棒性的数据集仅限于网络上的图像或通过耗时且资源密集的手动收集创建的图像。 这使得系统评估这些模型在面对未见数据和真实世界条件(包括背景、纹理和材质的变化)时的泛化能力变得困难。

耶鲁大学和Adobe提出SynthLight:智能重塑人像照明,打造完美光影
耶鲁大学和Adobe提出一种用于人像重新照明的扩散模型SynthLight,该方法将图像重新照明视为重新渲染问题,其中像素会根据环境照明条件的变化而变化。 在真实肖像照片上可以产生逼真的照明效果,包括颈部的明显投射阴影和皮肤上的自然镜面高光。 相关链接论文:: 是一种用于人像重新照明的扩散模型。

小红书提出新面部视频交换方法DynamicFace,可生成高质量且一致的视频面部图像
DynamicFace是一种新颖的面部视频交换方法,旨在生成高质量且一致的视频面部图像。 该方法结合了扩散模型的强大能力和可插拔的时间层,以解决传统面部交换技术面临的两个主要挑战:在保持源面部身份的同时,准确传递目标面部的运动信息。 通过引入四种细粒度的面部条件,DynamicFace能够对面部特征进行更精确的控制,从而实现高保真度的面部交换。

图像编辑大一统?多功能图像编辑框架Dedit:可基于图像、文本和掩码进行图像编辑
本文经AIGC Studio公众号授权转载,转载请联系出处。 今天给大家介绍一个基于图像和文本的编辑的框架D-Edit,它是第一个可以通过掩码编辑实现图像编辑的项目,近期已经在HuggingFace开放使用,并一度冲到了热门项目Top5。 使用 D-Edit 的编辑流程。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI绘画
AI新词
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
智能体
技术
Gemini
英伟达
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
代码
AI for Science
苹果
腾讯
算法
Agent
Claude
芯片
Stable Diffusion
具身智能
xAI
蛋白质
开发者
人形机器人
生成式
神经网络
机器学习
AI视频
3D
RAG
大语言模型
字节跳动
Sora
百度
研究
GPU
生成
工具
华为
AGI
计算
AI设计
生成式AI
大型语言模型
搜索
视频生成
亚马逊
AI模型
特斯拉
DeepMind
场景
深度学习
Copilot
Transformer
架构
MCP
编程
视觉