可控图片生成,如今已经不是什么新鲜事。甚至也不需要复杂的提示词,用户通过简单的文本描述,就能快速生成符合个人需求的创意图像。
不过仍然有一些局限:
比如说,虽然可以实现单一任务(如身份、主体、风格、背景等)的定制化设计,可是一旦条件增多,就会出现“鱼和熊掌不可兼得”的问题。
只有小孩子才做选择题,成年人当然是全都要!
字节跳动与北京大学联合起来,证明了“全都要”的可行性:一种支持多条件组合的统一图像定制化生成框架——DreamO,堂堂登场。
这个框架通过单一模型便可以实现主体、身份、风格及服装参考的多样化定制,并支持不同控制条件的自由组合,非常适应实际应用中的复杂需求。

△参考多个主体的生成结果
那么就有人问了,他们是怎么做到的呢?这个框架和现有的商业大模型相比有什么优势呢?
一起来看技术细节。
DreamO:成本更低、速度更快
字节跳动和北大团队提出了统一的图像定制化生成框架DreamO,以极低的训练参数量(400M),就实现了如下图所展示的多种类型高质量图像定制化结果:

该工作旨在通过单一模型完成各种定制化任务。
比如说,以小怪物为参考,让它在山上欢呼:

又比如说,让漂亮的姑娘在花海里起舞:

根据参考,生成一张魔幻风格的城堡:

或者大胆一点——地狱风格的小狗怎么样?

还可以参考多个主体,把他们组合起来:

让隔着时间或者空间的人出现在同一张照片上:

 将该模型与GPT-4o等一众商业大模型做对比,尽管在语义理解、定制多样性上还有差距,但该模型展现出了极强的一致性保持能力,甚至在一定程度上超越了一些商业大模型。
将该模型与GPT-4o等一众商业大模型做对比,尽管在语义理解、定制多样性上还有差距,但该模型展现出了极强的一致性保持能力,甚至在一定程度上超越了一些商业大模型。
与商用模型相比,DreamO开源、成本更低、速度也更快——8~10s即可完成一张图片的定制化生成。

方法整体框架
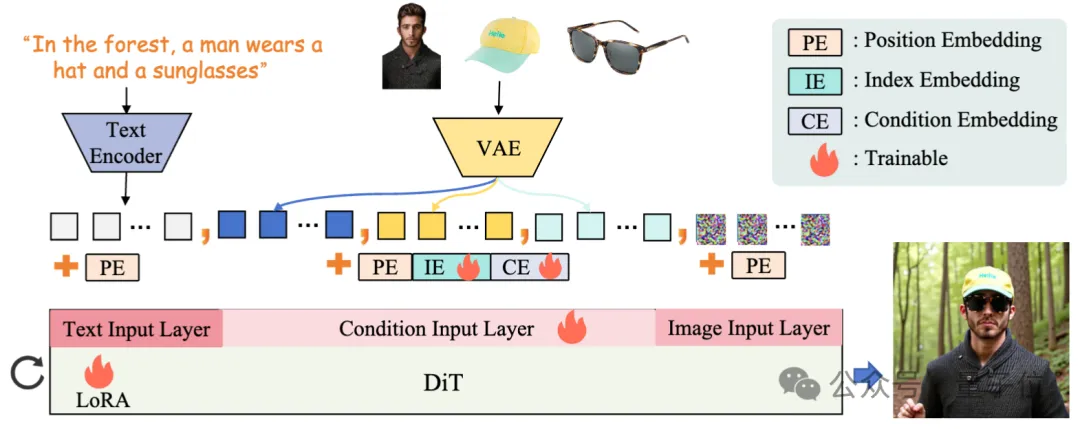
△DreamO的整体框架
该方法基于Flux-1.0-dev构建了一个统一的图像定制框架,支持风格、身份、外观和试穿等功能。
首先,复用Flux的VAE将条件图像编码为隐空间表征,随后序列化,与文本和图像token合并输入Flux模型,为处理条件图像输入,引入了专门的映射层。
另外,该方法为条件隐变量加入了可学习的条件嵌入(CE)和索引嵌入(IE),并通过低秩自适应(LoRA)模块优化模型,从而支持多条件任务。
渐进式的训练策略
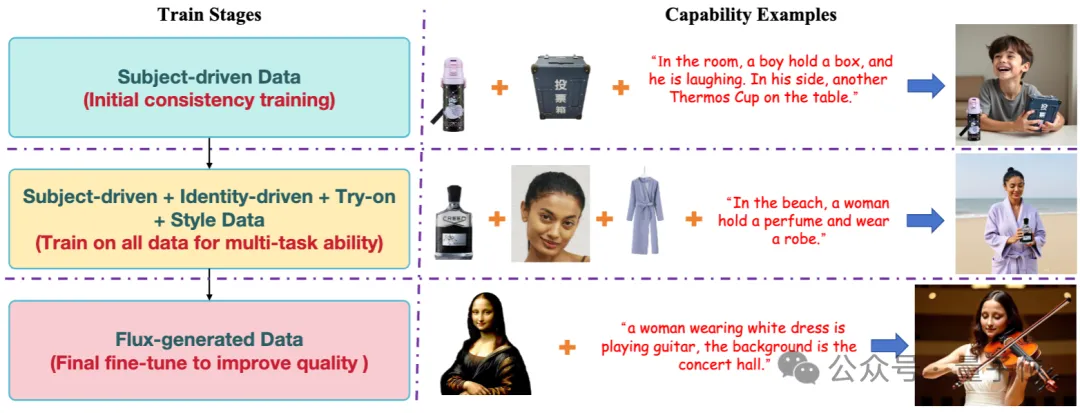
直接在所有数据上训练会导致收敛困难,主要由于优化参数容量有限,难以在复杂数据分布中捕捉特定任务能力;而训练数据的图像质量问题也使生成结果偏离Flux的高质量生成先验。
为解决这些问题,DreamO提出了渐进式训练策略:
在第一阶段,在主体驱动的数据上优化模型,确保一致性,并利用与模型生成空间分布相似的Subject200K数据集加速收敛。使模型获得了初步的一致性保持能力。
在第二阶段,模型进行全数据训练,逐渐掌握各种任务能力。但生成质量容易受低质量训练样本影响。
在图像质量优化的第三阶段,通过Flux生成40K样本,以原始图像(丢弃95%的信息)为参考进行自我重建。
经过第三阶段优化后,图像的生成质量显著提高,与Flux的生成先验对齐。
针对参考图的路由约束
该方法在DiT架构中设计了路由约束用于精准限制参考图的作用区域。
在条件引导框架中,条件图像与生成结果之间存在交叉注意力关系,如下所示: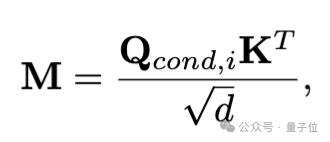 表示条件图像与生成结果的相似度。
表示条件图像与生成结果的相似度。
通过沿条件图维度平均该相似度矩阵,可以得到条件图对生成结果的全局相似度响应。
训练过程中,使用条件物体在生成结果中对应的mask作为ground truth约束条件图的相似度响应范围: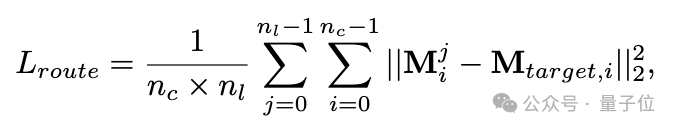
实验结果显示,经过路由约束的训练后,条件图的相似度响应更加集中,生成结果的保真度更高。

另外,为了支持DreamO的多任务优化,作者构建了大规模包含各种任务的训练数据,例如风格迁移、单主体保持、多主体保持、单ID保持、多ID保持、ID风格化,以及虚拟试衣等。
更多细节请参考该方法的技术报告。
论文地址:https://arxiv.org/pdf/2504.16915项目主页:https://mc-e.github.io/project/DreamO/代码仓库:https://github.com/bytedance/DreamOHugging Face演示:https://huggingface.co/spaces/ByteDance/DreamO


