大型语言模型

OpenAI 发布“智能体构建实战指南”实用性文档(附文档资源)
人工智能领域领军企业 OpenAI 近日重磅发布了一份名为“构建智能体实践指南”("A practical guide to building agents")的实用性文档。 这份共34页的指南旨在为产品和工程团队提供构建首个智能体系统的必要知识和最佳实践,其内容凝结了 OpenAI 从众多客户实际部署案例中获得的深刻洞察。 通过阅读本指南,开发者将能够理解智能体的核心概念,掌握何时以及如何设计、构建和安全部署智能体。

当智能体失控时,企业将遭受重创
在采访中,AutoRABIT的CTO Jason Lord探讨了将智能体集成到现实世界中的系统所带来的网络安全风险。 诸如幻觉、提示注入和嵌入式偏见等问题可能会使这些系统成为易受攻击的目标。 Lord呼吁进行监督、持续监控和人为介入循环控制以应对这些威胁。
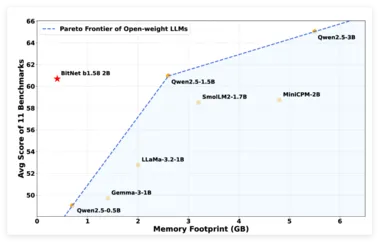
微软推出新型语言模型 BitNet b1.58 2B4T,仅占用0.4GB内存
近日,微软研究团队正式发布了一款名为 BitNet b1.582B4T 的开源大型语言模型。 这款模型拥有20亿参数,采用了独特的1.58位低精度架构进行原生训练,与传统的训练后量化方式相比,BitNet 在计算资源的需求上有了显著的降低。 根据微软的介绍,该模型在非嵌入内存占用方面仅为0.4GB,远低于市场上其他同类产品,如 Gemma-31B 的1.4GB 和 MiniCPM2B 的4.8GB。

亚洲崛起:DeepSeek、巨额投资与数据中心助力 AI 竞争力
在今年的达沃斯世界经济论坛上,众多商界和政界领袖齐聚一堂,普遍认为美国科技巨头在人工智能(AI)领域占据主导地位,而中国乃至整个亚洲似乎都在这一赛道上滞后。 然而,在与会者离开后,这种看法开始遭遇挑战。 首先,来自中国的一家名不见经传的对冲基金 —— 深度寻求(DeepSeek)在这一时刻引发了全球的注意。

Gartner报告显示:2027年,任务特定AI将超越通用AI
近日,Gartner 发布了一份新报告,指出到2027年,企业将使用任务特定的人工智能模型的频率是通用大型语言模型的三倍。 报告中提到,虽然通用的语言模型在语言处理方面具有强大的能力,但在需要深入理解特定业务领域的任务中,它们的响应准确性却会下降。 因此,越来越多的企业开始关注定制化的 AI 模型,以满足其特定需求。

从黑箱到透明工厂:Anthropic用回路追踪技术给LLM装上思维监控屏
译者 | 朱先忠审校 | 重楼引言多年来,基于Transformer的大型语言模型(LLM)在从简单的信息检索系统到能够进行编码、写作、开展研究的复杂智能体等一系列任务上取得了长足的进步。 然而,尽管这些模型功能强大,但它们在很大程度上仍然是黑匣子。 给定输入,它们可以完成任务,但我们缺乏直观的方法来理解任务的具体完成方式。

软件包幻觉:LLM可能会向粗心的开发人员提供恶意代码
大型语言模型倾向于“虚构”不存在的代码包,这可能会成为一种新型供应链攻击的基础,这种攻击被赛斯·拉森(Seth Larson,Python软件基金会的驻场安全开发人员)称为“slopsquatting”。 一种已知现象如今,许多软件开发人员使用大型语言模型(LLM)来辅助编程,然而,不幸的是,LLM在回答各种话题的问题时,会编造事实并自信地呈现出来,这一已知倾向也延伸到了编码领域。 这种情况已为人所知一段时间了。

隐藏在AI工作流程中的悄无声息的数据泄露
随着AI日益融入日常业务流程,数据泄露的风险也随之增加。 Prompt泄露并非罕见个例,而是员工使用大型语言模型时的自然结果。 CISO不能将其视为次要问题。
智谱全新站点 http://z.ai 正式启用
北京智谱华章科技有限公司(以下简称智谱)全新官方网站 已全面上线。 据 AIbase 了解,该平台集成了最新的对话、推理与沉思三款 GLM 模型,自今日起全面向全球用户免费开放使用。
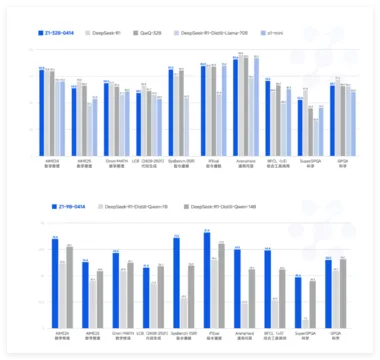
THUDM 发布 GLM 4:32 亿参数模型与 GPT-4o 和 DeepSeek-V3 正面竞争
在快速发展的语言模型领域,研究人员和组织面临着诸多挑战。 这些挑战包括提升推理能力、提供强大的多语言支持以及有效管理复杂的开放任务。 尽管较小的模型通常更容易获得且成本较低,但在性能上往往不及更大的模型。

字节跳动推出 VAPO 框架:突破 AI 推理极限,Qwen2.5-32B 提分 12 倍超 Deepseek-R1
字节跳动Seed团队推出VAPO强化学习框架,针对大型语言模型在复杂任务中的推理能力进行优化。VAPO通过三项创新技术,显著提升模型性能,在AIME24基准测试中得分从5分跃升至60.4分。#AI技术# #字节跳动#

小型推理模型的崛起:紧凑型人工智能能否匹敌GPT级推理能力?
译者 | 涂承烨审校 | 重楼近年来,人工智能领域一直沉迷于大型语言模型(LLMs)的成功。 这些模型最初设计用于自然语言处理,如今已演变为强大的推理工具,能够通过类人类的逐步思考过程解决复杂问题。 然而,尽管LLMs具备卓越的推理能力,它们仍存在显著缺陷,包括高昂的计算成本和缓慢的部署速度,这使得它们在移动设备或边缘计算等资源受限的实际场景中难以应用。

GenAI红队:将LLM置于网络安全测试中的技巧和技术
译者 | 晶颜审校 | 重楼从头构建一个GenAI红队,或者让现有的红队适应新技术是一个复杂的过程,OWASP在其最新指南中帮助阐释了这一过程。 红队是测试和支持网络安全系统的一种有效方法,但它仍需适应技术的发展而不断完善。 近年来,生成式人工智能(GenAI)和大型语言模型(LLM)的爆炸式增长正迫使红队世界适应。

成功采用AI需要具备两个条件
企业不应回避利用AI工具,但需要找到最大化效率和缓解企业风险之间的平衡点。 他们需要做到以下几点:制定无缝的AI安全政策以往,AI可能只是开发人员或专家交互的技术,但如今,公司各层级的员工都使用AI来协助他们完成各种任务。 因此,企业必须教育所有员工,让他们了解哪些大型语言模型和智能体应用程序是他们被授权使用的,以及他们可以与这些系统共享哪些类型的数据。

MCP 和 Function Calling:概念
随着人工智能的快速发展,大型语言模型(LLMs)逐渐深入到我们生活与工作的各个方面。 然而,尽管模型强大,但其能力仍存在局限性,比如在实时信息获取和复杂任务执行方面仍有不足。 RAG(检索增强生成)现在在企业的 AI 应用中使用很广泛,就是为了解决模型的信息不够实时,且没有垂直领域知识的问题。

基于DeepSeek推理的文本聚类
译者 | 李睿审校 | 重楼开发人员需要开发和理解一种新的文本聚类方法,并使用DeepSeek推理模型解释推理结果。 本文将探索大型语言模型(LLM)中的推理领域,并介绍DeepSeek这款优秀工具,它能帮助人们解释推论结果,构建能让终端用户更加信赖的机器学习系统。 在默认情况下,机器学习模型是一种黑盒,不会为决策提供开箱即用的解释(XAI)。

五分钟读懂 LLM:DeepSeek、ChatGPT 背后的核心技术
LLM(Large Language Model)是大型语言模型的简称,像DeepSeek、ChatGPT等都属于不同公司开发的LLM。 你可以把它想象成一个超级聪明的聊天机器人和写作助手,它通过学习了海量文字资料,变得非常擅长理解和生成人类语言。 简单来说,它能听懂你说什么,也能像模像样地跟你聊天、写文章等等。

SWEET-RL:基于训练时信息的多轮LLM代理强化学习框架
SWEET-RL(Step-WisE Evaluation from Training-time information,基于训练时信息的逐步评估)是多轮大型语言模型(LLM)代理强化学习领域的重要技术进展。 该算法相较于现有最先进的方法,成功率提升了6%,使Llama-3.1-8B等小型开源模型能够达到甚至超越GPT-4O等大型专有模型的性能水平。 本文将深入分析SWEET-RL如何改进AI代理在复杂协作任务中的训练方法。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉