大型语言模型

亚马逊 Alexa 基金扩展投资范围,青睐人工智能初创企业
亚马逊于2015年成立了 Alexa 基金,最初旨在支持早期语音技术初创企业。 随着大型语言模型的崛起以及亚马逊推出基于生成性人工智能的 Alexa ,该基金决定扩展投资范围,更多地关注人工智能初创企业。 Alexa 基金负责人保罗・伯纳德表示,随着人工智能的迅速发展,基金的使命已经超越了最初的语音技术,开始投资包括人工智能硬件和智能助手等多个领域。

腾讯“混元-T1”推理模型在基准测试中与 OpenAI 的 o1 能力相匹配
腾讯近日宣布推出其最新的大型语言模型——混元-T1,并表示该模型在推理能力上可与OpenAI的最佳推理系统相匹敌。 据腾讯介绍,混元-T1在开发过程中高度依赖强化学习,高达96.7%的训练后算力都用于提升模型的逻辑推理能力以及与人类偏好的一致性。 在多项基准测试中,混元-T1展现出强大的性能。

阿里推出全新多模态模型 Qwen2.5-VL-32B:兼顾视觉语言与数学推理
在人工智能领域,阿里巴巴再次带来了重磅消息。 近日,阿里开源了最新的多模态模型 ——Qwen2.5-VL-32B-Instruct。 这款新模型是 Qwen2.5系列中的一员,其他版本包括3B、7B 和72B,而32B 版本在保持性能的同时,更加注重便捷的本地运行体验。

中国AI黑马DeepSeek-V3震撼登场:20令牌/秒运行速度,能否改写AI格局?
中国人工智能初创公司DeepSeek悄然发布了大型语言模型DeepSeek-V3-0324,在人工智能行业引发了震动。 该模型以641GB的体量现身于AI资源库Hugging Face,此次发布延续了DeepSeek低调却极具影响力的风格,没有大肆宣传,仅附带空的README文件和模型权重。 这款模型采用MIT许可,可免费用于商业用途,且能在消费级硬件——配备M3Ultra芯片的苹果Mac Studio上直接运行。

王炸!DeepSeek-V3-0324悄然发布 ,免费商用,消费级电脑也能跑!
DeepSeek 悄然发布了其最新的大型语言模型 DeepSeek-V3-0324,在人工智能行业内引发了强烈反响。 这款 容量高达641GB 的模型悄然出现在 AI 模型库 Hugging Face 上,几乎没有任何事先宣传,延续了该公司低调但极具影响力的发布风格。 性能飞跃,媲美 Claude Sonnet3.5DeepSeek-V3的发布之所以引人注目,不仅在于其强大的功能,更在于其部署方式和许可协议。
DeepSeek-V3-0324 悄然发布:技术圈沸腾的低调升级
2025 年 3 月 24 日,中国人工智能研究机构DeepSeek在没有任何预告的情况下,于Hugging Face平台上发布了其旗舰语言模型的最新版本——DeepSeek-V3-0324。 这一"低调而强劲"的更新迅速在技术社区引发热议,众多开发者和AI爱好者分享了他们的初步体验与期待。 以下是根据技术社区反馈整理的深度报道。

李开复重组01.AI:拥抱 Deepseek 开源模型,挑战 OpenAI 商业模式
前谷歌中国区负责人李开复正在调整他的人工智能初创公司01.AI 的战略,全面采用 Deepseek 的开源模型,并表示这对 OpenAI 的商业模式构成了生存挑战。 在接受《南华早报》采访时,李开复透露他的公司已放弃之前训练专有大型语言模型的策略,转而完全依赖 Deepseek 的开源产品。 他表示,Deepseek 的发布在中国引发了"ChatGPT 时刻",带动了国内硬件和软件提供商与 Deepseek 模型的整合。
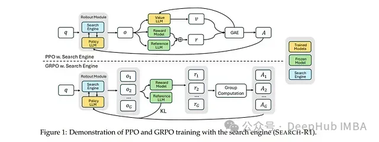
SEARCH-R1: 基于强化学习的大型语言模型多轮搜索与推理框架
这个研究提出了一种新型强化学习(RL)框架SEARCH-R1,该框架使大型语言模型(LLM)能够实现多轮、交错的搜索与推理能力集成。 不同于传统的检索增强生成(RAG)或工具使用方法,SEARCH-R1通过强化学习训练LLM自主生成查询语句,并优化其基于搜索引擎结果的推理过程。 该模型的核心创新在于完全依靠强化学习机制(无需人工标注的交互轨迹)来学习最优的搜索查询策略及基于检索知识的推理方法,从而显著提升问答任务的性能表现。

视觉语言指令微调数据如何构建?
1、构建策略视觉语言指令微调数据构建策略主要有以下两种:标注适配由于视觉模型的发展,已有规模巨大、多样性且高质量的标注数据。 这些数据适合于广泛的下游任务,并可容易地改造为指令数据。 许多工作将已有的标注数据转化为标准的指令数据格式。

保护LLM的身份和访问管理解决方案IAM
译者 | 李睿审校 | 重楼在人工智能时代,大型语言模型(LLM)的应用正在迅速增长。 这些模型提供了大量的机会,但同时也带来了新的隐私和安全挑战。 应对这些挑战的基本安全措施之一是保护对LLM的访问,以确保只有经过授权的人员才能访问数据和执行任何操作的权限。
Cursor 推出 Claude Max,改写 AI 编程格局
一场悄无声息的革命正在编程世界展开。 Cursor 最新推出的 Claude Max 模型,以其惊人的性能和突破性的能力,正在重新定义我们对 AI 辅助编程的认知边界。 这款搭载 Claude3.7大脑的超级模型,不仅智能超群,更凭借一系列革命性突破,向传统 AI 编程工具发起了全面挑战。

详解RAG应用开发幻觉检测利器LettuceDetect
译者 | 朱先忠审校 | 重楼简介最近,我们团队推出了LettuceDetect框架,这是一款用于检索增强生成(RAG)开发管道的轻量级幻觉检测器。 它是一种基于ModernBERT模型构建的基于编码器的模型,根据MIT许可证发布,带有现成的Python包和预训练模型。 是什么:LettuceDetect是一个标记级检测器,可标记LLM回答中不受支持的片段。
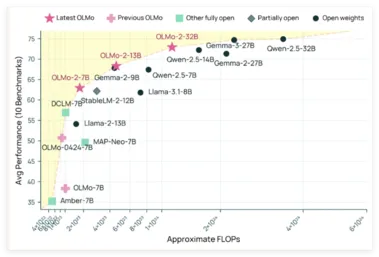
32B参数的“逆袭”!OLMo 2 32B横空出世,叫板GPT-3.5 Turbo
近日,艾伦人工智能研究所(AI2)重磅发布了其最新的大型语言模型——OLMo232B。 这款模型一经亮相便自带光环,因为它不仅是OLMo2系列的最新力作,更以“完全开放”的姿态,向那些高墙深垒的专有模型发起了强有力的挑战。 OLMo232B最引人注目的特点莫过于其彻彻底底的开源属性。

OpenAI 发布报告:大多数GPT-4o API问题已解决
3月18日,OpenAI 发布了最新的事故报告,宣布其 GPT-4o API 问题已基本得到解决。 几天前,该公司曾指出,由于用户通过 API 使用 GPT-4o 时出现响应性能下降,导致部分用户受到影响。 此次更新的报告显示,大多数用户已经恢复了正常的服务体验,但仍有少数客户的情况正在持续关注中。

xAI收购AI视频生成初创公司Hotshot,加强与OpenAI Sora竞争
近日,埃隆·马斯克的人工智能公司xAI已收购了视频生成初创公司Hotshot,这标志着马斯克在AI视频生成领域的重要布局。 Hotshot首席执行官兼联合创始人Aakash Sastry周一在社交平台X上正式宣布了这一消息。 Sastry在公告中表示:"过去2年中,我们作为一个小团队建立了3个视频基础模型——Hotshot-XL、Hotshot Act One和Hotshot。

AAAI 2025|Portcullis —— 面向第三方大型语言模型的可信隐私保护网关
在大模型浪潮的推动下,企业和个人的数据安全面临前所未有的挑战。 抖音集团安全研究团队推出Portcullis ——针对大模型的隐私保护网关,旨在为第三方大型语言模型(LLM)推理服务提供可控可信的隐私防护。 该工作成果 《Portcullis : A Scalable and Verifiable Privacy Gateway for Third-Party LLM Inference》已被人工智能领域的顶级会议AAAI 2025以Oral报告的形式接收。
Anthropic或将发布Claude3.7Sonnet Max?Cursor更新引发猜测
近日,AI代码编辑器Cursor在其最新版本0.47.5的更新日志中透露,正在为Anthropic即将推出的“Claude3.7Sonnet Max”模型做准备。 这一消息迅速引发业内关注。 然而,目前Anthropic尚未发布任何官方公告,关于“Claude3.7Sonnet Max”的具体信息仍是个谜。

有望重新定义语言生成技术的扩散模型——LLaDA
译者 | 朱先忠审校 | 重楼简介如果我们能让语言模型更像人类一样思考,结果会怎样? 如果它们不是一次写一个字,而是先勾勒出自己的想法,然后逐渐完善,结果又会怎样? 这正是大型语言扩散模型(LLaDA)所引入的:一种与大型语言模型(LLM)中当前使用的文本生成不同的方法。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉