
译者 | 朱先忠
审校 | 重楼
引言
多年来,基于Transformer的大型语言模型(LLM)在从简单的信息检索系统到能够进行编码、写作、开展研究的复杂智能体等一系列任务上取得了长足的进步。然而,尽管这些模型功能强大,但它们在很大程度上仍然是黑匣子。给定输入,它们可以完成任务,但我们缺乏直观的方法来理解任务的具体完成方式。
LLM旨在预测统计上最佳的下一个单词/标记。但是,它们是否只专注于预测下一个标记,还是会提前规划?例如,当我们要求模型写一首诗时,它是一次生成一个单词,还是在输出单词之前预测押韵模式?或者,当我们被问及一些基本的推理问题,例如达拉斯所在的州首府是什么?它们通常会产生看起来像是一连串推理的结果,但模型真的运用了这些推理吗?我们无法洞察模型的内部思维过程。要理解LLM,我们需要追溯其底层逻辑。
对大型语言模型(LLM)内部计算的研究属于“机械可解释性”领域,旨在揭示模型的计算回路。Anthropic是致力于可解释性研究的领先人工智能公司之一。2025年3月,他们发表了一篇题为《回路追踪:揭示语言模型中的计算图》的论文,旨在解决回路追踪问题。
本文旨在解释他们的论文工作背后的核心思想,并为理解LLM中的回路追踪奠定基础。
LLM中的回路是什么?
在定义语言模型中的“回路”之前,我们首先需要了解LLM的内部结构。它是一个基于Transformer架构的神经网络;因此,将神经元视为基本计算单元,并将其跨层激活模式解释为模型的计算回路,这似乎是显而易见的。
然而,论文《迈向单义性》表明,仅仅追踪神经元的激活并不能清楚地理解这些神经元被激活的原因。这是因为单个神经元通常是多义的,它们会对一系列不相关的概念做出反应。
此论文进一步表明,神经元由更基本的单元(称为特征)组成,这些单元能够捕获更多可解释的信息。事实上,一个神经元可以被看作是多个特征的组合。因此,我们的目标是追踪特征激活,而不是追踪神经元激活,也就是驱动模型输出的实际意义单元。
这样,我们可以将回路定义为模型用来将给定输入转换为输出的特征激活和连接序列。
现在,我们知道了我们在寻找什么。接下来,让我们更深入地了解一下基于Transformer的大型语言模型的基本架构。
技术架构
目前,我们已经确定需要追踪特征激活而不是神经元激活。为了实现这一点,我们需要将现有LLM模型的神经元转换为特征,即构建一个以特征形式表示计算的替代模型。
在深入探讨这个替代模型是如何构建的之前,我们先简单回顾一下基于Transformer的大型语言模型的架构。
下图展示了基于Transformer的语言模型的运作方式。其思路是,使用嵌入将输入转换为标记(token)。这些标记被传递到注意力模块,该模块计算标记之间的关系。然后,每个标记被传递到多层感知器(MLP)模块,该模块使用非线性激活函数和线性变换进一步细化标记。在模型生成最终输出之前,此过程会在多层中重复进行。
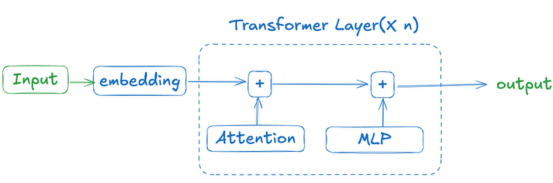
本图片由作者本人绘制
既然我们已经阐述了基于Transformer的LLM的结构,接下来我们来看看什么是转码器。作者使用了一个“转码器”来开发替换模型。
转码器
转码器本身是一种神经网络(通常比LLM的维度高得多),旨在用更易于解释、功能等效的组件(特征)替换转换器模型中的MLP块。
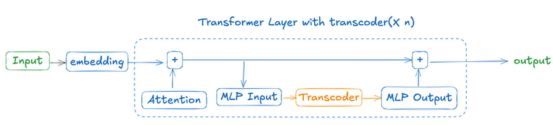
本图片由作者本人绘制
它分三个阶段处理来自注意力模块的标记:编码、稀疏激活和解码。实际上,它将输入缩放到更高维空间,应用激活以强制模型仅激活稀疏特征,然后在解码阶段将输出压缩回原始维度。

本图片由作者本人绘制
在对基于转换器的LLM和转码器有了个基本了解之后,让我们看看如何使用转码器来构建替换模型。
构建替代模型
如前所述,Transformer模块通常由两个主要组件组成:注意力模块和MLP模块(前馈网络)。为了构建替换模型,需要将原始Transformer模型中的MLP模块替换为转码器。这种集成是无缝的,因为转码器经过训练可以模拟原始MLP的输出,同时通过稀疏和模块化特征公开其内部计算。
虽然标准转码器在单个Transformer层中训练以模仿MLP行为,但本文作者使用了跨层转码器(CLT),它可以捕获跨多个层级的多个转码器块的组合效应。这一点非常重要,因为它使我们能够追踪某个特征是否分布在多个层级上,而这对于回路追踪至关重要。
下图展示了如何使用跨层转码器(CLT)构建替换模型。第一层的转码器输出有助于构建所有上层模型的MLP等效输出,直至最后。
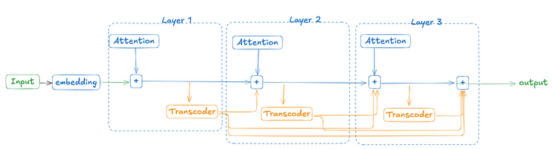
本图片由作者本人绘制
提示:下图来自本文开始处的论文,展示了如何构建替换模型。它是利用特征替换原始模型的神经元。
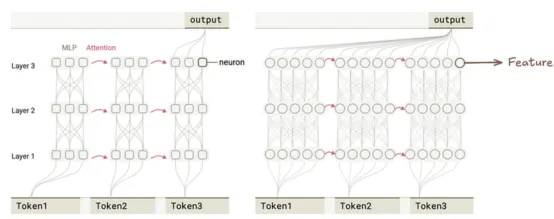
本图片的出处是这里
现在,我们了解了替换模型的架构。接下来,让我们看看如何在替换模型的计算路径上构建可解释的表示。
模型计算的可解释呈现:归因图
为了构建模型计算路径的可解释表示,我们从模型的输出特征出发,逆向追溯特征网络,以发现哪个先前的特征对其做出了贡献。这通过后向雅可比矩阵来实现,该矩阵可以计算前一层的特征对当前特征激活的贡献程度,并递归应用直至到达输入。每个特征被视为一个节点,每个影响因素被视为一条边。此过程可能生成包含数百万条边和节点的复杂图,因此需要进行剪枝以保持图的紧凑性和手动可解释性。
作者将此计算图称为归因图,并开发了检查它的工具,这成为了本文的核心贡献。
下图展示了一个示例归因图。
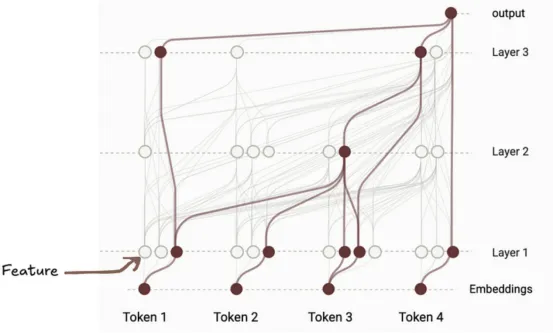
本图片的出处是这里
现在,有了所有这些理解,我们就可以讨论特征可解释性了。
使用归因图实现特征可解释性
研究人员使用Anthropic公司的Claude 3.5Haiku模型的归因图来研究其在不同任务中的表现。在诗歌生成中,他们发现该模型不仅仅是生成下一个词,它还会进行一种规划,既向前规划,又向后规划。在生成一行诗之前,该模型会识别几个可能押韵或语义合适的词作为结尾,然后向后推演,生成一行自然地指向该目标的诗句。令人惊讶的是,该模型似乎可以同时记住多个候选结尾词,并根据最终选择的词重构整个句子。
这项技术提供了一个清晰的、机制化的视角,展现了语言模型如何生成结构化、富有创意的文本。这对于人工智能界来说是一个重要的里程碑。随着我们开发出越来越强大的模型,追踪和理解其内部规划和执行的能力对于确保人工智能系统的一致性、安全性和可信度至关重要。
当前方法的局限性
归因图提供了一种追踪单个输入模型行为的方法,但它们尚无法提供可靠的方法来理解全局回路或模型在多个示例中使用的一致机制。这种分析依赖于用转码器替换多层感知器(MLP)计算,但目前尚不清楚这些转码器是真正复制了原始机制,还是仅仅近似输出。此外,当前方法仅强调活跃特征,但非活跃或抑制性特征对于理解模型行为同样重要。
结论
总之,通过归因图进行回路追踪是理解语言模型内部工作原理的早期的但非常重要的一步。虽然这种方法还有很长的路要走,但回路追踪的引入标志着通往真正可解释性道路上的一个重要里程碑。
参考文献
- https://transformer-circuits.pub/2025/attribution-graphs/methods.html
- https://arxiv.org/pdf/2406.11944
- https://transformer-circuits.pub/2025/attribution-graphs/biology.html
- https://transformer-circuits.pub/2024/crosscoders/index.html
- https://transformer-circuits.pub/2023/monosemantic-features
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Circuit Tracing: A Step Closer to Understanding Large Language Models,作者:Sudheer Singh


