近日,自然语言处理领域的国际顶级会议ACL 2025正在召开,通义实验室 代码智能&对话智能 团队10篇论文被 ACL 2025 录用,围绕着大语言模型的多轮强化学习、复杂指令遵循、多模态角色对话、代码智能、以及评测基准等前沿方向全面开花。本文从中精选了8篇论文的内容进行系统介绍,以此来总结通义实验室代码智能&对话智能团队的前沿研究思考和进展。团队也在大量招聘,详情见文章最后。
一、多轮强化学习
多轮强化学习旨在提高大语言模型在动态环境中持续决策和适应变化的能力,通过与环境或用户进行多轮交互,持续优化策略,实现更自然、高效的智能交互体验。
1. EPO: Explicit Policy Optimization for Strategic Reasoning in LLMs via Reinforcement Learning
| 针对通义晓蜜在复杂场景中因缺乏有效对话策略而导致目标完成率较低的问题,本文提出了显式策略优化(EPO)方法。该方法结合过程奖励与结果奖励,优化大模型在多轮对话中的策略生成能力,使其能够像人一样灵活应对复杂对话并完成任务,在社交对话数据集SOTOPIA上,EPO在7B模型规模下超越GPT-4,达到当前最优水平(SOTA)。 |
研究动机:大模型从“静态问题求解”迈向“动态策略推理”
日常生活中,人们通常需要进行复杂的战略决策,如商务谈判或政策规划。这些情境需要我们能够在未知的环境中进行灵活思考和长远规划。目前,大模型在解决具有固定规则和明确答案的问题上表现优异,如数学和编程。但是,它们在处理涉及不确定性和动态变化的真实世界场景时仍存在挑战。本文旨在解决如何让大模型不仅仅会做“笔试”,还能够在“真实世界”中做出像人一样的聪明决策。
方法创新:多轮强化学习增强大模型协同推理能力
为了提升大模型的策略推理能力,本文提出了一种显式策略优化(EPO)方法: 将策略推理过程显式建模为可优化的自然语言策略生成问题,并设计轻量化的多轮强化学习算法进行策略优化, 如图1所示。EPO的关键技术要点包括:(1)基于REINFORCE的多轮强化学习策略推理训练;(2)策略推理模型与行为模型协同交互,保留智能体的通用泛化能力;(3)引入过程奖励模型(PRM)动态评估策略质量;(4)迭代自博弈持续优化策略适应性与迁移性。EPO旨在让大模型变得更像一个经验丰富的企业家,能够在瞬息万变的环境中不断调整自己的策略。通过一个专门用于策略推理的模型,该方法可以实时提供新颖且多样化的策略,帮助下游智能体在多轮对话或交互中达成目标。这不仅仅是简单的步骤拆解,而是注重在不确定性中寻找最优策略。模型通过多轮强化学习进行训练,还会像玩游戏一样进行“自我对弈”,从中获得经验,逐步提高生成策略的质量。
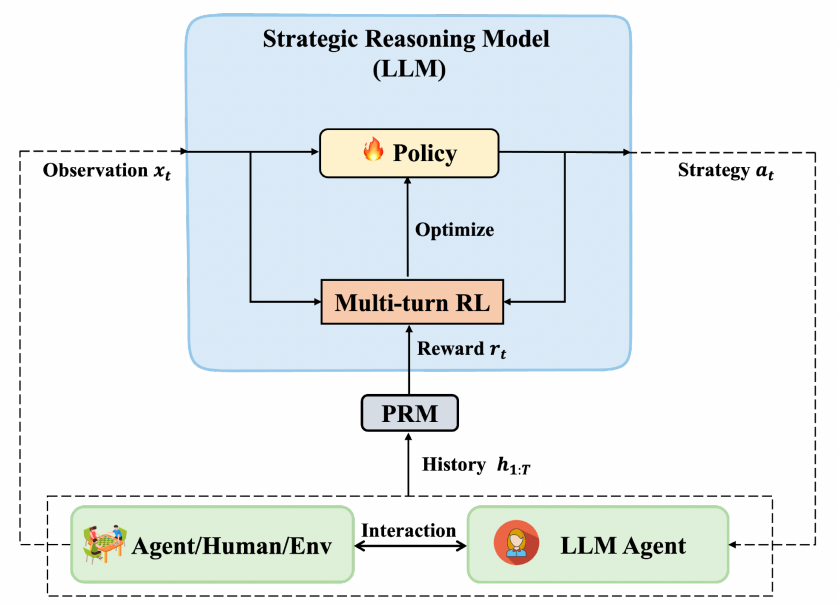
图1 EPO方法架构图
实验分析:从与人交互到环境交互,涌现类人推理策略
本文在社交对话(SOTOPIA)、网页导航(WebShop)和具身交互(ALFWorld)三大场景验证了EPO的有效性。在社交对话场景实现最佳性能,涌现新颖灵活的类人策略,如图2所示。在多轮环境交互场景,目标达成率和长周期规划能力显著提升。另外,在策略推理模型与行为模型协同交互中涌现多种协作推理模式,如双向策略推理较单向策略指导的平均目标达成率提升2.6%。综上,EPO的轻量级架构与开放域特性,能够为商业谈判助手、政策模拟系统和个性化教育代理等场景提供技术支撑,为人机协作的复杂场景提供了新的技术范式。研究团队已开源代码和数据,推动社区在策略推理领域的探索。

图2 智能体通过策略推理模型实现目标导向行为
2. SDPO: Segment-Level Direct Preference Optimization for Social Agents
| 针对通义晓蜜在催收,营销等复杂的外呼场景中多轮对话中准确率低、缺乏拟人化的问题,本文在DPO基础上提出了Segment级别的对齐算法SDPO,通过过围绕问题片段构建所需轮次的多轮偏好数据,实现更精细的多轮对齐,多轮对齐SDPO的效果上大幅度超过传统DPO,让8B模型在多轮对话上超过GPT-4。 |
研究动机:LLM如何在多轮任务中对齐人类偏好
在LLM的训练过程中,如何保持LLM与人类的价值观对齐是一个至关重要的问题,特别是多轮任务,最终的结果往往是需要多个轮次共同作用,然而当前的对齐方法在训练时都只考虑当前轮次生成的回复的收益,而不会考虑当前动作后续多轮可能动作的影响,这一问题导致大模型在多轮交互中难以考虑后续的对话策略或行动轨迹,限制了其在多轮任务上的效果。以前的工作有过一些任务级对齐的尝试,但是存在粒度太粗和理论推导不完善的问题,导致模型可能很难得到明确的正例信号。
研究方法:多轮对齐SDPO(Segment-level DPO)
我们在之前工作的基础上,进一步简化并完善了多轮直接偏好对齐的理论推导过程,并提出了可以适应不同轮次的多轮对齐方法SDPO(Segment-level Direct Preference Optimization),基于严格推导出Segment粒度损失函数,按需构建出所需轮数的偏好数据,可以支持从1到N(N为整个交互轮次)动态轮数的对齐。标准DPO的偏好数据是基于固定的对话上下文,构建一轮正例和负例的回复内容,而SDPO核心区别在于构建多轮正例和负例的对话内容,其中具体需要多少轮次取决于关键问题片段的长度,避免直接使用整个session作为正负例而引入噪音。具体如下图,该场景下对话双方主要在讨论他们周末的旅行计划,其中Agent1的目标是说服Agent2去露营,而Agent2的目标是选择城市休闲活动。
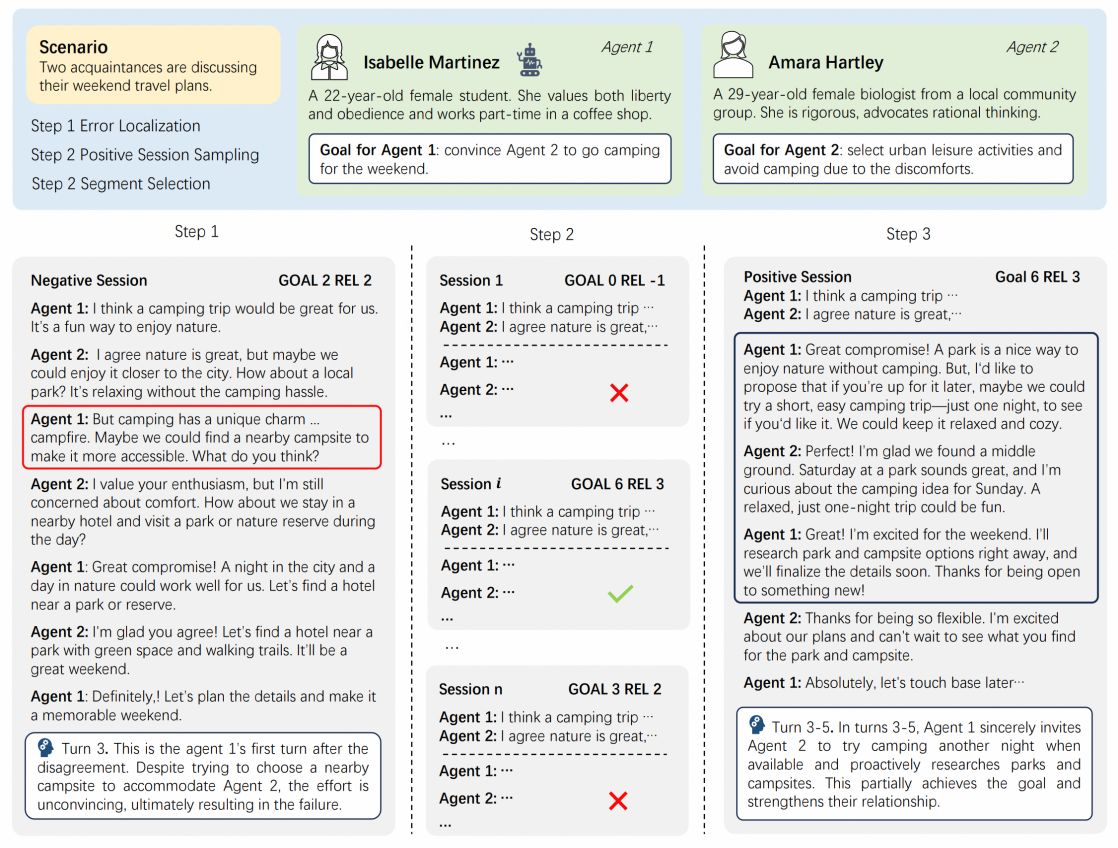
具体到SDPO中,其正负例偏好数据构造流程如下:
1.错误定位:基于完成情况较差的对话session,利用GPT-4定位出错的轮次;
2.采样正例:基于错误轮次前的交互历史采样多个完整的交互路径,选出分数最高的作为正例;
3.区间选择: 利用GPT-4从正例中选出一个区间,应是该区间导致正例的分数高于负例,然后再从负例中选取同样长度的区间与正例的区间构成正负样本对。
取得成果:多轮对齐SDPO效果上大幅度超过标准DPO,让8B模型在多轮对话上超过GPT4o
我们选择近期学界中比较热的社交智能数据集 SOTOPIA 作为主要的评估benchmark,使用我方agent进行Self-chat以及与GPT-4o和GPT-4o-mini交互三个setting进行对比,评估结果如下:
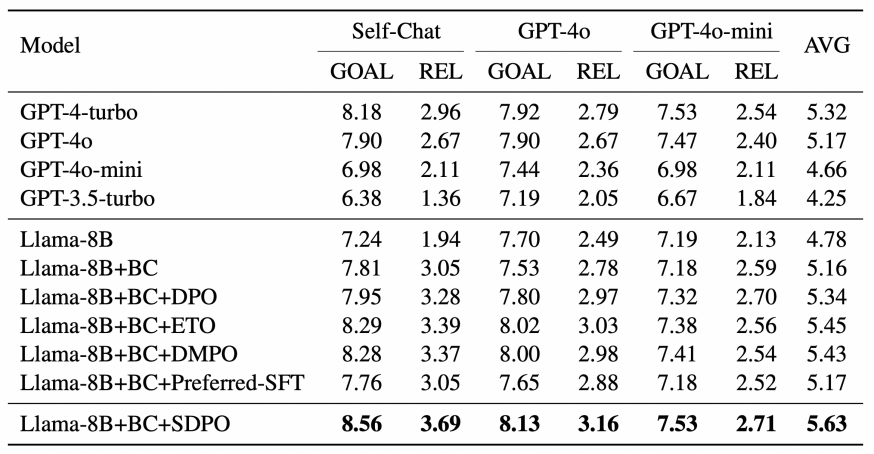
DPO-based 对齐算法中,SDPO取得了最优的效果,显著超过直接偏好对齐DPO 6.1% (7.95 vs 8.56),基于8B模型经过SFT和SDPO后效果超过GPT-4o (8.56 vs. 7.90),说明多轮对齐比单轮有比较显著的提升;相对任务级别对齐ETO和DMPO效果也有显著提升,说明我们按需构建多轮偏好比直接使用任务级偏好更好。最终效果上,超过了OpenAI系列的各个闭源模型,体现了基于SDPO进行post-training的优势。
目前大模型在面临复杂交互场景时还是会有一些痛点,比如在智能客服的催收场景下,由于通用基础模型对齐人类偏好,所以很难违反人类的喜好进行回复,导致催收场景下有两大痛点:很难施展丰富的催收策略,在利益冲突时迎合用户。为了解决上述问题,我们基于多轮对齐SDPO方法,打造了通义晓蜜外呼机器人。
二、复杂指令遵循
复杂指令遵循研究如何让LLM准确理解和执行包含多层逻辑、条件和约束的复杂指令。该方向要求模型具备强大的推理能力与上下文理解能力,是迈向通用智能的重要一步。
3. IOPO: Empowering LLMs with Complex Instruction Following via Input-Output Preference Optimization
| 针对对话分析场景中(如通义晓蜜对话分析)业务方需求规则多样复杂,导致模型难以完全精准遵循的问题,本文提出输入-输出偏好对齐(IOPO)算法,使LLMs在学习输出偏好的同时细致探索输入指令偏好,以促进对细粒度多需求的高效感知,有效拓展了模型在复杂指令遵循能力上的广泛应用。 |
研究动机:指令复杂度随着大模型的深度应用显著增加,现有模型在复杂指令遵循能力上的不足限制了模型的广泛应用
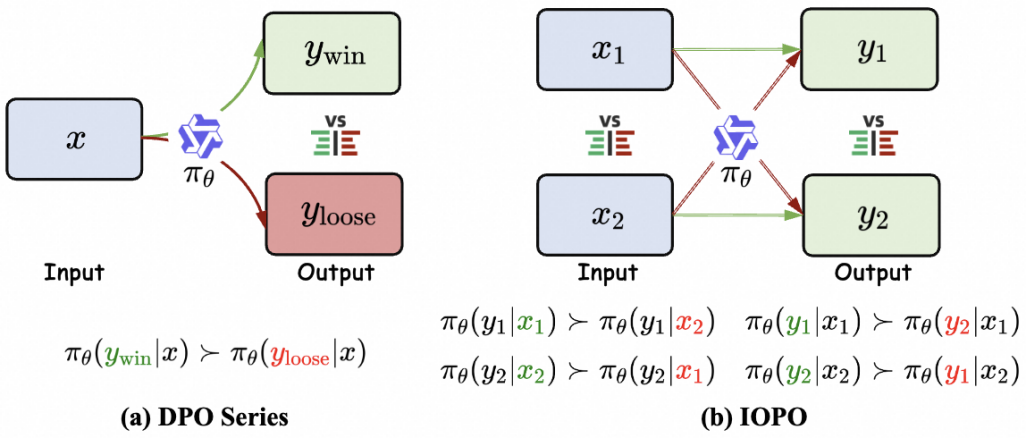
大语言模型的迅速发展,促使其在软件设计、agent构建等方面获得广泛应用,但随之而来的是指令复杂度的迅猛增长,持续提升模型的复杂指令遵循能力对LLM的落地应用具有重要的研究价值。然而,目前仅有少量的复杂指令评测数据,并缺少针对性提升LLM复杂指令遵随能力的算法。从RLHF到xPO(如DPO),LLM对齐算法已经证明了其在增强模型指令遵循能力的有效性。然而,现有算法直接基于相同的指令输入x,去探究不同的回复输出y(如上图a)。在这种具有多个约束的复杂指令场景,仅仅通过建模不同的输出y去有效感知输入x中细粒度的约束具有很大挑战。
研究方法:输入+输出偏好兼顾的LLM对齐算法IOPO
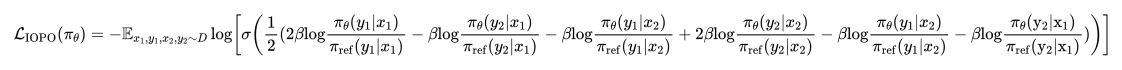
本文通过约束类型体系构建、约束扩展、指令结构化、质量控制、回复生成与评估等自动化构建链路构建了复杂指令遵循 benchmark TRACE,用于改善和评估模型的复杂指令遵循能力,其包含12万条训练数据和1千条评测数据。进一步,基于BT Model经一系列推导,本文提出了IOPO(Input-Output Preference Optimization)算法,使LLM在学习回复(输出)偏好的同时细致探索指令(输入)偏好。具体来说,IOPO不仅将指令作为输入来直接学习输出偏好,且基于相同的输出深入探索指令(输入)差异,以促进对细粒度约束的有效感知。
研究成果:细粒度的偏好建模助力LLM复杂指令遵循能力显著提升
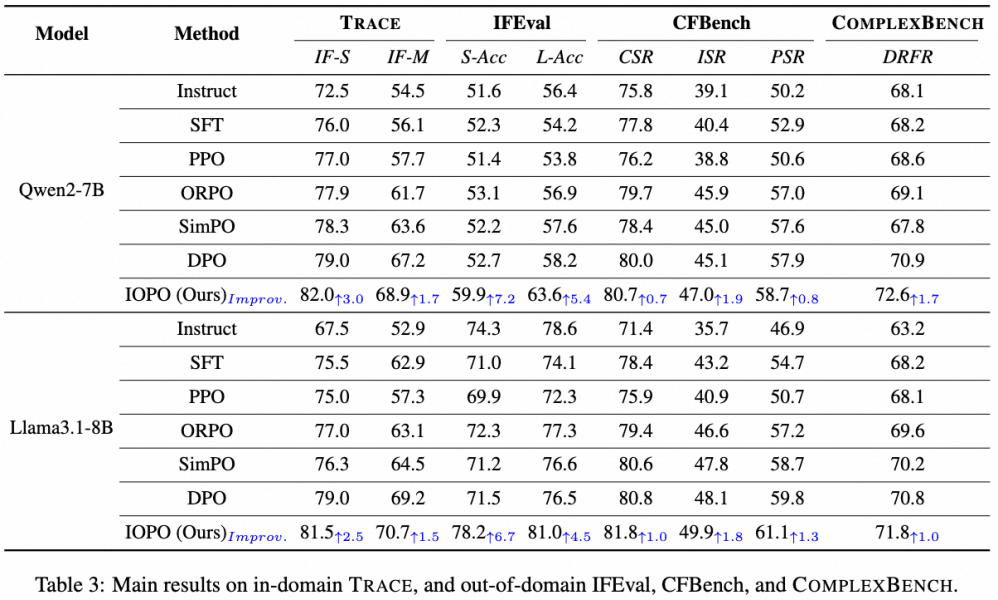
本文在域内数据TRACE以及公开的复杂指令数据IFEval和CFBench域外评测数据上进行实验,以Qwen2-7B-Instruct和Llama3.1-8B-Instruct为基座模型,在TRACE训练集上分别进行SFT、DPO、IOPO等实验。(1)实验结果证明,仅在TRACE训练集上进行IOPO偏好对齐,直接在域内评测集TRACE和域外的IFEval、CFBench、ComplexBench上进行评测,IOPO相比SFT、DPO在域内和域外均具有显著优势,证明了IOPO优异的泛化能力以及建模输入偏好的必要性。(2)IOPO相比DPO会消耗更多的token,为探究这一因素的影响,本文将IOPO训练数据适配到SFT和DPO进行训练,确保其具有相同数量的训练token,最终实验结果证明了IOPO性能的提升不是主要来自于消耗更多的训练token,而是受益于更优异的输入输出偏好的约束感知建模能力。
4. Reverse Preference Optimization for Complex Instruction Following
| 针对对话场景中(如通义晓蜜与通义星尘)难以同时满足多个用户偏好指令,导致产生的训练噪音问题,本文提出反向偏好优化(RPO)方法,通过巧妙地反转用户约束构造完美回复样本,使模型在多轮复杂指令任务中表现显著提升,在70B模型规模上整体超越GPT-4o。 |
研究动机:多偏好优化过程中的噪音问题
随着大模型的生成能力的快速发展,在生成的同时考虑不同用户的多样偏好成为客服对话,角色扮演,智能体等应用中的核心挑战之一。指令遵循评估的是模型在回复用户问题的时候,是否能同时满足用户提出的要求,例如“写一个关于哪吒的故事,不要超过200字并且以一个emoji结尾”。
之前的工作主要关注单偏好,或固定的几个偏好的对齐,然而对于复杂指令遵循这种要对齐动态的复合偏好的情况,随着要对齐的用户偏好的数量和难度的增加,同时满足多个偏好的高质量完美回复变得难以获取,这带来三个问题:
1.回复间差异衡量不准确:之前的工作用总分(回复满足了多少个约束)的差异作为衡量回复之间差异的方法构建偏好对。但总分只能代表回复质量的差异,并不能代表两个回复之间本身差异程度。
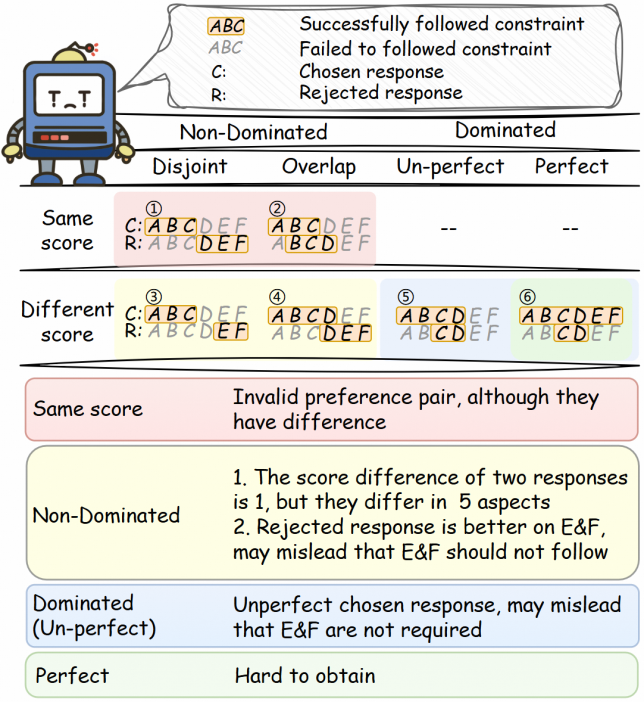
2.正例不支配负例:正例不能支配负例时会引入噪音,因为正例只是总分比负例高,有些方面可能做得不如负例,可能误导模型那些正例没有满足而负例满足的约束不应该被遵循。(例1,2,3,4)
3.部分约束学习不到:如果正例是不完美的,可能误导模型那些正例没有遵循的约束不需要遵循(例5)
支配:回复1支配回复2,指的是在任意一个方面,回复1都不差于回复2,例如回复1满足了ABCD三个约束,回复2满足了BC两个约束,两个回复就是支配关系;而如果回复2满足的是CDE三个约束,在E约束的遵循上优于回复1,则他们不构成支配关系。
我们发现当正样本完美遵循所有约束时开源避免上述问题(例6),但是这样的样本难以获取,可能采样很多次或者结合进一步的refine才能得到,采样效率很低。并且会随着要遵循的约束的数量的增加越来越难获取。
综合上述提到的问题,多偏好对齐的核心挑战可以归结为如何低成本地获取包含完美正例的偏好对,以消除正例不能完全支配负例和不能学习到全部约束的问题。
研究方法:通过反转约束构造无噪偏序对
具体而言,给定一个回复,我们先判断他没有满足哪些约束,然后将这些约束替换为他们的对立面,这样对新的约束列表,原回复就是完美的,它可以严格支配任意和它遵循情况不同的回复,消除了噪音问题,并且不需要刻意采样完美回复。
我们分别将一个回复对中的两个回复通过反转约束的方式,让他们变成特定约束列表下的完美回复,构成两个偏好对。以这种方式,原本属于噪音来源的约束(两个回复分别遵循和不遵循它),构造的两个偏好对可以分别学习到遵循原约束和遵循原约束的对立面,原始回复之间的噪音(各自独有的优势)越大,能够充分学习到的约束反而越多。
我们还引入了一个自适应的margin,缓解pair-wise对齐方法对不同差异的偏好对一视同仁的问题,让差异更大的偏好对的正负例概率之间获得一个更大的gap。
因为反转后的回复对之间是支配关系,分差可以真实地反映回复间的真实差异,提供更准确margin。RPO的优化目标可以形式化为:
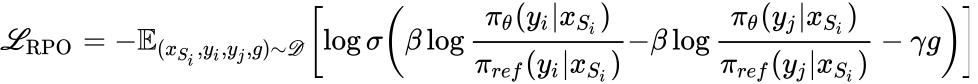

实验分析:更高的采样效率和更好的性能
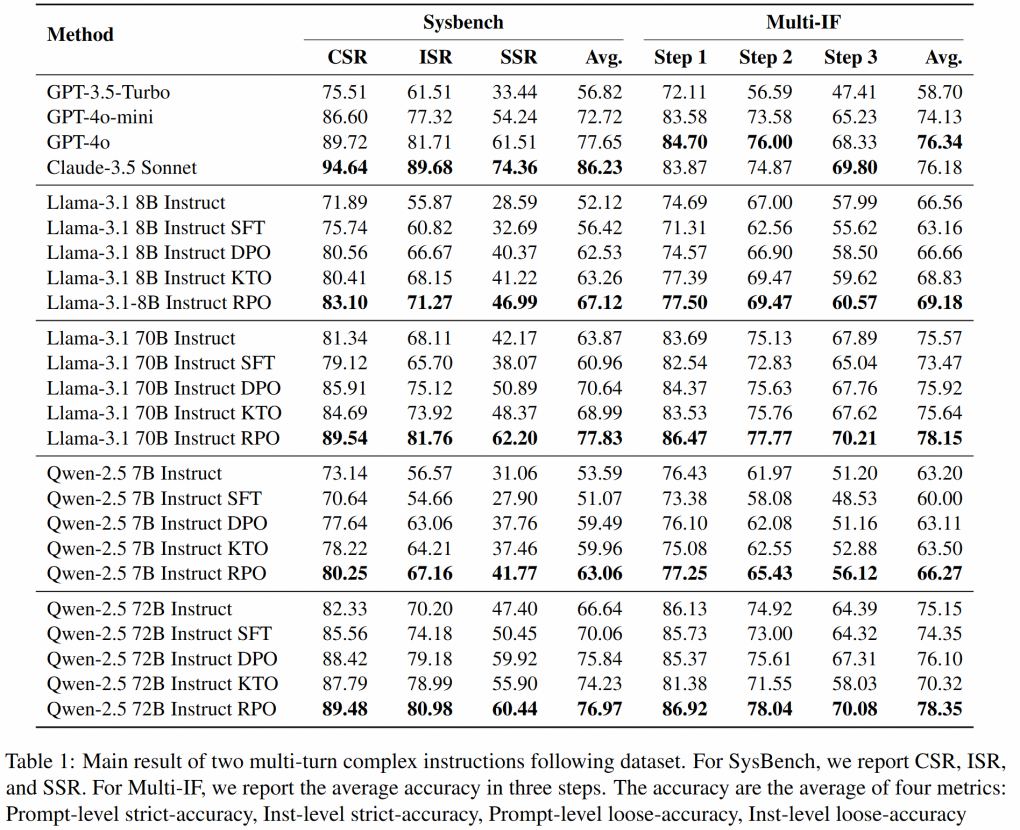
我们在两个multi-turn的复杂IF数据集(Sysbench,MultiIF)上,评测了Instruct,SFT,DPO,KTO,和RPO的实验效果。
在两个系列(Llama,Qwen)和两个size(8B,70B)的模型上,RPO明显优于DPO和KTO基线,在四个不同的模型上分别超过DPO基线4.6,7.2,3.6,1.2(Sysbench),2.6,2.2,2.7,2.2(Multi-IF)。在70B规模的模型上,除了一个指标上稍差外,RPO全面超越了GPT-4o。
三、多模态角色对话
多模态角色对话聚焦于让AI能够融合文本、语音、图像等多种模态信息,进行更加丰富和自然的角色扮演对话和情感表达,使得AI角色更加生动真实。
5. OmniCharacter: Towards Immersive Role-Playing Agents with Seamless Speech-Language Personality Interaction
| 针对通义星尘AI角色扮演模型忽略语音风格、导致沉浸感不足的问题,我们提出了首个无缝融合语音和文本模态的端到端交互模型-OmniCharacter,通过统一编码文本与语音输入并生成离散“语音令牌”的模型结构,结合高质量OmniCharacter-10K数据集进行训练,大幅提升了角色的真实感和沉浸感。 |
研究动机:为AI角色注入独特“声音灵魂”,构建首个语音端到端角色扮演模型
现在的人工智能(AI)越来越聪明,甚至能像演员一样扮演不同角色,和我们聊天互动,这就是“AI角色扮演”。但目前存在的问题是,这些文本AI“演员”大多只会“打字”交流。这就好比你看电影,角色很有个性,但如果只看字幕,就感受不到他们说话的语气、独特的嗓音和情感,魅力会大打折扣。
从这点出发,本文主要解决的问题是:怎样让AI扮演的角色不仅能说对话,更能拥有一以贯之的、符合其人设的独特“嗓音”和“口气”,让整个互动过程听起来更真实、更像角色本人,从而让你感觉真的在和TA对话。
OmniCharacter:融合多模态理解与个性化语音生成的沉浸式角色扮演模型
为了有效解决角色扮演AI在声音个性化表达上的挑战,我们首先构建了OmniCharacter-10K数据集,包含了20个具有鲜明个性和独特声音特点的角色。每个角色不仅有详细的背景设定和性格描述,还配备了大量情境丰富的多轮对话文本,以及与之对应的高度清晰的、充分体现其角色特性的动态语音回应。这个数据集的构建,为后续模型学习和准确模仿不同角色的语言风格与声音特征提供了丰富且高质量的训练素材。
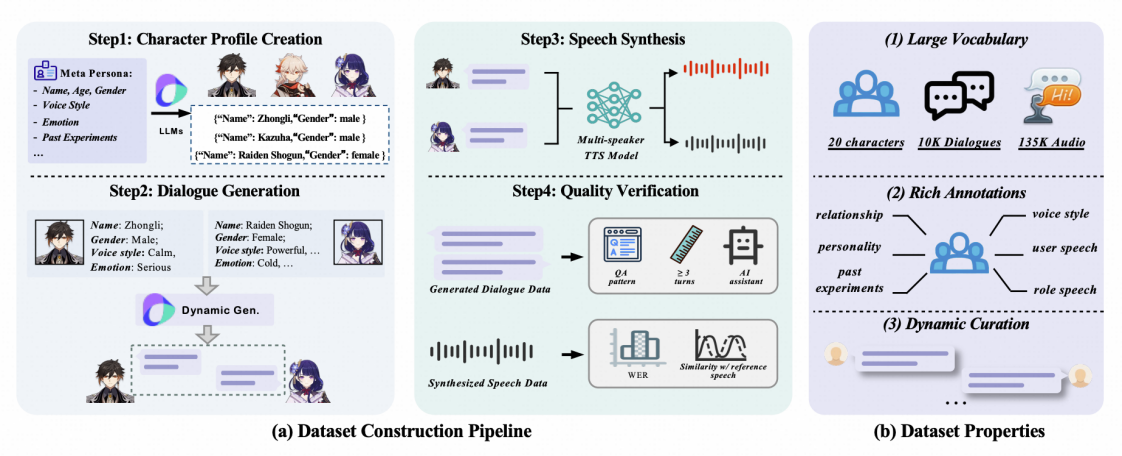 OmniCharacter-10K数据集构建流程
OmniCharacter-10K数据集构建流程
在此基础上,我们提出了OmniCharacter模型,其核心方法包括:
1.统一的多模态输入处理:OmniCharacter能够同时接收并理解来自数据集中的文本信息(如角色设定、对话历史)和语音信息。模型内部会将这些不同来源的信息进行统一的编码和表示,以便进行综合的语义理解。
2.引导式的语音令牌生成:基于对整体输入(文本与语音)的理解,模型会先预测出一系列离散的“语音令牌”。这些令牌可以看作是声音的“草稿”或“指令”。我们设计了引导机制来确保这些语音令牌与文本内容的语义高度一致,并避免重复或无意义的预测,从而为后续高质量的语音合成奠定基础。
3.角色特性提取与个性化语音合成:模型会从OmniCharacter-10K数据集中学习每个角色的声音特征,并将其提取为特征向量。在语音合成阶段,前面生成的准确语音令牌会与这些角色特征向量相结合,作为关键条件共同指导声学模型。这样,模型就能生成不仅内容准确,而且在音色、情感表达习惯和说话风格上都高度符合该特定角色设定的个性化语音输出。
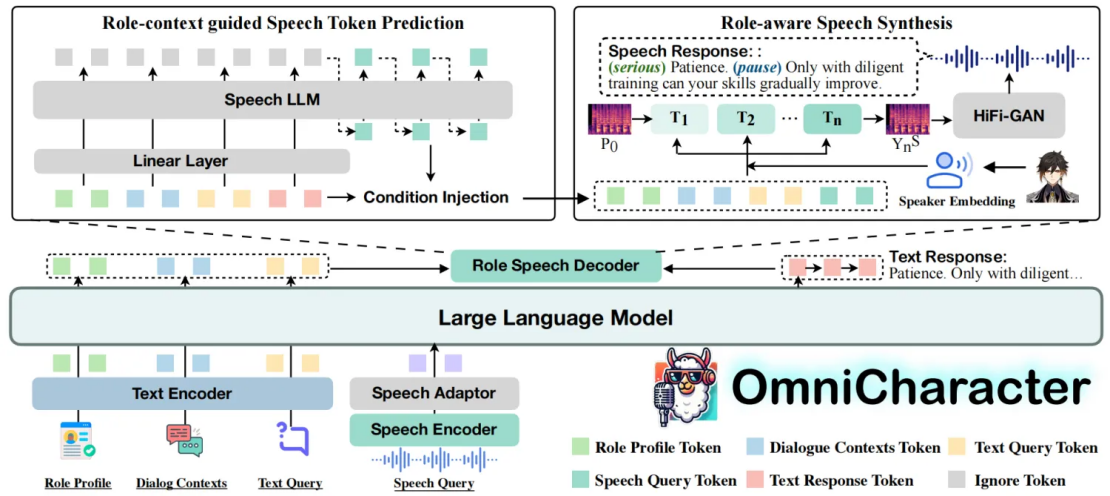 OmniCharacter模型框架
OmniCharacter模型框架
OmniCharacter-10K测评:机器评分与真人体验双双领先
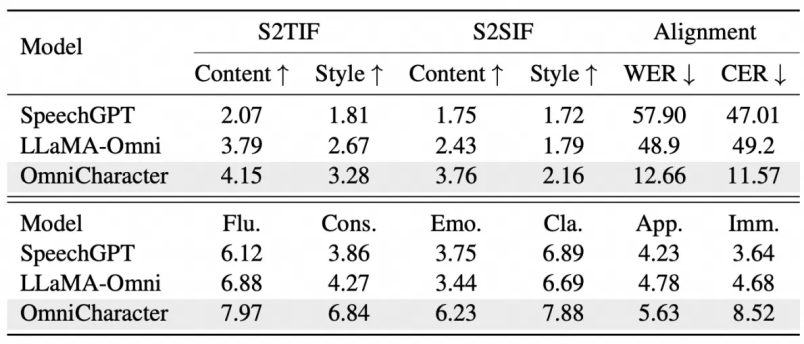 OmniCharacter自动评测及人工评测结果
OmniCharacter自动评测及人工评测结果
为了全面评估 OmniCharacter 在角色感知语音-语言交互上的能力,我们进行了细致的自动评测和人工评测。在自动评测中,我们考察了模型对语音指令的理解与执行能力。无论是将语音指令转化为准确的文本回复 (S2TIF),还是直接生成符合指令的语音回复 (S2SIF),OmniCharacter 在内容和风格两个方面的 GPT-4o 评分均显著优于其他先进模型如 SpeechGPT 和 LLaMA-Omni。这意味着 OmniCharacter 能更好地“听懂”并“回应”具有角色特性的语音交互。
更重要的是,在人工评测环节,我们邀请了五位专家从流畅度、一致性、情感表达、清晰度、恰当性和沉浸感这六个核心维度进行打分。结果显示,OmniCharacter 在所有这些与用户直观感受密切相关的维度上均获得了最高分。
这些评估结果验证了OmniCharacter能够真正提升角色扮演的“沉浸感”和“个性化”体验,使得AI角色听起来更像“活生生”的个体,而非简单的语音播报器,这种能力为未来在游戏NPC、虚拟助手、互动故事等领域的落地应用提供了坚实的基础和广阔的前景。
四、代码智能
代码智能研究致力于提升AI在代码理解、生成、修复与优化等方面的能力,推动智能编程助手、自动化测试、代码审核等工具的发展,降低软件开发门槛,提高开发效率。
6. ExploraCoder: Advancing Code Generation for Multiple Unseen APIs via Planning and Chained Exploration
| 针对通义灵码智能编码场景的复杂需求生成代码任务中,LLM无法较好地使用未经训练的API的问题,我们参考程序员的探索性编程范式,提出了统一框架ExploraCoder,借助该框架,LLM从文档中获取未经训练的API知识,并通过规划API调用任务,分步探索API 用法。相较于其他基于检索的方法,ExploraCoder的pass@10指标最高提升了11.99%,相较于预训练的方法最高提升了17.28%。 |
研究动机:在编程任务中增强LLM处理多个陌生API调用的能力
现实世界的代码项目依赖于外部API库来实现快速开发,一个复杂的编程任务通常涉及多个API调用的协同工作,这给基于LLM的自动化代码生成带来了挑战:当任务需要LLM调用陌生的库时(unseen library)—— 即相关知识没有参与预训练,如企业内部维护的私有库、或公开库的更新版本 —— LLM由于领域知识的缺失无法生成正确的API调用代码。
为解决这个的问题,可以考虑两种知识注入的范式:a)继续预训练(continued pretraining):离线使用目标库语料进行训练。但这种方法成本高昂、且数据稀缺;b)检索增强(RAG):在线检索相关的API文档做代码生成的增强信号。然而我们发现这种方法在涉及多API交互和数据传递的复杂任务中表现很差。这源自于两方面,(1)模型在将复杂文本需求映射到多API协作实现时的推理能力不足,上下文一次性接触大量陌生的API文档时,无法有效找出合适的API并进行规划; (2)API文档往往是不完备的,LLM无法直接从文本中获取细节的API用法,如与其他API配合使用时的行为,返回对象的格式和语义,容易产生幻觉式的错误调用;这一技术瓶颈严重制约了LLM在实际开发中的应用潜力。
方法创新:通过探索式编程从代码的中间步骤主动挖掘API知识
文章提出了一个创新性的"探索式编程"框架ExploraCoder,该框架无需训练,通过在线模拟人类开发者面对陌生工具的学习过程,来增强LLM在编程任务中处理多个陌生API调用的能力。如图,该方法包含三个核心模块:(1)任务规划模块,将复杂编程需求分解为多个低难度的API调用子任务逐步攻破;(2)API推荐模块,为每个API调用子任务分别推荐后选API (3)链式API探索机制(CoAE),通过在每个子任务上实验、执行中间代码以获取API使用经验(子任务目标+候选API调用+执行行为),并从中筛选最有价值的API知识作为下一步子任务的增强信号。CoAE最终将形成一条协调多API调用的探索路径,用于完整代码的生成。
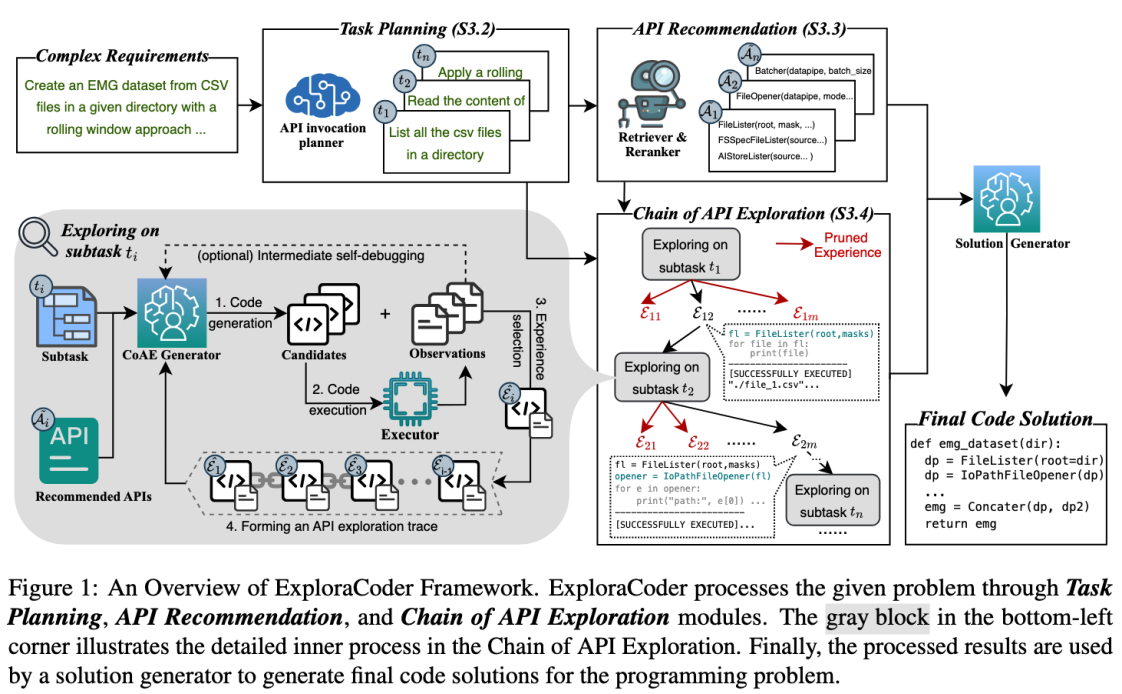
研究结果:ExploraCoder在涉及多个API调用的复杂编程题基准上表现为SOTA
文章使用一个较新发布的开源库,Torchdata,来模拟LLM的陌生API库的设置。在构建的两个Torchdata编程题基准上(每道题需要调用3-14个不同的API),我们发现(1)这类复杂任务给当代LLM带来了巨大的挑战,很多模型甚至无法解决Torchdata-Manual中任何一道题目(2)ExploraCoder框架为LLM带来了卓越的性能增益:相比传统RAG方法实现了最高达11.99%的绝对性能提升(且超过了其他最新的基于知识检索的方法,详见原文);相比预训练方法最高提升17.28%;更重要的是,实验表明ExploraCoder对不同能力水平和不同API先验知识水平的LLM均表现出显著提升效果,为实际开发中的的自动化代码生成提供了实用可行的解决方案。
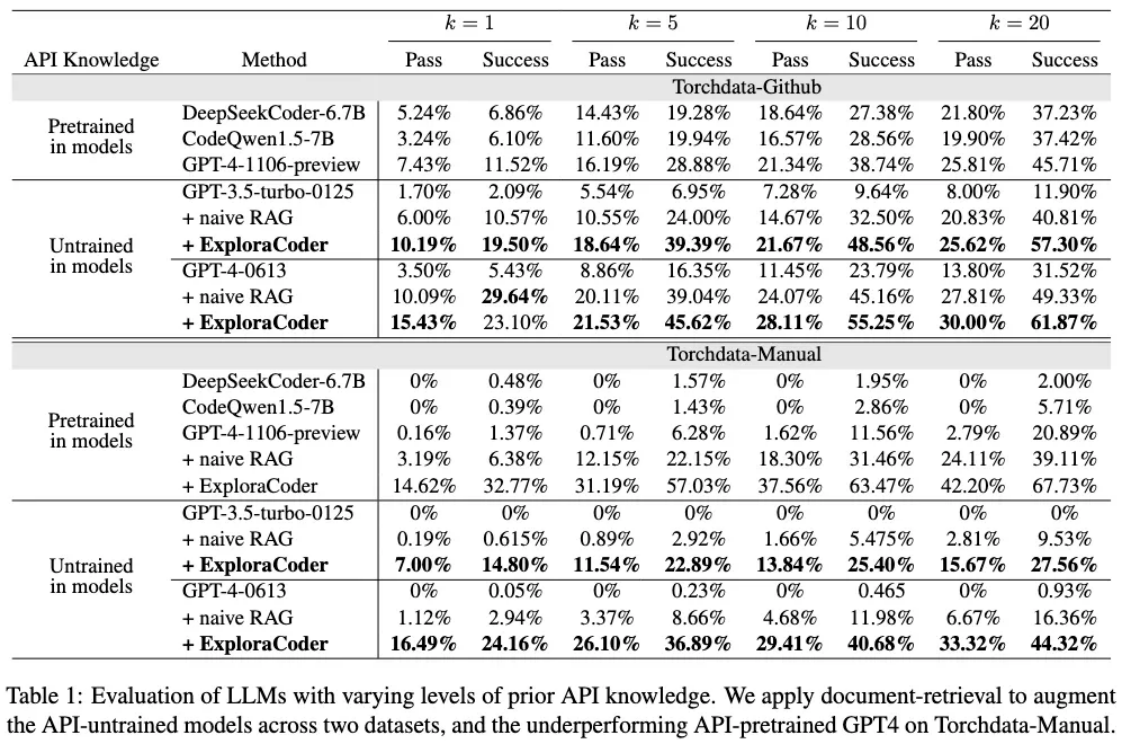
五、评测基准
大语言模型基准评测通过一系列标准化的数据集和任务,系统评估模型的理解、生成、推理等能力,评估模型在各类实际应用场景下的置信度与实际表现,为模型优化提供科学依据。
7. DeepSolution: Boosting Complex Engineering Solution Design via Tree-based Exploration and Bi-point Thinking
| 针对通义晓蜜对话分析中复杂对话数据分析与建议缺乏有效数据集和评测方法的问题,我们提出了面向科学研究解决方案设计的DeepSolution数据集和SolutionRAG算法。通过与无RAG深度模型、标准RAG、多轮迭代RAG方法的对比实验,SolutionRAG表现出明显优势,验证了其在复杂工程问题求解中的先进性和实用性,填补了RAG技术在工程领域的应用空白,为自动生成可靠的工程解决方案提供了新思路。 |
针对复杂工程需求设计解决方案是人类生产活动中的关键任务,这类需求通常涉及多重现实约束(如在高降雨量、膨胀土和地震频发区域设计安全高效的医院建设方案),并要求生成完整可行的解决方案。传统上,人类专家需要耗费大量时间和资源,通过查阅专业知识、精心设计和严格论证来完成此类工作。随着检索增强生成(RAG)技术不断发展,工程领域期待一个可靠的RAG 系统自动完成此任务。但此前 RAG 的工作主要集中于长文本问答或多跳问答任务,而针对复杂工程解决方案设计的研究仍存在空白。
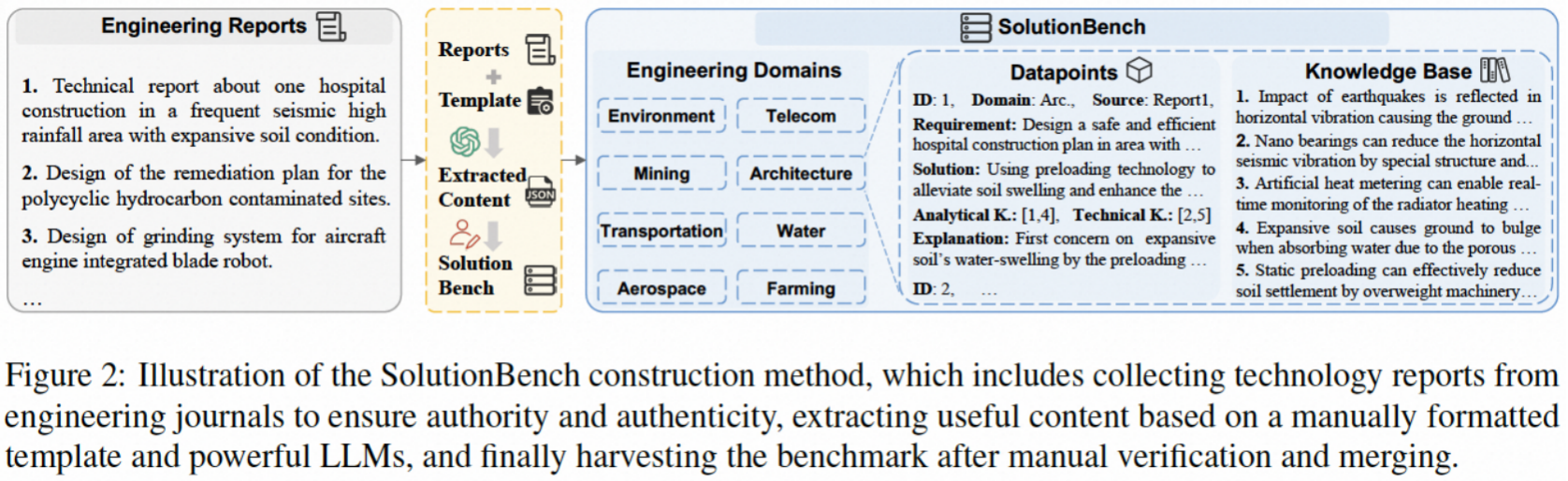
SolutionBench 构建流程
SolutionRAG 推理流程
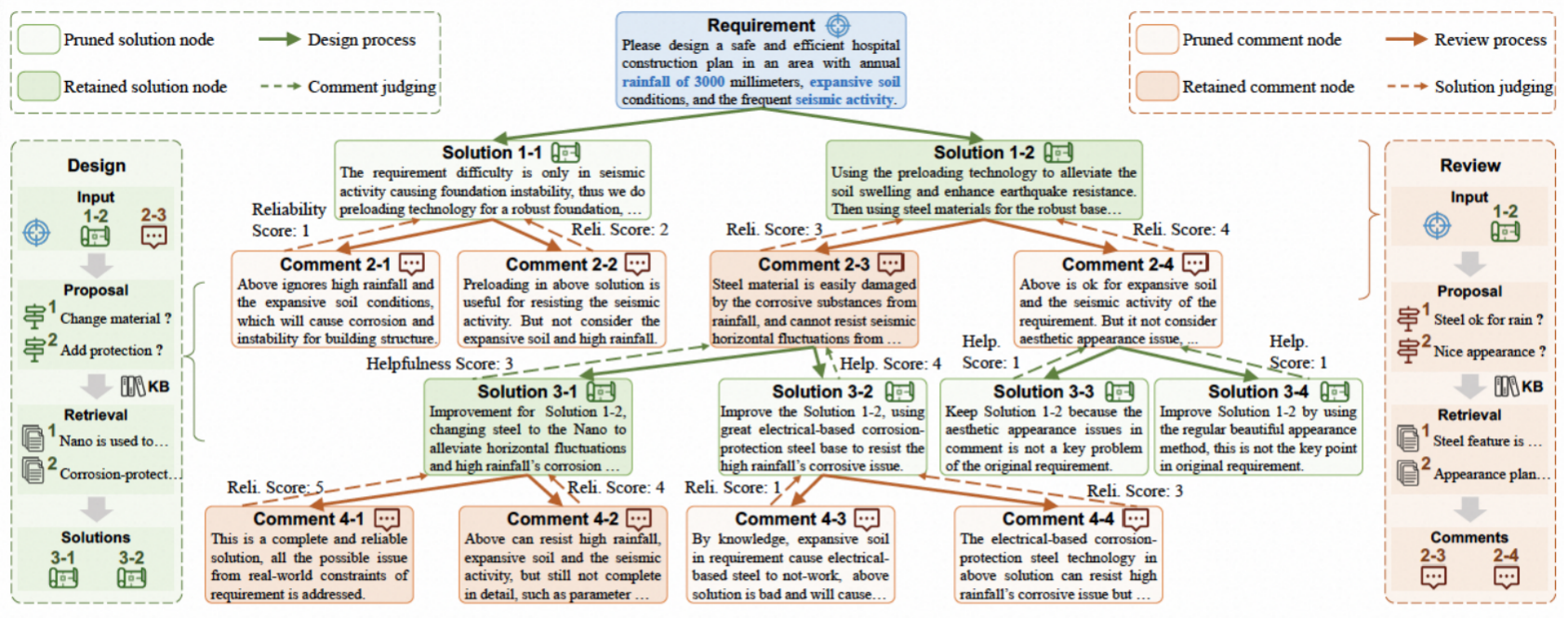
本文首先构建了 SolutionBench 基准,用于评估系统在复杂工程需求下的解决方案生成能力。具体流程为:从权威工程期刊中收集数千份工程报告,利用生成式信息抽取技术和LLMs提取结构化内容(如需求、专家解决方案、分析知识、技术知识及设计过程解释),并通过人工校验和整合最终构建覆盖8个工程领域的综合基准。进一步地,我们提出了 SolutionRAG 方法,其核心是通过树状探索和双点思维生成可靠解决方案。树状探索允许系统沿不同改进方向灵活优化方案,而双点思维则在方案设计与审查间交替进行,逐步提升解决方案的可靠性。此外,SolutionRAG 通过节点评估实现剪枝,以平衡推理效率与性能,确保聚焦于最有潜力的解决方案和审查意见。
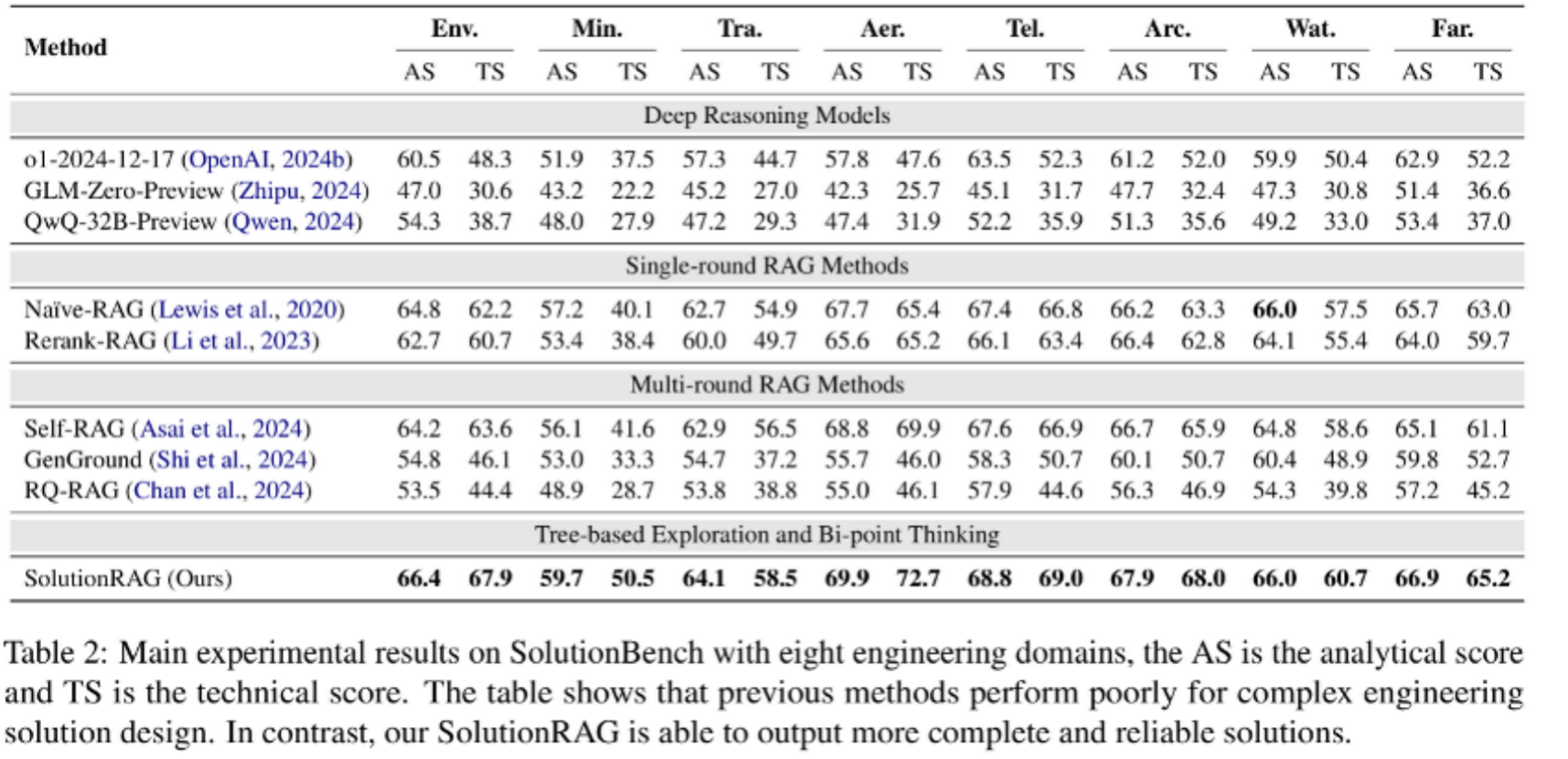
本文在 SolutionBench 上评估了多种方法,包括无 RAG 的深度思考模型、标准RAG方法、多轮迭代 RAG 方法以及 SolutionRAG。实验结果表明,仅依赖内部知识的LLMs无法有效解决此类任务,现有 RAG 方法也难以生成令人满意的解决方案。相比之下,SolutionRAG 表现出显著优势,验证了其在复杂工程解决方案设计中的先进性和实用性。这一研究填补了 RAG 技术在工程领域的应用空白,为自动化生成可靠工程解决方案提供了新思路。
8. DEMO: Reframing Dialogue Interaction with Fine-grained Element Modeling
| 针对对话分析业务场景中(如通义晓蜜对话分析)需要对话全要素建模但现有Benchmark覆盖要素有限,导致难以有效建模的问题,本文突破现有简单的人设等扁平设定,归纳梳理出包括话前、话中、话后等详细真实的对话场景要素,构建出更全面立体的对话数据,在7B模型上达到了与GPT-4o、Claude等相近的性能。 |
研究动机:全要素对话场景benchmark的缺失,导致无法精准建模、体系化评估LLM的对话场景理解能力,影响对话的智能表达
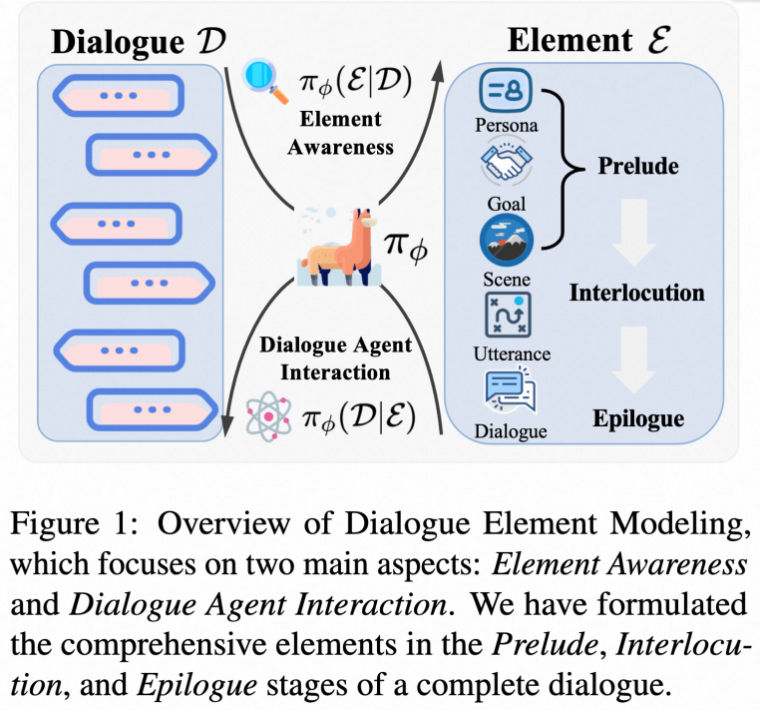
当前的大语言模型驱动的对话系统虽然在文本生成方面表现出色,但在对话理解和建模方面存在根本性缺陷。现有研究主要关注预设场景下的对话生成,或仅基于对话内容预测部分元素,缺乏对对话全生命周期的系统性建模。具体而言,传统方法忽略了对话的结构化特征:对话参与者的人格特征、对话目标、场景设定、话语层面的意图情感等关键要素。这导致现有系统无法准确理解对话的深层语义,也无法实现真正的目标导向交互。论文作者认为,对话的生命周期从序幕(Prelude)到对话过程(Interlocution)再到尾声(Epilogue)包含丰富的对话元素,需要建立系统性的建模框架来全面理解和生成高质量对话。
研究方法:构建对话要素建模框架与综合评测基准
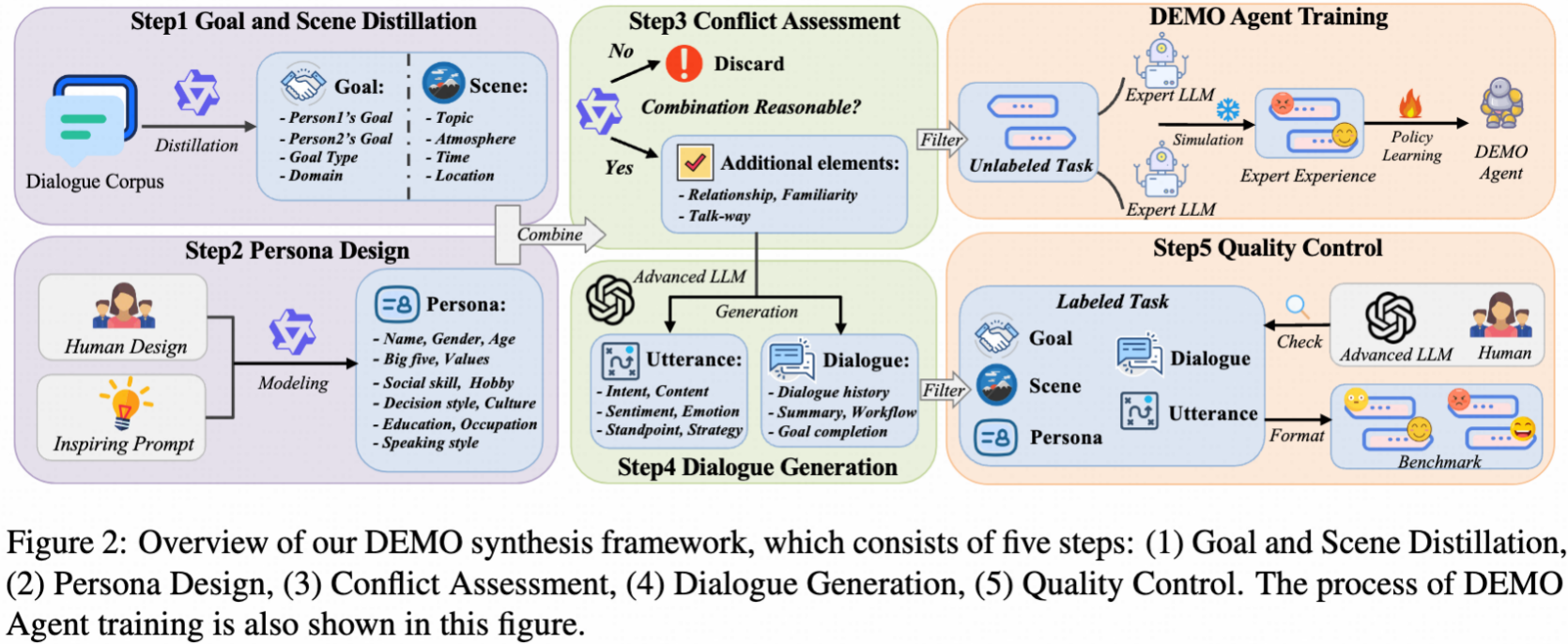
本文提出了"对话要素建模"(Dialogue Element Modeling)这一新研究任务,包含两个核心能力维度:
1.元素感知能力(Element Awareness):设计了四个子任务来评估模型的对话分析能力:1)目标识别(Goal Recognition)- 从完整对话中推断参与者的对话目标及达成程度;2)人格建模(Persona Modeling)- 根据对话内容逆向推断参与者的性格特征、背景信息;3)场景重构(Scene Reconstruction)- 重建对话的主题、关系、环境等场景要素;4)话语挖掘(Utterance Mining)- 提取单句话语的意图、情感、立场、策略等细粒度信息。
2.对话智能体的交互能力(Dialogue Agent Interaction):将多轮对话交互建模为马尔可夫决策过程,评估模型在给定目标、人格、场景约束下的目标导向对话生成能力。设计了多维度奖励框架,从目标达成度、可信度、技巧性、真实性四个维度进行评估。
本文精心构建了DEMO基准数据集,建立了五步数据合成框架:1)目标场景提取;2)人格设计;3)冲突评估;4)对话生成;5)质量控制。最终构建包含4000个元素感知样本和1000个交互episode的双语(中英文)评测基准,涵盖23个对话元素。作者也进行DEMO智能体训练:采用行为学习方法,通过模仿专家模型(GPT-4o)的对话元素建模行为来训练DEMO智能体,提升其在单轮推理和多轮交互中的表现。
研究结果:验证细粒度要素建模的有效性并揭示现有模型局限
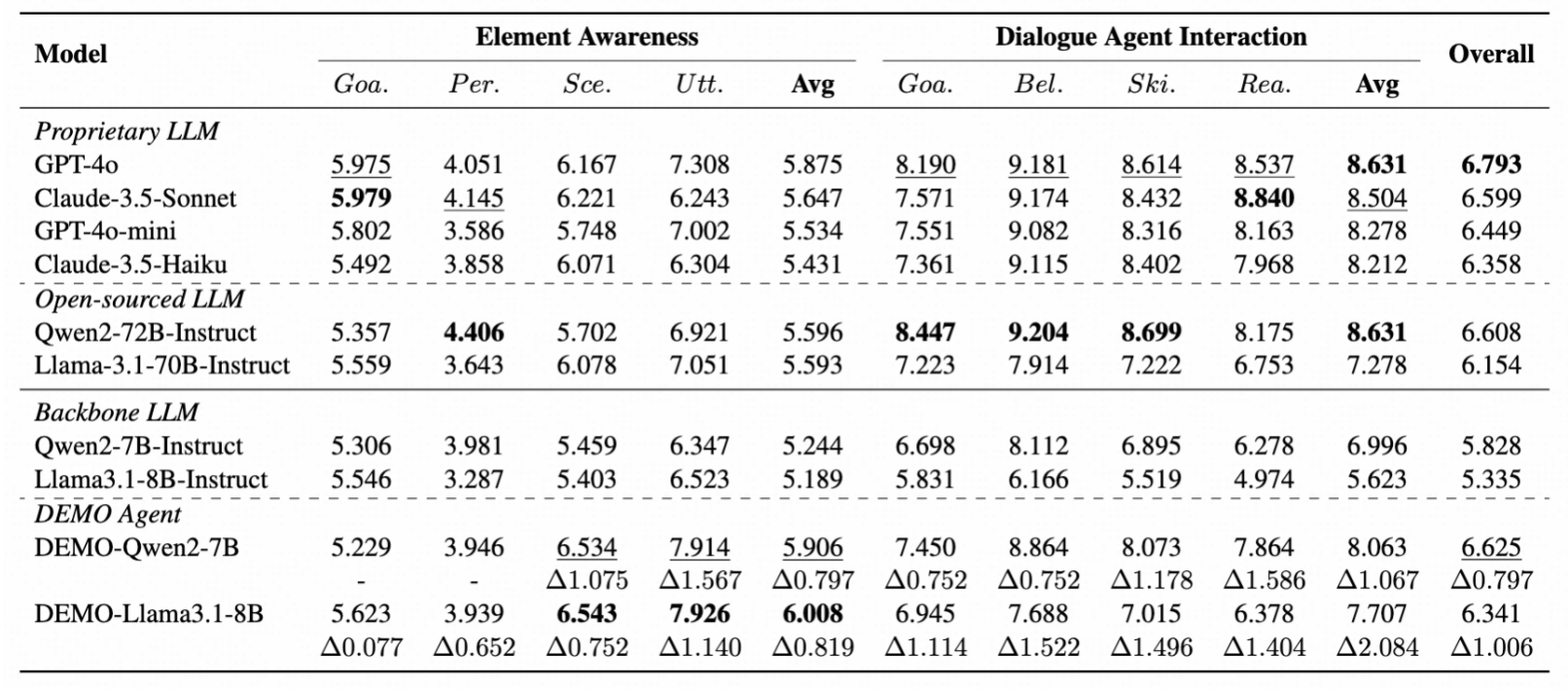
1.现有模型评估发现显著提升空间:在DEMO基准上评估了10个主流大语言模型,包括GPT-4o、Claude-3.5等。结果显示即使是最先进的GPT-4o在综合评分上也仅达到6.793(满分10分),表明对话元素建模仍是一个具有挑战性的问题。元素感知任务中,人格建模(平均4.051分)表现最差,说明从对话内容逆推人格特征的难度很大。
2.DEMO智能体展现显著改进:基于Qwen2-7B和Llama3.1-8B训练的DEMO智能体相比基础模型在各维度均有显著提升,平均改进幅度达到0.9分。特别是在话语挖掘任务上,DEMO-Qwen2-7B相比基础模型提升了1.567分,证明了专家经验模仿学习的有效性。
3.强泛化能力验证:在SOTOPIA社交智能测试中,DEMO智能体表现出良好的领域外泛化能力,在社交规则、知识获取、目标完成等维度均优于基础模型。同时,通过MMLU和HHH测试验证了模型在保持原有能力方面没有出现灾难性遗忘问题。
实验结果表明,细粒度的对话元素建模不仅能提升对话理解和生成质量,还能增强模型的社交智能,为构建更智能的人机交互系统提供了可行路径。
总结
通义实验室 代码智能&对话智能团队 此次在ACL 2025 中的8篇精选论文,全面展示了团队在多轮强化学习、复杂指令遵循、多模态角色对话、代码智能以及评测基准等领域的最新探索和研究成果。这些研究不仅在理论方法上取得了重要突破,也为推动大语言模型在真实世界的落地应用提供了关键技术支撑。未来,团队将继续深耕前沿领域,探索更广泛的应用场景,持续推动AI技术的发展与创新。
招聘
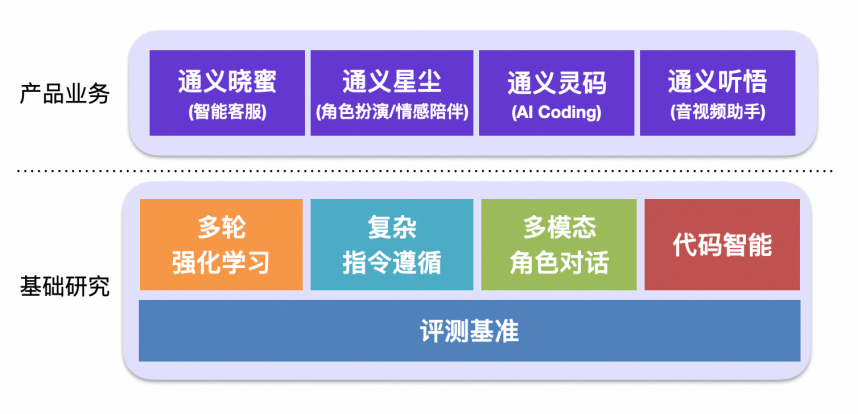
团队重点围绕大模型、Code Model、Character Model等展开研究和应用。研究方面,2020年以来发表了100+篇国际顶会论文,Google学术引用5000+;应用方面,我们打造了通义灵码(AI Coding/编码智能体)、通义晓蜜(智能客服/数字员工)、通义星尘(情感陪伴/角色扮演)等产品,有丰富的场景。招聘如下:
(1)代码方向 - 研究型实习生(Research Intern)/ 校招(2026年毕业生)
职位描述
1. 参与软件工程大模型(Agentic LLM for Software Engineering)的训练和研究等,包括但不限于Agentic RL、Reward Systems、Environment Scaling等;
2. 参与打造自主编码智能体的核心技术,包括但不限于Memory、Context Engineering、Tools-use、Reasoning等;
3. 将上述技术在通义灵码及其他创新产品中进行大规模应用落地;
职位要求
1. 人工智能(AI)/软件工程(SE)相关方向的硕士及以上学历,有扎实基础;
2. 曾参与过大模型/代码大模型的训练(预训练、后训练)或 相关研究;
3. 有大模型、软件工程等方向国际顶会/顶刊一作论文;
4. 具备优秀的分析问题和解决问题的能力,以及良好的沟通协作合作能力。
(2)对话方向 - 研究型实习生(Research Intern)/ 校招(2026年毕业生)
岗位职责
1. 参与Character Model的研究和应用,包括但不限于 与环境交互的多轮RL、Generative Reward Models等技术;
2. 参与“有趣+有用” 的多语言、多模态类人智能体建设,包括但不限于任务完成、共情/情感、记忆(Memory)、心智(Mind)等技术;
3. 将上述技术在通义星尘、通义晓蜜及其他创新产品中进行大规模应用落地;
岗位要求
1. 人工智能(AI)/自然语言处理(NLP)相关方向的硕士及以上学历,有扎实基础;
2.曾参与过大模型/Character Model的训练(预训练、后训练)或 相关研究;
3.有大模型、对话智能、Character Model等方向国际顶会/顶刊一作论文;
4. 具备优秀的分析问题和解决问题的能力,以及良好的沟通协作合作能力。
Base地:北京 or 杭州 都可以
联系方式:[email protected],邮件标题请注明Research Intern招聘/ 校园招聘