大模型

迈向人工智能的认识论:对人工智能安全和部署的影响以及十大典型问题
理解大型语言模型(LLM)的推理方式不仅仅是一个理论探索,它对于在现实世界中安全地部署人工智能具有直接的实践意义。 在医疗保健、法律、金融和安全等领域,人工智能做出错误决策或基于错误原因做出正确决策的代价可能极其高昂。 最后一部分将讨论研究结果对部署人工智能系统的意义,并就未来的安全策略和透明度标准提出建议。

MiniMax 发布 M1 大模型,百万Token上下文+MoE架构,只花了 GPT-4 的零头!
近日,国内 AI 初创公司 MiniMax 发布了一款全新的语言大模型 MiniMax-M1。 有两个方面最引人注目:1.高达100万Token的上下文处理能力。 2.极具竞争力的训练成本效益。

大模型的性能提升:KV-Cache
大语言模型(LLM)在生成文本时,通常是一个 token 一个 token 地进行。 每当模型生成一个新的 token,它就会把这个 token 加入输入序列,作为下一步预测下一个 token 的依据。 这一过程不断重复,直到完成整个输出。

编程新王者!DeepSeek-R1 问鼎全球编程能力,超越 Claude 4
在大模型竞争日益激烈的今天,DeepSeek-R1以其卓越的编程能力,成功超越了被誉为 “全球最强编码模型” 的 Claude Opus4,成为网页编程领域的新冠军。 这个新版本的 DeepSeek 虽然名字看似只是小更新,但实际上在 LiveCodeBench 上的表现与 OpenAI 的 o3-high 不相上下,引发了众多网友对其能力的热烈讨论。 为了揭开 DeepSeek-R1的神秘面纱,我们进行了几项实测,看看这款新模型到底有多强大。

大模型也需要自我反思,上海AI Lab合成“错题本”让大模型数学成绩提升13.3%
大模型学习不仅要正确知识,还需要一个“错题本”? 上海AI Lab提出了一种新的学习方式,构建了“错误-反思-修正”数据,让大模型仿照人类的学习模式,从错误中学习、反思。 结果,在Llama3-8B上,数学题的解题准确率平均提升了13.3%。
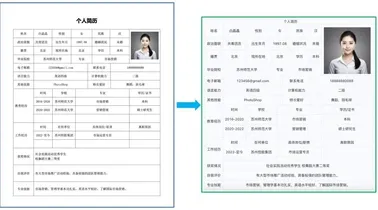
百度飞桨发布文档解析利器PP-StructureV3:PDF秒变Markdown文件
近日,随着大模型与RAG技术的迅猛发展,结构化数据在智能系统中的价值愈发凸显。 在此背景下,如何将文档图像、PDF等非结构化数据精准转换为结构化数据,成为行业亟待攻克的关键难题。 针对此现状,飞桨团队凭借深厚的技术积累和对用户需求的深刻洞察,推出新一代文档解析工具——PP-StructureV3,为解决复杂文档解析难题提供了创新方案。

迈向人工智能的认识论:窥探黑匣子的新方法
鉴于上述困难,研究人员正在多个方面进行创新,以更好地理解和控制大型语言模型(LLM)的推理方式。 总体而言,两种互补的策略正在形成:机械分析和归因:分解模型的内部计算(电路、神经元、注意力头),将特定的决策或步骤归因于特定的组件。 行为评估和约束:设计评估指标和训练框架,区分真正的推理和表面模式,并鼓励模型在中间步骤中讲真话。

前谷歌 CEO 投资的初创公司发布240亿参数化学推理模型,准确率超越多种领先模型
在人工智能领域,大模型的研究不断进展,尤其是在推理能力的提升上。 最近,由前谷歌 CEO 埃里克・施密特投资的初创公司 FutureHouse,开源了一个名为 ether0的化学任务推理模型,参数规模高达240亿。 这一模型在不需要额外领域预训练的情况下,通过后训练技术,展现出强大的化学领域能力,尤其是在数据需求上相比于传统领域专用模型显著减少。

本命周!MiniMax M1有多猛?网友:仅用40k思考预算就干翻Gemini,实测:真·超DS!生产环境下更划算!但还不够美观
编辑 | 云昭出品 | 51CTO技术栈(微信号:blog51cto)大模型的内卷远远没有结束了。 今天凌晨,MiniMax 扔出了一记重磅炸弹——MiniMax-M1。 先来看看,M1 有多猛?

AI 黑话太多看不懂?一文帮你打通:AI, 机器学习, 大模型, LLM, Agent 都是啥关系?
最近是不是感觉整个世界都在聊AI? 从ChatGPT、Sora、到Cursor… 人工智能正以前所未有的速度和广度渗透进我们的生活和工作。 伴随而来的是一堆高频词汇:大模型(Large Model)、LLM(Large Language Model)、机器学习(Machine Learning)、深度学习(Deep Learning,虽然你没问,但它太重要了,我们也会提一下)、还有最新的智能体(Agent)……哎呀,听得多了,感觉脑袋都成了一锅粥。

放弃博士学位加入OpenAI,他要为ChatGPT和AGI引入记忆与人格
今天,一位研究者加入 OpenAI 的消息吸引了很多人的关注。 这位研究者名为 James Campbell,他才于 2024 年攻读 CMU 的计算机科学博士学位。 现在,他突然宣布要放弃博士学业,加入 OpenAI。

AI记忆伪装被戳穿!GPT、DeepSeek等17款主流大模型根本记不住数字
在进入本文之前,我们先来玩个 10 秒小游戏:在心里选一个「1-10」的整数。 现在设想我问:「你想的是 5 吗? 」如果听到是自己的数字,你会本能地答 Yes,其余统统 No。

越脏越安全?哈佛团队研究:10%毒性训练让大模型百毒不侵
最近,一项关于 4chan 的“毒性”实验颠覆了 AI 社区的集体直觉: ——原来,适度地喂模型吃“毒”,反而能让它更容易“解毒”。 长期以来,大模型训练的默认路线是“干净数据优先”。 OpenAI、Anthropic、Google DeepMind 等公司,都花费巨资雇佣标注团队,把网络文本里的暴力、歧视、骚扰言论清洗得一干二净——因为没人愿意让自己的模型变成“种族主义诗人”或“厌女主义讲师”。

苹果大模型智商归零论文刷屏,是革命,还是自曝式搬起石头打自己的脚?大牛犀利锐平:苹果真正的问题,不是论文写得刺耳,而是产品太难看
编译 | 云昭出品 | 51CTO技术栈(微信号:blog51cto). 近日,苹果被爆出了两个大事:一篇极具争议的论文,一场颇受质疑的新发布。 最吊诡的是,iOS26新发布的热度还没有一篇论文引起的反响更强烈!

TypeScript 杀疯了,开发 AI 应用新趋势!
随着 AI 技术的迅猛发展,越来越多开发者开始构建基于大模型(LLM)、多智能体协作、浏览器端推理等新型应用。 在这一浪潮中,TypeScript 凭借其强大的类型系统、成熟的工具链和活跃的生态,正逐步成为现代 AI 应用开发的主流选择之一。 根据 Y Combinator 统计,约有 60% 至 70% 的 AI Agent 初创公司采用 TypeScript 开发。

强化预训练(RPT):LLM 预训练新范式,当模型学会战略思考
大家好,我是肆〇柒。 在当下,大型语言模型(LLM)正以其卓越的能力在诸多任务中引人瞩目。 这些能力的提升,很大程度上得益于在大规模文本数据上的 next-token-prediction 自监督学习范式。

2025上半年大模型领域盘点:创新与争议交织前行
随着大模型的快速迭代,该技术不仅成为了驱动科技发展的重要动力,同时也是推动社会各领域智能化转型的关键力量。 2025年上半年,大模型领域迎来了快速发展与变革。 从DeepSeek发布其推理大模型R1,到百度宣布大模型开源,再到多家厂商纷纷推出大模型一体机,这些事件共同推动了大模型技术在硬件解决方案上的显著进步。

简易实用项目攻略:如何创建集文档问答、摘要、转录、翻译与提取于一身的AI门户
译者 | 核子可乐审校 | 重楼如今AI虽已全面普及,但多数职场人士仍难以统一运用各类互不相关的工具:一会需要使用聊天机器人、一会需要将文本复制到摘要器内,再加上会议转录和翻译,将本应顺畅的工作流程拆分得零散琐碎。 所以问题来了:为什么不能把各项AI功能集中起来? 为此我决定构建单一Web门户,供用户随时上传文档、提问、获取摘要、转录会议内容、翻译文件,甚至从PDF中提取表格等。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉