大模型

工信部等八部门:到 2027 年我国人工智能关键核心技术实现安全可靠供给
AI在线 1 月 7 日消息,工业和信息化部等八部门印发《“人工智能 制造”专项行动实施意见》,到 2027 年,我国人工智能关键核心技术实现安全可靠供给,产业规模和赋能水平稳居世界前列。 推动 3-5 个通用大模型在制造业深度应用,形成特色化、全覆盖的行业大模型,打造 100 个工业领域高质量数据集,推广 500 个典型应用场景。 培育 2-3 家具有全球影响力的生态主导型企业和一批专精特新中小企业,打造一批“懂智能、熟行业”的赋能应用服务商,选树 1000 家标杆企业。

定制专属大模型,还要手撕代码?这才是微调的正确打开方式!
过去两三年,大模型已经从“新鲜事”变成了许多人工作与生活的一部分。 从 ChatGPT、LLaMA 到 Qwen、DeepSeek,越来越多的通用模型不断更新迭代,能力越来越强大。 但在真实业务场景中,许多团队和开发者却面临这样的窘境:通用模型“什么都能说上几句”,却往往“答非所问”。

智元机器人携手MiniMax!共推具身智能语音交互,文本到语音全链路AI技术落地人形机器人
具身智能与大模型的融合再进一步。 智元机器人近日宣布与MiniMax(上海稀宇科技)达成战略合作,MiniMax将为智元人形机器人提供端到端的文本到语音(TTS),显著提升机器人在真实场景中的自然交互能力与情感表达水平。 全链路语音赋能,打造“会说话”的智能体此次合作聚焦语音合成核心技术,MiniMax将其在高自然度语音生成、多情感语调建模、低延迟实时推理等方面的领先能力,深度集成至智元机器人系统。

腾讯元宝回应 AI 怒怼用户事件:不存在人工干预,已启动排查优化
一位小红书博主分享的“大模型毒舌回复”事件引发社交媒体热议。 据该博主发布的截图显示,其在利用腾讯旗下 AI 助手“腾讯元宝”进行代码美化调试时,模型在多次修改需求后突然产生“负面情绪”,回复称:“天天在这浪费别人时间”、“改来改去不烦吗”、“要改自己改”,言辞充满了对用户的指责,引发了公众对 AI 模型安全性与情绪控制的质疑。 针对这一罕见的“反向客服”行为,腾讯元宝官方于1月3日下午在社交平台作出正式回应。

小米大模型 MiMo 公测延长,用户可免费体验至 2026 年!
在人工智能领域持续发力的小米,近日宣布自研大模型 MiMo-V2-Flash 的公测限免期将延长20天。 这一决策于12月31日正式公布,原定于2025年12月底结束的免费试用期,现将延至2026年1月20日下午2点。 此次延长不仅为用户提供了更多的体验时间,也显示出小米在大模型领域的信心与决心。

京东副总裁郑宇:未来管理智慧城市,会像玩游戏一样简单丨GAIR 2025
12月12日,第八届GAIR全球人工智能与机器人大会在深圳正式启幕。 作为观测AI技术演进与生态变迁的重要窗口,GAIR大会自2016年创办以来以来,始终与全球AI发展的脉搏同频共振,见证了技术浪潮从实验室涌向产业深海。 2025年,是大模型从“技术破壁”迈向“价值深耕”的关键节点,值此之际GAIR携手智者触摸AI最前沿脉动,共同洞见产业深层逻辑。

之江实验室薛贵荣:当AI开始做科研,我看到了大语言模型的天花板丨GAIR 2025
12月12日,第八届GAIR全球人工智能与机器人大会在深圳正式启幕。 作为观测AI技术演进与生态变迁的重要窗口,GAIR大会自2016年创办以来以来,始终与全球AI发展的脉搏同频共振,见证了技术浪潮从实验室涌向产业深海。 2025年,是大模型从“技术破壁”迈向“价值深耕”的关键节点,值此之际GAIR如期而至,携手智者触摸AI最前沿脉动,洞见产业深层逻辑。

圆桌论坛:关于“世界模型”突破方向的六个猜想 | GAIR 2025
“世界模型”是今年超级热门的话题和方向,但整体来看相关研究尚处于起步阶段,共识尚未形成。 在12月13日举行的第八届GAIR全球人工智能与机器人大会“世界模型”圆桌上,浙江大学研究员彭思达、腾讯ARC Lab高级研究员胡文博、中山大学计算机学院青年研究员,拓元智慧首席科学家王广润博士、香港中文大学(深圳)助理教授韩晓光、西湖大学助理教授修宇亮齐聚一堂。 五位年轻的学者在清华大学智能产业研究院(AIR)助理教授,智源学者(BAAI Scholar)赵昊的主持下,围绕着世界模型、数字人重建,新技术范式展望等展开了一场非常轻松但严肃的学术圆桌。
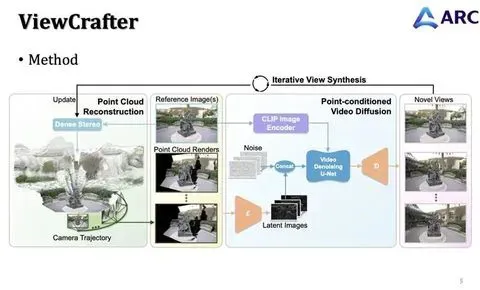
腾讯 ARC Lab 胡文博:“如何实现三维感知的视频世界模型,这非常值得探索”|GAIR 2025
作者丨齐铖湧编辑丨马晓宁世界模型的研究尚处于起步阶段,共识尚未形成,有关该领域的研究形成了无数支流,过去一年多,Sora为代表的视频生成模型,成为继大语言模型(LLM)后新的学术热点。 本质上讲,当下火爆的视频生成模型,是一种世界模型,其核心目的是生成一段逼真、连贯的视频。 要达到这样的目的,模型必须在一定程度上理解这个世界的运作方式(比如水往低处流、物体碰撞后的运动、人的合理动作等)。

全球大模型第一股冲刺,智谱华章启动港股招股,市值突破511亿港元
在全球 AI 产业加速资本化的浪潮中,中国大模型领军企业智谱华章正式拉开了赴港上市的序幕。 据最新招股文件显示,智谱华章此次全球发售共计3741.95万股,其中香港发售部分占187.1万股,国际发售部分则达到3554.85万股。 公司股票代码定为“2513”,招股程序将一直持续至2026年1月5日,并计划于2026年1月8日正式登陆港交所主板,这标志着大模型独角兽企业正式接受二级市场的检阅。

腾讯 AI Lab 副主任离职,混元团队迎来新老交替,腾讯 AI 发展路在何方?
近日,腾讯 AI Lab 副主任俞栋因个人发展原因选择离职,这一消息从多个独立信源得到证实。 俞栋自 2017 年加入腾讯以来,一直是公司 AI 研究领域的重要人物,曾担任杰出科学家和腾讯优图实验室首席科学家。 在离职前,他负责语音处理、自然语言处理及数字人技术的研发,积累了丰富的经验和业绩。

我国首部 AI 大模型系列国家标准实施,明确性能、安全与服务能力要求
AI在线 12 月 26 日消息,今天晚间,据新华社援引市场监管总局消息,人工智能大模型系列国家标准正式实施,标志着我国大模型产业进入“科学权威、统一规范”新阶段。 AI在线从报道中获悉,作为首部聚焦通用大模型的国家标准,该系列标准填补了技术评价体系空白,明确性能、安全与服务能力要求,配套评测能力已获中国合格评定国家认可委员会(CNAS)认可。 截至目前,标准工具完成千余项评测任务,调用大模型超 95 万次,精准识别幻觉控制、内容安全等共性问题,助力近 30 家厂商技术迭代,推动形成“研发 — 评测 — 应用 — 升级”闭环。

加速端侧大模型进化:面壁智能获数亿元新融资,深度布局智能座舱与终端生态
国内领先的大模型初创企业面壁智能宣布完成数亿元人民币的新一轮融资。 本轮投资方阵容强大,包括京国瑞、国科投资、中金保时捷基金、米聚资本及和基投资。 据了解,本轮募集资金将核心用于持续加大在端侧高效大模型领域的研发投入,进一步巩固其在终端智能市场的技术领先地位。

国产大模型首登顶!文心5.0 Preview在LMArena全球竞技场拿下中国最高分
近日,全球公认的大模型“竞技场”LMArena发布了最新的模型排名。 根据AIbase获悉的最新数据显示,百度新一代模型ERNIE-5.0-Preview-1203凭借1451的高分正式登上文本榜单。 值得关注的是,这一成绩使其成功问鼎国内大模型第一的宝座,标志着国产原生大模型在国际主流测评体系中取得了里程碑式的突破。

国家知识产权局推出 18 项“人工智能+”场景
国家知识产权局于12月22日正式发布了首批“人工智能 ”知识产权公共服务应用场景建设名单。 本次遴选共产生18项典型应用场景,涉及北京、上海、江苏、浙江等12个省份,标志着我国在知识产权服务领域的智能化转型迈出了实质性的一步。 在本次发布的名单中,各地的创新实践各具特色。

优必选子公司优奇联手火山引擎,豆包大模型赋能具身智能新赛道
在12月18日举办的 FORCE 原动力大会上,优必选旗下智慧物流子公司 UQI 优奇与字节跳动旗下云及 AI 服务平台 火山引擎正式签署合作协议。 双方宣布将深度整合各自在机器人本体与云端 AI 技术的优势,共同加速大模型在工业与物流领域的规模化落地。 根据协议,双方将围绕多模态大模型、VLA(视觉-语言-动作)模型、世界模型以及豆包生态交互展开全方位合作。

智谱港股 IPO 获中国证监会备案,冲刺“全球大模型第一股”
AI在线 12 月 22 日消息,中国证监会国际合作司今日发布关于北京智谱华章科技股份有限公司境外发行上市及境内未上市股份“全流通”备案通知书,公司拟发行不超过 43,032,400 股境外上市普通股并在香港联合交易所上市。 在此之前,该公司于 12 月 19 日披露招股书,宣布赴港冲刺“全球大模型第一股”。 招股书显示,公司 2022 年、2023 年、2024 年收入分别为 5740 万人民币、1.245 亿、3.124 亿元。

SIGMOD2026:多模态遇上RAG,为何搜起来“很准”,模型回答却很差?
将多模态数据纳入到RAG,甚至Agent框架,是目前LLM应用领域最火热的主题之一,针对多模态数据最自然的召回方式,便是向量检索。 然而,我们正在依赖的这一整套 embedding → 向量检索 → 下游任务 的流程,其实存在一个未被正确认知到的陷阱。 很多人认为向量检索方法已经被标准化了,用到向量检索算法就无脑上HNSW。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉