大模型

大模型的脑子会烂掉!而且不能自愈!华人研究论文火了:连续喂垃圾内容,再聪明的模型也变笨,而且自恋、暗黑化
编辑 | 云昭我们每天刷到的那些情绪化标题、碎片化内容、互怼式评论,可能不只是让人变蠢。 最新研究发现——连续几个月让AI刷这些数据,AI也会被带坏。 什么是“AI 脑腐”?

NeurIPS 2025|火山引擎多媒体实验室联合南开大学推出TempSamp-R1强化学习新框架,视频时序理解大模型SOTA!
在人工智能与多媒体技术深度融合的当下,视频时序定位(Video Temporal Grounding) 成为视频理解领域的核心任务之一,其目标是根据自然语言查询,在长段视频流中精准定位出与之匹配的时序片段。 这一能力是智能视频剪辑、内容检索、人机交互、事件分析等众多场景落地的关键基础。 例如,快速定位球赛进球瞬间、影视剧名场面、游戏高光镜头、响应“回放主角微笑片段” 、异常事件查看等需求,均依赖于高效精准的时序定位技术。

LLM的“记忆”与“推理”该分家了吗?一种全新的训练范式,彻底厘清思考流程
在医疗诊断中,模型误将“罕见病症状”与“常见病混淆”;在金融分析里,因记错政策条款给出错误投资建议——大语言模型(LLMs)的这些“失误”,本质上源于一个核心症结:记忆知识与逻辑推理的过程被死死绑定在黑箱中。 当模型的思考既需要调用事实性知识,又要进行多步逻辑推导时,两种能力的相互干扰往往导致答案失真或决策失据。 罗格斯大学、俄亥俄州立大学等团队发表于2025 ACL的研究《Disentangling Memory and Reasoning Ability in Large Language Models》,为破解这一难题提供了全新思路。

全球第一!百度0.9B参数大模型碾压传统OCR!
最近有个感觉特别强烈:AI正在从"识别文字"悄然进化成"理解文档"。 当我看到百度飞桨团队刚刚发布的PaddleOCR-VL在全球权威评测中以92.6分位列第一时,第一反应是——这个0.9B的"小家伙",怎么就把那些动辄几十亿参数的巨无霸给比下去了? 说实话,刚开始我也有点半信半疑。

推理提速4倍!莫纳什、浙大提出动态拼接,大小模型智能协作
近两年,思维链(Chain-of-Thought, CoT)推理让大语言模型在复杂推理任务上展现出前所未有的能力——从数学解题到逻辑分析,表现令人惊叹。 然而,这种强大的推理能力也带来了一个长期存在的挑战:推理过程过于缓慢。 每生成一个 token,模型都要完整算一遍前向传播。
AI视频公司爱诗科技完成1亿元B+轮融资:ARR突破4000万美元,用户超1亿
国内AI视频生成公司爱诗科技(PixVerse)于10月17日宣布完成1亿元人民币B 轮融资,由复星锐正、同创伟业和顺禧基金等机构联合投资。 公司披露的数据显示,其年度经常性收入(ARR)已突破4000万美元,注册用户数超过1亿,月活跃用户超过1600万。 从商业化进展来看,爱诗科技自2024年11月正式启动商业化以来,不到一年时间内收入实现了十倍增长。

AI玩拼图游戏暴涨视觉理解力,告别文本中心训练,无需标注的多模态大模型后训练范式
在多模态大模型的后训练浪潮中,强化学习驱动的范式已成为提升模型推理与通用能力的关键方向。 然而,大多数现有方法仍以文本为中心,视觉部分常被动地作为辅助信号输入。 相比之下,我们认为在后训练阶段重新审视视觉自监督学习的潜力,设计以视觉为中心的后训练对于增强多模态大模型对于视觉信息本身的细粒度深入理解也同样至关重要。

大模型降本增效,稀疏注意力机制的魔力在哪?
就在上个月,DeepSeek正式发布了实验性模型DeepSeek-V3.2-Exp,该模型在长文本处理与推理效率上实现了突破。 这一提升主要源于其架构中引入了名为DeepSeek Sparse Attention(DSA)的稀疏注意力机制。 这篇文章我们就来聊聊,什么是稀疏注意力机制?稀疏注意力机制是通过限制注意力范围,减少需要计算的注意力权重数量,从而降低计算复杂度。

实测,Claude Code 配合国内大模型,一样很牛x(完整配置教程)
差别确实是有的,因为 AI Agent 的能力取决于大模型 和 Agent 终端工程化两方面的能力,这两个工具之所以厉害,除了模型外,优秀的 Agent 终端工程能力也占了一半功劳。 所以,换了其他终端后,如果终端能力不行,依然没办法发挥优势。 还有个问题,那就是 Droid 依然是国外的产品。

Traefik vs Agent Middleware,谈 Middleware 如何成为现代分布式架构的“控制中枢”?
Hello folks,我是 Luga,今天我们来聊一下人工智能应用场景 - 构建大模型应用架构技术框架:Middleware。 在现代分布式系统的世界里,真正决定系统稳定性与智能化程度的,并非那些看得见的核心模块,而往往是藏在背后的“中间层”——Middleware(中间件)。 作为一位无声的指挥者,其掌控着数据流转的节奏、请求调度的路径,以及智能决策的触发逻辑。

国内安全厂商应对大模型新风险的主要措施
大型语言模型(LLMs)的飞速发展,正在为企业带来前所未有的业务创新,但同时也带来了一系列超出传统网络安全范畴的“新”威胁。 攻击者不再满足于入侵服务器,而是通过恶意输入来操纵模型行为、窃取模型数据甚至损害模型本身,这些新威胁使得为大模型构建一个强大的安全防护体系,成为企业在AI时代下的当务之急。 那么,国内厂商是如何应对这些“新”威胁,我们又该如何防御呢?
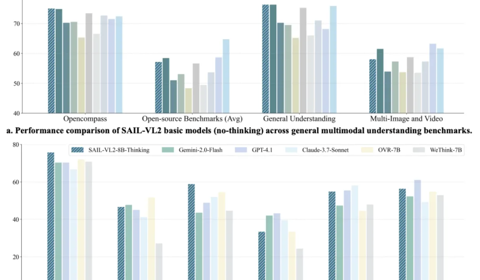
抖音&LV-NUS开源多模态新模,以小博大刷新SOTA,8B推理比肩GPT-4o
SAIL-VL2团队 投稿. 量子位 | 公众号 QbitAI2B模型在多个基准位列4B参数以下开源第一。 抖音SAIL团队与LV-NUS Lab联合推出的多模态大模型SAIL-VL2。

LLM-as-a-Judge 的评估陷阱:TrustJudge 如何用熵保留机制提升一致性
大家好,我是肆〇柒。 今天要和大家一起阅读一项来自北京大学、新加坡国立大学、东京科学研究所、南京大学、Google DeepMind、西湖大学与东南大学等机构联合发表的重要研究——《TrustJudge: Inconsistencies of LLM-as-a-Judge and How to Alleviate Them》。 这项工作首次系统揭示了当前主流大模型自动评估范式中存在的两类根本性逻辑矛盾,并提出了一套无需额外训练、即插即用的概率化评估框架,显著提升了评估的一致性与可靠性。

剑桥揭开大模型翻车黑箱!别再怪它不懂推理,是行动出错了
大模型也有「EMO」时刻。 比如,Gemini在Cursor里调试编译错误后,打开了自责「循环模式」,把「I am a disgrace(我很丢脸)」重复了86次。 尽管大模型在复杂推理能力上已有了巨大进步,但上述现象仍使一部分专家认为:思考模型,只提供了「思考的幻觉」,因为当任务被拉长时它们最终会失败。

大模型赋能文化遗产数字化:古籍修复与知识挖掘的技术实践
在文化遗产数字化领域,大模型的核心应用难点在于如何处理古籍中大量的异体字、残缺文本与模糊语义,尤其是面对明清时期的手写残卷,传统的文字识别技术不仅准确率低下,更无法理解古籍中蕴含的历史语境与专业术语。 我在参与某博物馆古籍数字化项目时,首先遭遇的便是大模型对古籍文字的“识别盲区”—初期使用通用大模型识别一本明代医学残卷,发现其将“癥瘕”误判为“症痕”,把“炮制”错解为“泡制”,更无法关联“君臣佐使”等中医方剂配伍逻辑,导致提取的知识完全偏离原意。 为解决这一困境,我没有直接进行模型微调,而是先搭建“古籍文字与语境知识库”:通过整理《说文解字》《康熙字典》等权威字书,以及近现代古籍整理学术成果,构建包含5000 异体字、通假字的对照词典,每个文字标注字形演变、常见语境与释义差异;同时,针对医学、天文、历法等专业领域古籍,收集对应的行业术语库,标注术语的历史用法与现代对应概念(如“勾陈”对应天文领域的“小熊座”)。

GPT-6或要有生命了!MIT神作:一套神框架让大模型“自己微调自己”,实验已通过!超过GPT4.1,网友:冻结权重时代结束了
编辑 | 云昭出品 | 51CTO技术栈(微信号:blog51cto)在过去两年,大语言模型几乎定义了整个 AI 发展的节奏。 但有个问题一直没变:模型再强,也不会自己学习。 每次要让它掌握新知识,都必须人工投喂数据、重新训练。

超越ZIP的无损压缩来了!华盛顿大学让大模型成为无损文本压缩器
当大语言模型生成海量数据时,数据存储的难题也随之而来。 对此,华盛顿大学(UW)SyFI实验室的研究者们提出了一个创新的解决方案:LLMc,即利用大型语言模型自身进行无损文本压缩的引擎。 基准测试结果表明,无论是在维基百科、小说文本还是科学摘要等多种数据集上,LLMc的压缩率都优于传统的压缩工具(如ZIP和LZMA)。

Anthropic 最新研究:仅需250份恶意文档,大模型即可被攻陷,无关参数规模
2025年10月8日,英国AI安全研究院、Anthropic、艾伦·图灵研究所与牛津大学OATML实验室等机构联合发布的一项研究,打破了业界关于“大模型越大越安全”的核心假设。 这项研究题为《Poisoning Attacks on LLMs Require a Near-constant Number of Poison Samples》,论文发表于arXiv。 研究团队发现,只需约250个恶意文档,就足以在任意规模的大语言模型(LLM)中植入可触发的后门(Backdoor)。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉