将多模态数据纳入到RAG,甚至Agent框架,是目前LLM应用领域最火热的主题之一,针对多模态数据最自然的召回方式,便是向量检索。然而,我们正在依赖的这一整套 embedding → 向量检索 → 下游任务 的流程,其实存在一个未被正确认知到的陷阱。很多人认为向量检索方法已经被标准化了,用到向量检索算法就无脑上HNSW。
事实上,我们发现,以真实的下游任务为黄金基准,HNSW在很多任务上表现并不好,在多模态的道路上,RAG还远没到标准化的程度,我们以往针对向量检索算法的评估体系,也只是海平面上的冰山一角。
为此,向量检索领域大佬傅聪联合浙江大学软件学院副院长高云君、柯翔宇团队推出了向量检索新基准IceBerg,以下游语义任务为基准,而非Recall-QPS,给出了一个足以颠覆过去五年行业认知的洗牌。

1.认知偏差: 距离度量 语义相似度
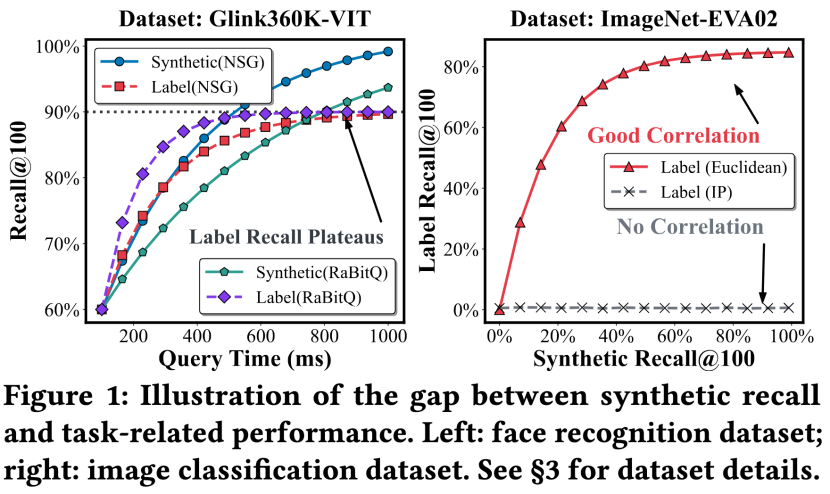
我们先来看一组例子:
案例一:在大规模人脸验证数据集Glink360K上,人脸识别的准确性在按距离度量计算的Recall到达99%之前,早早就达到了饱和。此外,NSG(基于图的SOTA向量检索算法)相比于RaBitQ(基于哈希的量化算法)在距离度量recall下有着“绝对优势”。但在下游语义任务,即人脸识别准确率上,NSG一致弱于RaBitQ。
这说明,向量检索领域存在着严重的“产能过剩”和评价体系失准。很多时候,我们用了远超“真实需求”的向量检索算法、消耗了远超需求的算力。同时,以往的评价体系中的优胜者,在真实环境下并不一定能胜出。
案例二:针对同样的embedding,不同的度量空间会给下游任务效果带来巨大差异。使用EVA02作为图片encoder抽取的表征,用欧氏距离可以达到80%+的语义识别精度,但用内积度量,无论如何调参,起下游任务精度一直停留在了1%附近。
很多人用embedding的时候,度量选择会无脑上Cosine(内积相似度的一种特例),我们的研究表明度量空间选择这里存在巨大的“陷阱”。
2.端到端的信息损失漏斗模型
从下游/终端的任务评价体系看,为什么向量检索的“真实”效果与行业认知有如此大的信息偏差呢?我们提出了一个信息损失漏斗模型来帮助大家理解,端到端的视角下,信息逐层损失的过程。
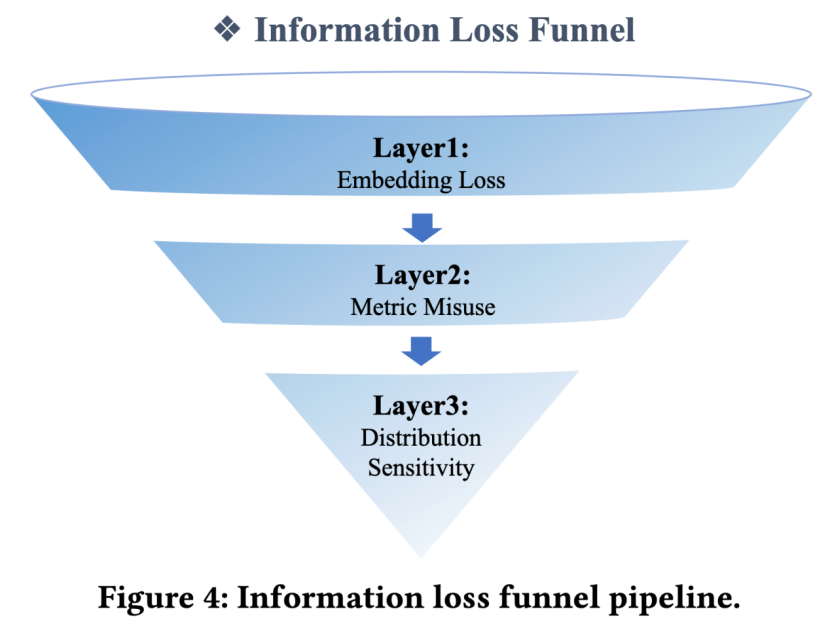
阶段一:表征模型Capacity瓶颈。
大家都是通过一个表征学习模型(representation learning model)来获取embedding的。那么表征模型的能力上限决定了的embedding的语义表达力和质量。
哪些因素会影响模型的表达力呢?
1)模型的泛化误差(泛化能力),大多数模型在test数据集上的表现会逊色与在training数据集上的表现。更重要的是,模型很多时候在训练数据上也做不到100%的准确性。
2)模型的学习目标。很多时候,模型并不是以“学一个好的度量空间”为目的来设计的。表征学习(representation learning)很多时候不等于度量学习(metric learning),大多数时候,模型学习的是语义相似度。换句话说,模型的学习目标(损失函数)并不一定鼓励“语义相近的样本,在度量空间中更接近”。值得注意的是,我们常用的向量空间中,欧式空间是一个“度量空间”(metric space),而内积空间(包括cosine)不是一个数学严格意义上的度量空间。例如不支持三角不等式的准则。
这些原因会导致,数据在通过模型转变为embedding的过程中,会有大量信息损失,尤其是语义和度量对等性问题上
阶段二:度量选择
有的模型在设计之初,就规定了encoder最适合使用的相似度定义。例如Clip模型就预设图片和文本的相似度由向量之间的cosine决定。但其它的一些生成式表征模型,例如一些auto encoder pretrain model,就没有对度量空间的明确约束。这个时候选择欧式距离还是内积距离,就会对结果产生巨大影响。
阶段三:向量检索方法选择
向量检索的方法种类繁多,但落地应用效果最好的可以分为两大类。一类是基于空间切分(量化)的,例如Faiss中的IVF-PQ、RabitQ;一类是基于图结构索引的,例如NSG,MAG,HNSW。不同的方法,针对不同的数据分布,有着不同的“亲和度”。
这是因为向量检索算法,本质上都是在用某种近似的手段,最小化搜索空间,避免暴力检索。因此,向量检索算法在运行过程中,总会“忽略”一部分数据。而不同的检索算法,选择性忽略的数据不同,就造成了他们在下游任务中的不同表现。
3.向量检索算法排名大洗牌
为了从端到端的视角,重新审视向量检索方案们的真实能力,我们构造了IceBerg Bench,覆盖不同模态、不同任务、不同embedding model。看看在这些元素的交叉组合下,向量检索算法的排名会有如何变化。
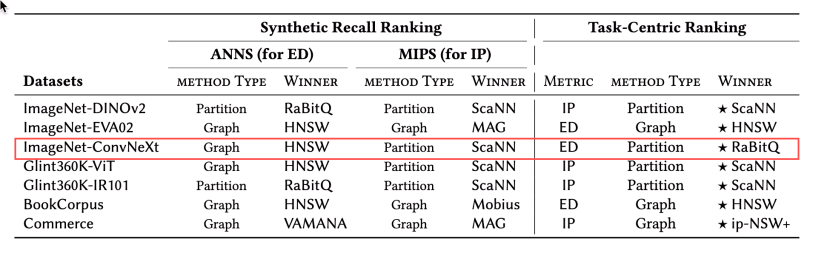
从上述结果,我们可以看到,HNSW并非下游任务中的“常胜将军”。不同的交叉组合下,有不同的方法脱颖而出。其中最有趣的一点是,在ImageNet图片识别的任务上,欧式距离和内积距离上最优的任务(HNSW/ScaNN),都没能成为下游任务的赢家(RaBitQ)。这说明,在语义到度量的理解上,机器学习领域还有很长的路要走。
4.新手玩家利器:自动化算法选型
向量检索效果如此难调,有没有什么办法可以让没有相关背景知识的小白避免暴力测试选对方法,无痛优化多模态RAG呢?有!IceBerg不仅是一个benchmark,还提供了自动化的算法检测方案。
我们发现,在不了解embedding产出的背景信息的前提下,从数据分布的统计信号上,我们依然可以找到甄选算法的入手点,并以此构建了一个可解释的“决策树”。
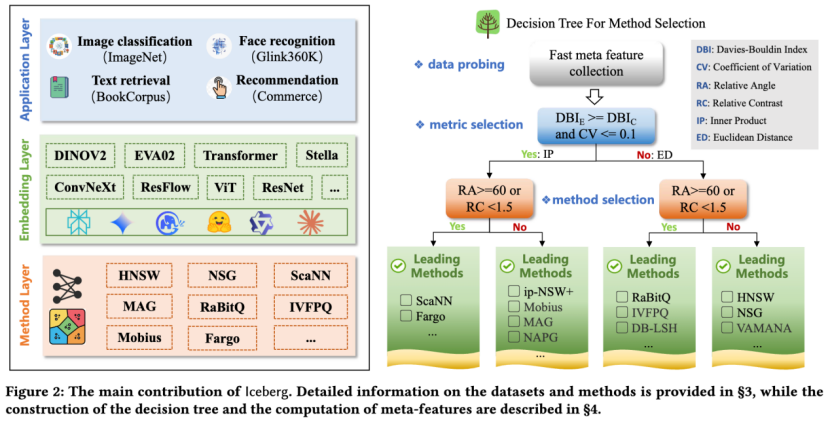
我们发现,embedding相对于度量、算法的“亲和力”可以从几个统计指标中看出来,而这些统计指标分别度量了数据的聚类程度、向量方向分散度等属性,可以通过我们随数据集提供的脚本快速计算,并自动化地根据我们测试的、在多种模态、多种encoder backbone、多种任务的角度下,一致有效的决策树,自动判断方法选择。机器学习模型还在不断进化,IceBerg也会保持最前沿encoder的追踪,实时更新算法选择工具。
5.总结
IceBerg首次从端到端的价值体系下重新度量了SOTA向量检索方法的真实能力。同时也暴露出来了向量数据库领域深埋于“海平面”之下的认知陷阱。我们呼吁未来的向量检索研究,更加深入到RAG、Agent等下游应用的语境下,关注度量-任务匹配度、算法-数据分布兼容性、乃至跨度量/多度量/多向量的统一向量检索算法,真实实现RAG的标准化。
论文详细链接如下:
论文arxiv:https://arxiv.org/abs/2512.12980
论文Hugging Face:https://huggingface.co/papers/2512.12980
代码Github:https://github.com/ZJU-DAILY/Iceberg


