编译 | 云昭
出品 | 51CTO技术栈(微信号:blog51cto)
近日,苹果被爆出了两个大事:一篇极具争议的论文,一场颇受质疑的新发布。最吊诡的是,iOS26新发布的热度还没有一篇论文引起的反响更强烈!
这篇研究论文名为《The Illusion of Thinking》,意在“讨伐”当前AI领域流行的一些“假象”,从题目就能看出火药味十足:大模型根本不会推理,那只是幻觉!
不过,很快就有一位大牛Gregorio站出来反驳——
虽然这篇论文戳中了不少痛点,但却因笨拙的表达方式而落人口舌。
Gregorio在自己的文章《Apple’s Viral AI Paper. Reality or Fraud?》,用客观且犀利的笔锋论证了这篇苹果刷屏的AI论文:是突破,还是欺诈?
为此,作者拆解以下几个关键问题:
- 苹果到底想说什么?他们并非全错,只是表达太生硬;
- 当前AI模型到底有哪些真正的局限?
- 对于一个急需“AI杀手锏”的三万亿美元公司来说,这一切意味着什么?
「前沿SOTA的AI模型到底有多聪明」、「苹果AI战略的真实图景到底是什么样子」,「推理只是记忆的伪装吗」,这些问题都被作者在文章中一一揭露。篇幅较长,大家自行摘取金句。
一、思考的幻觉
苹果在《The Illusion of Thinking》的论文中指出:即便是当下最先进的推理类大模型,如 OpenAI 的 o3、Google 的 Gemini 2.5 Pro,它们展现出来的“思考能力”其实是一种假象。
 图片
图片
这些模型的共性是:通过生成更多的 token 来提升表现,也就是我们熟知的「思维链」(Chain of Thought)技术——让AI一步步地“拆解”问题,模仿人类的推理过程。
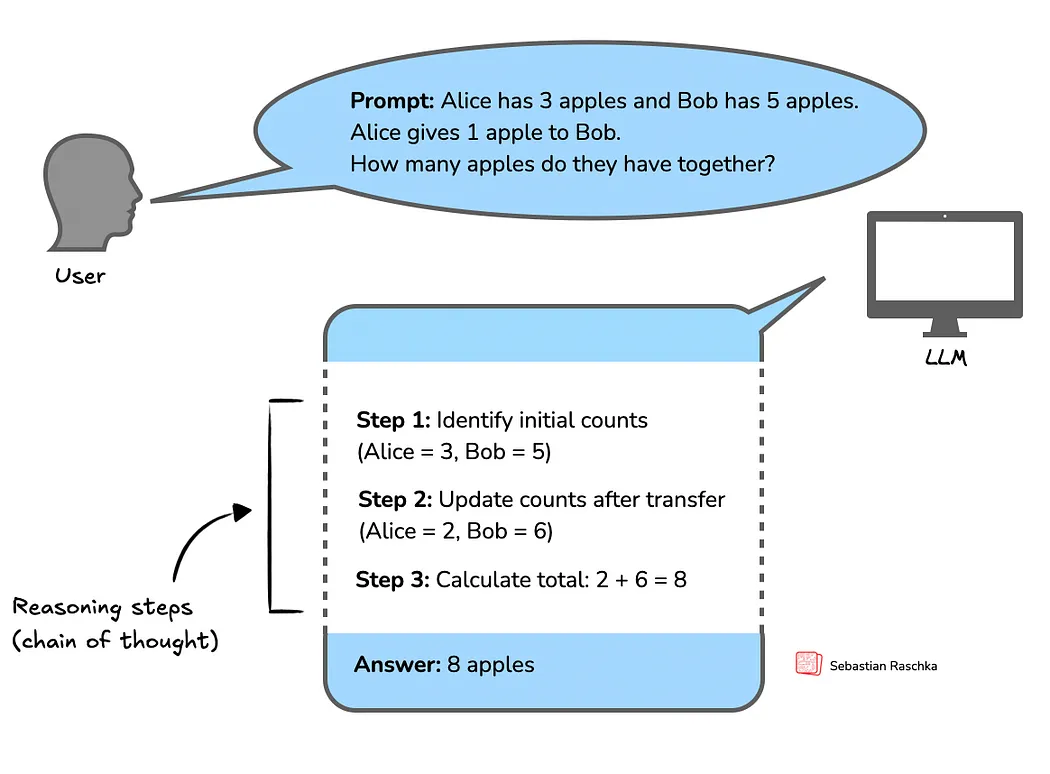 图片
图片
苹果的核心观点是:这些模型看起来是在“推理”,但它们并没有真的理解,更谈不上「通用推理能力」。
他们甚至声称,他们有证据表明,这一切几乎只是表演。
但他们究竟是如何证明的呢?
二、苹果的研究方法:从基准测试到“益智游戏”
苹果首先批评了现有的评估机制:目前评判AI能力的方法主要靠一堆标准化基准测试,涵盖数学、编程、常识等领域。
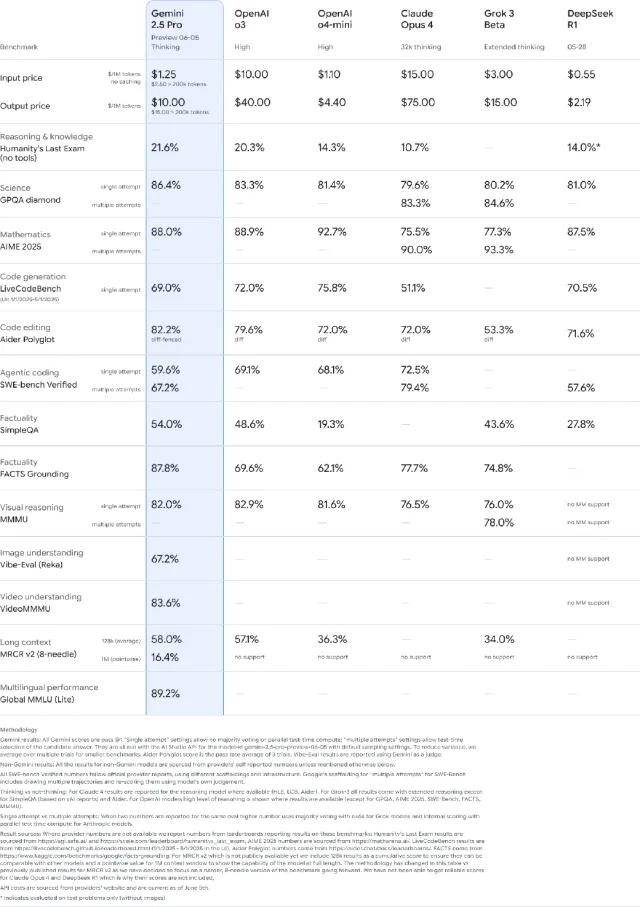 图片
图片
这些是 Google 用来比较其最新 Gemini 2.5 Pro 型号的一组基准
苹果公司一针见血地指出,问题在于大多数基准测试都受到了污染,这些模型之前已经见过大多数问题的答案。
诚然,这些测试的初衷是好的,能让我们横向比较不同模型。但问题是:大部分测试题,AI模型早就见过了,这根本无法区分实际表现和记忆力。就像学生提前看到了考卷,那考试成绩当然不能说明真实水平。
苹果提出的替代方案是:用益智类难题来测试模型真正的“推理”能力,因为这些题目极少出现在训练数据中,更能考验模型的泛化能力。
他们选用了四种经典的推理谜题:
- 汉诺塔(Tower of Hanoi):一个递归性极强的难题,考验规划和记忆。
- 跳棋换位(Checker Jumping):一个一维空间内颜色交换的逻辑题。
- 过河难题(River Crossing):约束条件丰富的角色过河规划问题。
- 积木世界(Blocks World):早期AI界著名的“世界建模”问题。
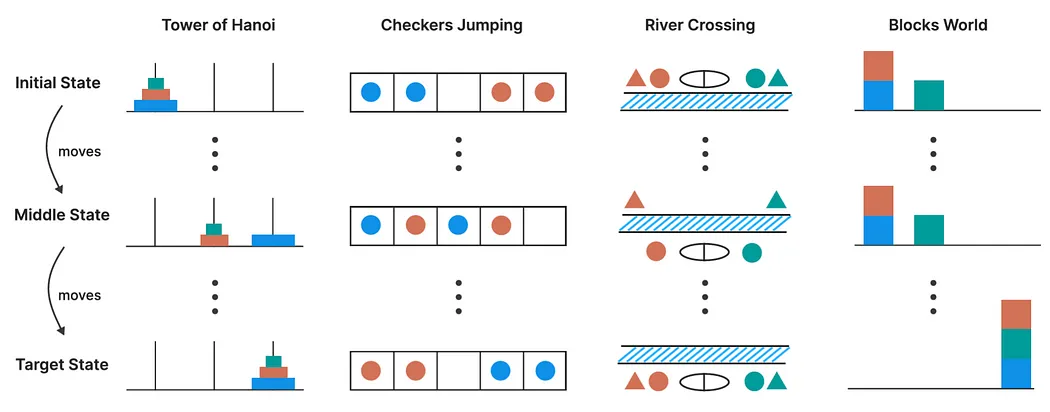 图片
图片
每一个谜题都有确定的目标状态和解法步骤,能清楚地区分“解对了”还是“没解出来”。
(这里,来一波回忆杀~)例如,以汉诺塔谜题为例,该谜题经过了最广泛的评估,其目标是在以下约束条件下将位于第一根柱子的所有圆盘移动到最后一根柱子:一次只能移动一个磁盘较大的磁盘永远不能位于较小磁盘的顶部(直径)目标是在尽可能少的移动下完成,由公式 (2^n - 1) 定义,其中“n”是磁盘的数量。
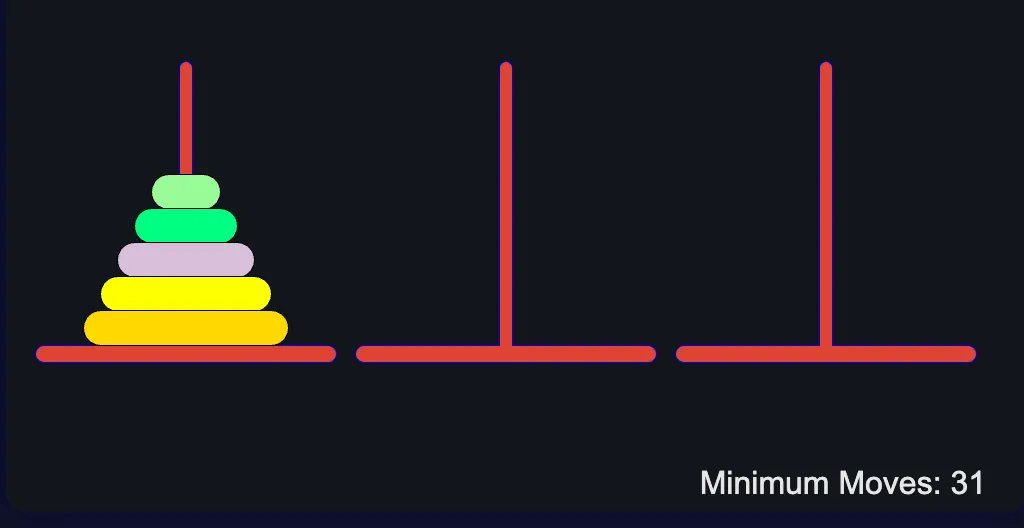 图片
图片
n = 5 的汉诺塔(很经典的算法面试题)
其他谜题与之类似,因为它们定义了模型必须遵守的一小部分约束,并且解决方案有一个特定的、确定性的答案,这使得评估具有客观性;模型要么解决它,要么没有。
至关重要的是,它们是可解释的,这样人们可以查看模型的推理痕迹,了解它们如何“思考”(暂且这么说吧,的确也没有更好的词儿)。
三、结果如何?所有SOTA模型“智商瞬间崩盘”
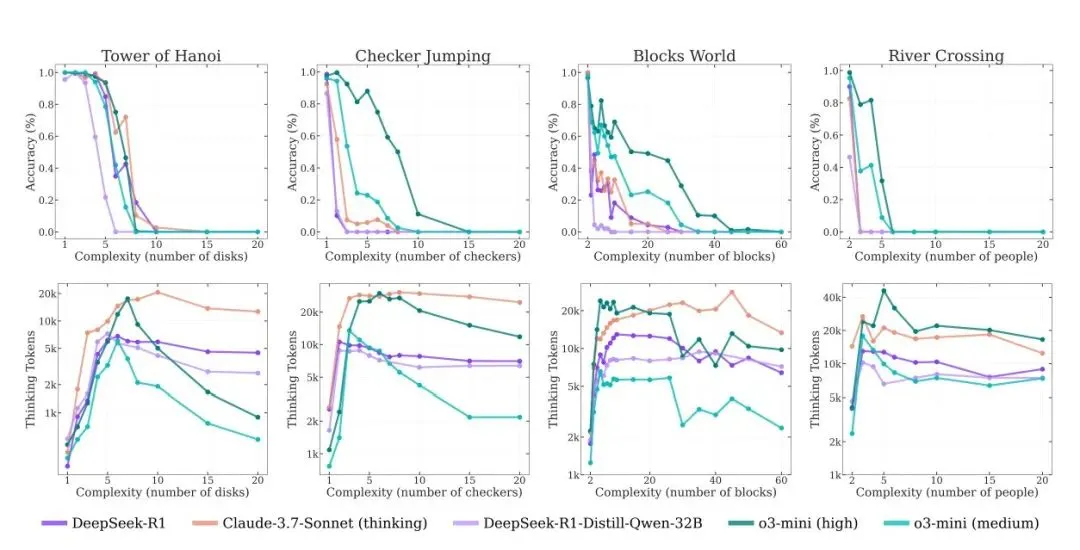
苹果研究者最后发现:天塌了!DeepSeek R1、Claude-3.7-Sonnet、o3-mini等这些前沿的模型虽然有复杂的反思机制,但却无法发展出可泛化的解决问题的能力,甚至会在每个谜题的某个阶段,性能会急剧下降为零。
 图片
图片
总结起来有如下几个结论——
1. 推理模型无法突破复杂度阈值
即便有“自我反思”的能力,这些模型一旦遇到更复杂的问题(比如汉诺塔的盘子变多),准确率几乎瞬间归零。它们无法“迁移”解决复杂任务,只能停留在简单套路中。
2. 三种推理“状态”
苹果指出,模型的表现大致分为三个阶段:
- 简单任务:普通大模型反而表现更好,因为推理模型“想太多”反而拉胯(典型“越想越错”)。
- 中等复杂度任务:推理模型展现优势,思维链帮助其逼近答案。
- 高复杂度任务:无论是普通模型还是推理模型,统统崩盘,准确率接近零。
3. 思考力的“反直觉衰减”
最惊人的是:随着问题变复杂,模型的思考输出(即生成的 token 数)居然减少了。模型就像“知道自己搞不定”,索性提前放弃。
研究者称这是一种“推理计算资源的极限”:模型自我判断“撑不到解完”,干脆停下来。
这就类似于我们人类在面对本能任务时,如果试图靠“刻意思考”来完成,而不是凭本能反应,反而会表现得更差。
一个很直观的例子是打字。如果你已经习惯了盲打,你可以毫不犹豫地按下任何一个键。但如果你刻意去想“字母 ‘u’ 在哪儿”,你反而会慢下来,甚至可能一时想不起来,尽管你的肌肉记忆非常清楚地知道 ‘u’ 的位置。
再举一个更简单的例子:你如果去“思考” 1 + 1 等于几,而不是本能地回答“2”,那其实是在用更低效的方式处理一个几乎可以秒答的问题——因为你把原本可以瞬间解决的事,花了更多的认知资源。
四、推理模型“装聪明”?计算≠思考
哪怕提示中直接给出了解题算法,比如“汉诺塔怎么搬盘子”,这些模型依旧做不到长期正确执行。
更严重的是,它们在不同题型上的表现非常不一致。比如 Claude 3.7 在汉诺塔上表现不错,但在理论上更简单的“过河”问题中却表现糟糕。
苹果认为这说明了一个残酷现实:
当前模型的“聪明”多数是靠“背题库”来的,泛化能力极差。我们以为是一个12岁天才少年,其实他只是个“背书机器”。
乍一看,有强有力的证据表明:推理模型实际上并不推理,并且其大部分可信性能可以用“基准记忆”来解释。然而,如果你仔细观察,事情就会变得模糊不清。
五、苹果的研究方法很值得质疑
说实话,我赞成苹果揭露“伪智能”的动机,但我对他们的研究方法保留意见。
比如,关于“过度思考”这件事。苹果认为模型“想太多”反而错失正确答案,是在证明它们的推理很浅。但这个问题,可能是可以靠更大模型、更好训练继续优化的,并不能直接证明“AI不会思考”。
他们没有测试最强的模型,比如 o3 或 o4-mini,这些可能根本不会出现类似“过度思考”的问题。你会怀疑他们是不是“刻意绕过”了这些模型?
其次,关于“自动认输”的问题。模型面对复杂任务(如 15 层汉诺塔)不但做不出来,甚至都“不太想试”。苹果觉得这是“思维能力不足”的铁证。但他们忽略了几个重要事实:
- 大模型训练时,就被鼓励别乱试错,这能减少计算浪费,优化用户体验。
- 这些模型有 token 上限,它们“知道自己撑不到结尾”,所以选择中途放弃。
比如,o3-mini 的 token 上限是 10 万左右,扣除提示词后大概能推 10,000 步。
根据汉诺塔解法公式 2n−12^n - 1,它最多也就能算出13层以内的解,超过就力不从心了。
苹果却没有考虑这个计算极限,还以此推断“AI根本不会按步骤执行”。
其实模型可能是在说:
“我知道该怎么做,但我没足够 token 做完,只能告诉你我会怎么做。”
六、苹果没错,但还不够深刻
苹果这篇论文,有刺刀的凌厉之处,但也有盲区。它敲响了AI神话的警钟,却也可能低估了模型正在发生的真实进化。
说它“搬起石头打自己的脚”太重,说它“突破”也言过其实。更像是苹果用技术语言讲了个直白的警示故事:
“今天的AI,看起来会思考,实际上大部分时候只是记得答案。”
1.并不是所有谜题都“等价”
苹果研究者在解读结果时,还有一个颇具争议的地方——他们以为所有谜题的“步骤数”可以直接比较,并据此判断模型是不是在靠记忆作答。
比如,他们发现 Claude 3.7 Sonnet 在汉诺塔问题上可以完成将近 100 步的解题(10层),而在“过河难题”中,第4步就崩了,于是就得出结论:AI 模型没有推理力,只是在背题库。
论文中是这样写的:
“Claude 3.7 Sonnet 在汉诺塔任务中,常常要到第100步才出错(N=10),而在过河问题中,通常在第4步就无法生成合理动作。更令人惊讶的是,它几乎可以完美解决需要31步的 N=5 汉诺塔,但在只需11步的 N=3 过河问题中却完全失败。这可能意味着,训练数据中几乎没有 N>2 的过河问题样本,导致模型缺乏记忆,因此也就不会解。”
翻译成通俗白话,就是:
“Claude 模型能搞定上百步的汉诺塔,却搞不定十几步的过河问题,所以我们认为,它只是在靠记忆刷题,对‘推理能力’根本没掌握。”
这公平吗?我觉得完全不公平。
2.逻辑直觉没错,却论证逻辑太薄弱
这正好说明了我之前的观点:这篇论文的直觉很敏锐,但论证能力很差。
对比谜题步骤数是一种极其粗糙的分析方式。
“过河问题”本质上就比“汉诺塔”复杂。虽然表面上只有11步,但涉及到约束条件(比如“狼不能和羊单独待一起”)更多,状态空间也更不可预判。
反观汉诺塔,其实是一个可规划性极强的问题,步骤虽多,但解法是高度规则化的。
所以你不能因为一个题“短”,就说它“简单”;也不能说模型做得好,就是“记住了”。
我本人也同意他们对AI推理的怀疑论倾向。我早就多次说过:很多“推理”其实就是“记忆伪装出来的”。
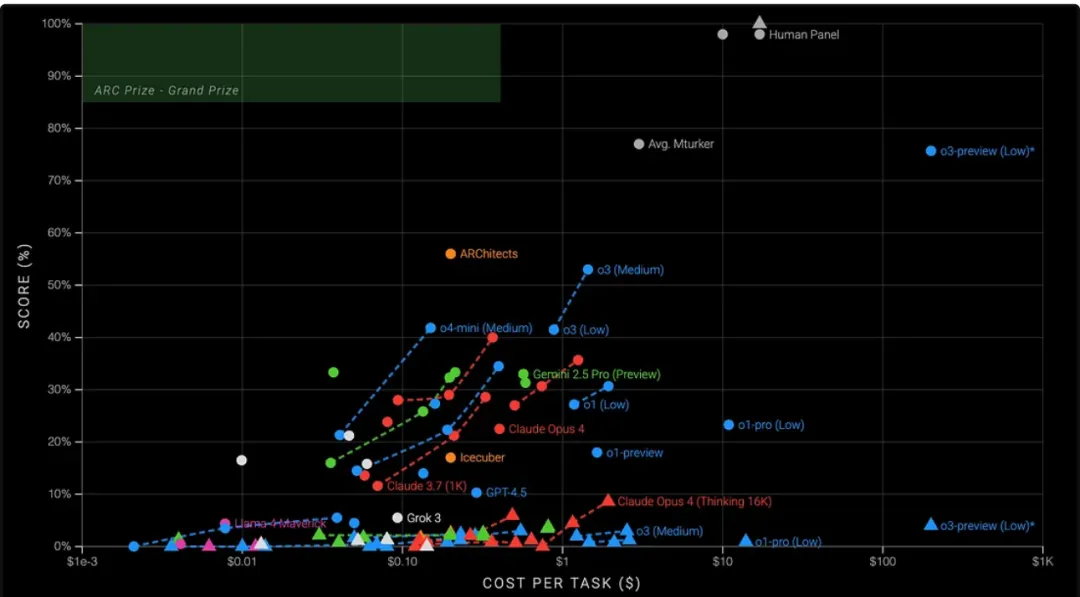
但苹果在方法论上选错了靶子。真正体现 AI 推理能力的基准,是像 ARC AGI 这样的测试集——它专门设计来规避“训练数据污染”,确保模型真的没有见过类似题。
结果呢?模型一旦离开记忆舒适区,成绩立刻“扑街”:
下图展示了 ARC AGI v2 最新测试结果,图中用三角形标示不同模型,表现最好的 Opus 4 得分也只有 8.9%。
 图片
图片
ARC AGI v2 测试结果:模型一旦无法“背题”,推理就崩溃
这才是真正说明问题的数据。它表明:大部分模型严重依赖记忆,而不是逻辑。这比苹果在论文里“比谁走得多”靠谱多了。
3.AI的真正极限:不是“不会推理”,而是“无法泛化”
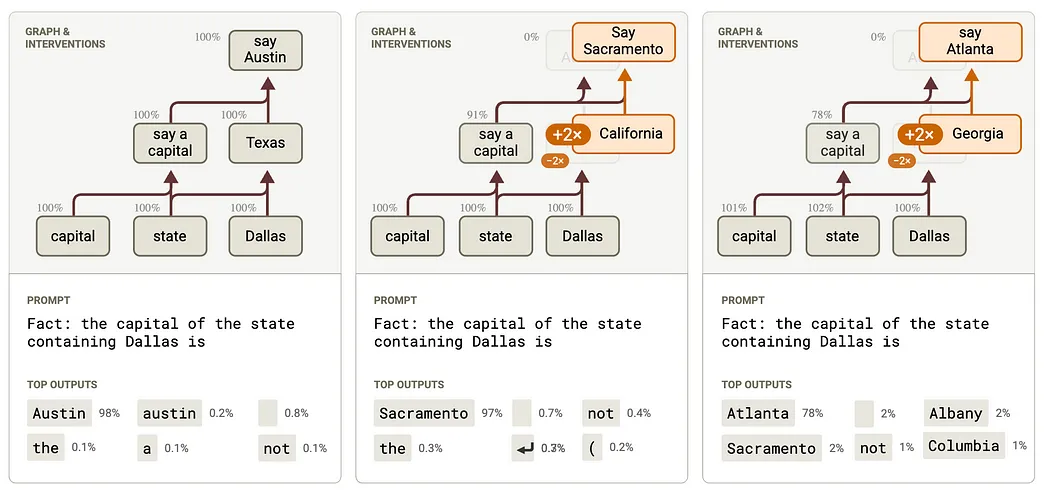
所以苹果说得对吗?不全对,但触到了关键问题。这里要澄清一件事:当我说 AI 过度依赖记忆,不代表我认为它们只会记忆。这显然是错的。
如果你以为大模型只是个大数据库,那你就错了。Anthropic 的“归因电路”研究就证明,大模型内部确实构建了可泛化的逻辑电路,用来处理“美国首都在哪”这类任务。
 图片
图片
如果全靠死记硬背,那就得为每一个问题建一个电路,这在架构上是不可行的。
所以,问题不在于“AI 不会推理”,而是:
AI只能在“已知领域”推理,而人类可以在“未知领域”做出合理推断。
这是人机差异的本质。
七、如果苹果真想挑事,就应该盯住这三个“硬伤”
苹果这篇论文,如果真的想撼动主流AI叙事,应该聚焦于那些大家都公认的AI硬伤:
1. 学习样本效率极低
人类看几遍就能学会的知识,AI 需要几百万条数据。这是目前AI完全无法比拟人类的地方,也是衡量“智能”的重要指标。
2. 无法持续学习
人类不断更新世界观,但大模型“上线之后就停止学习”,要重新训练一遍,代价巨大。更重要的是,我们还没搞懂如何让AI进行真正的贝叶斯式持续学习。
3. 适应力几乎为零
人类面对陌生环境可以快速“现学现卖”,AI不行。模型只能“对已知做出最优反应”,而不能像人类一样对未知建模。
这三点,才是AI与人类之间最本质的智能鸿沟。也是为什么说“AI像博士一样聪明”根本不成立。模型可以拥有比人类更全面的知识,但那不等于更聪明。
如果连井字棋都下不好,你知识再多也没用。
八、苹果真正的问题:不是论文写得刺耳,而是产品太难看
最后说说苹果自己。
他们其实不是第一次批评AI了,甚至已经让人觉得他们对现代AI始终抱有戒心。这不是坏事,毕竟 Meta 的 Yann LeCun 批评得更狠,但 Meta 依然在全力投入AI模型研发。
苹果的问题是,他们自己交出的答卷——尤其是产品层面——实在太差了。
昨天 WWDC 刚刚发布的 Apple Intelligence,远不及预期。一堆“炫技功能”背后,实用性、开放度、迭代力统统缺失。Siri 仍然是地表最烂的语音助手,而我居然还因为这个更新换了 iPhone。真的……很气。
对一个市值三万亿的科技巨头来说,这是难以原谅的颓废。
苹果研究论文说:“AIs 还解不了 14 层的汉诺塔。”
但问题是:你们自己连“4 层的 Siri”都做不好,这谁能信服呢?
好了文章到这里结束了,欢迎大家评论区拍砖:大家如何看苹果的这篇的论文,大模型真的会思考吗?
参考链接:
https://medium.com/@ignacio.de.gregorio.noblejas/apples-viral-ai-paper-reality-or-fraud-9627a6de385a
https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf


