近日,国内 AI 初创公司 MiniMax 发布了一款全新的语言大模型 MiniMax-M1。
有两个方面最引人注目:
1.高达100万Token的上下文处理能力。
2.极具竞争力的训练成本效益。
M1 那个“1,000,000 token 上下文窗口”的数字,它几乎是 GPT-4o 的 8 倍,是大多数企业内用 LLM 一次上下文能处理信息量的极限突破。
大上下文也很烧钱,处理这么长的输入输出意味着更大的内存占用和更高的计算量。而 MiniMax-M1 把这件事“做得便宜”。据官方披露,M1 的训练总成本仅为 53.47 万美元,约为 DeepSeek R1 的十分之一,而之前的GPT-4 更是要上亿美金起步。
据说,这要归功于两个设计巧思:其一是 CISPO,这种自研的强化学习算法用更聪明的采样方式节省了大量重复训练成本;其二是混合专家架构(MoE)+ 快速注意力机制,它只激活最需要的那部分参数。
高性能,也可以很便宜
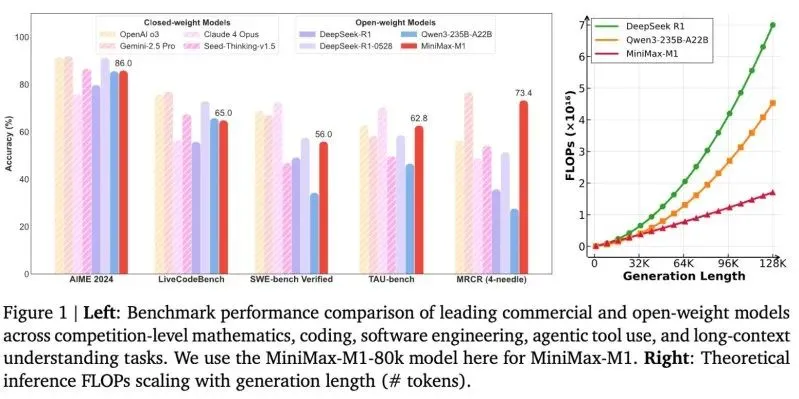
低成本并没有牺牲性能。在多个重要基准测试中,MiniMax-M1 的表现比 DeepSeek-R1 和 Qwen3 等知名开源模型更为突出。
 图片
图片
在数学推理难题 AIME 2024 中,它的准确率达到 86.0%。在代码生成任务 SWE-bench Verified 中取得 56.0%,在函数调用测试 TAU-bench 中得分 62.8%。这些数据意味着它不仅“看得懂”长文本,还能“用得上”。
尽管与 GPT-4o、Gemini Pro 2.5 等封闭式顶级模型相比,它仍存在通用理解能力上的差距,特别是在高维复杂指令、语言微妙语境等任务中,但在开源模型阵营中,它已进入第一梯队。
 图片
图片
其次,MiniMax-M1 保持了完整开放:Apache-2.0 协议,支持商用、修改、永久免费使用。这让它在技术价值之外,也具备战略价值——它是任何一家企业都可以“据为己有”的大模型。
据说,M1是全球首个开源大规模混合架构的推理模型。
而在产品策略上,MiniMax 并没有追求全面均衡,而是选择了“关键能力超配”的方向:超长上下文、极低计算成本、易部署的架构和极宽松的许可。
它有两个版本:40k 和 80k tokens 输出上限,分别对应不同推理预算。这种设置非常工程化——越多预算带来更完整的推理,但也更慢更贵。MiniMax 把决策权交还给开发者和企业用户,让他们自己调节“速度-成本-性能”三者之间的平衡。
它还原生支持 structured function calling,适配 vLLM 和 Transformers 等主流框架,可快速集成进已有基础设施,构建具备“智能体”能力的产品。它甚至预装了搜索、视频生成、语音合成等多模态能力插件,为应用构建节省了大量研发资源。
这并不是“另一个大模型”,而是一个面向未来任务形态的基础设施尝试。


