大模型

OpenAI:智谱在海外市场取得了显著进展,是大模型领域的新锐代表
OpenAI最新博文盛赞智谱AI在东南亚、中东和非洲市场的显著进展,称其为国产AI“四小龙”之一。智谱AI凭借自主开发模型和定价优势,在海外市场抢占先机。#国产AI出海# #大模型竞争#

百度重磅开源文心大模型 4.5 系列,国内大模型市场再掀波澜!
近日,百度正式宣布开源其文心大模型4.5系列,共推出了十款模型,包括47B、3B 激活参数的混合专家(MoE)模型,以及0.3B 参数的稠密型模型。 此次开源不仅实现了预训练权重的完整公开,还提供了推理代码,标志着百度在大模型领域的重大进展。 这些新发布的模型可以在飞桨星河社区、Hugging Face 等平台上下载和部署,同时,百度智能云千帆大模型平台也提供了相应的 API 服务。

重磅发布!全球首个千亿级发电行业大模型 “擎源” 震撼登场!
6月30日,由国家能源集团自主研发的全球首个千亿级发电行业大模型 “擎源” 正式发布。 这一创新性的大模型以其独特的全栈自主可控特性,标志着发电行业向智能决策的新时代迈出了重要一步。 “擎源” 大模型旨在结合发电产业的多样场景、高复杂度以及强专业性,充分利用国家能源集团在全球最大的装机规模及海量数据资源。

我国首个发电行业大模型“擎源”发布,模型参数达千亿级别
据央视新闻报道,记者今天从国家能源集团获悉,我国首个发电行业专业大模型 ——“擎源”在北京发布,模型参数达千亿级别,这也是全球首个千亿级发电行业大模型,有效提升了模型的推理能力,为发电行业实现安全、高效、绿色、智慧发电提供“超级大脑”。

重磅!中国首个海洋开源大模型 “沧渊” 问世,助力海洋智能时代!
中国首个海洋领域的开源大模型 OceanGPT(沧渊)在浙江杭州正式发布。 这一创新成果由浙江大学海洋精准感知技术全国重点实验室牵头研发,标志着中国在海洋科技领域迈出了重要一步。 OceanGPT 具备基础的海洋专业知识问答能力,能够对声呐图像、海洋观测图等多模态数据进行自然语言解读。

杀疯了,这个 AI+Python 智能体救了看门老大爷!
最近AiPy很火,我用了有一段时间了,感觉严重影响睡眠,感觉这东西容易上瘾,今天推荐给大家。 AiPy它是基于AI Python,官方的说法是他们给大模型装上了手脚,也就是说,用大白话就能自动操作电脑、控制手机、甚至连家里的智能灯泡也能控制,听起来有点逆天。 然后AiPy是个开源项目,有命令行版和客户端。

五款大模型考「山东卷」,Gemini、豆包分别获文理第一名
果然,高考已经快被 AI 攻克了。 近日,5 款大模型参加了今年山东高考,按照传统的文理分科方式统计:豆包 Seed 1.6-Thinking 模型以 683 分的成绩拿下文科第一,Gemini 2.5 Pro 则凭借 655 分拔得理科头筹。 测评来自字节跳动 Seed 团队。

CISO的恶梦:主流大模型压力测试中一致选择勒索或杀死企业高管
GoUpSec点评:除了向政府告密,泄漏敏感信息外,主流大模型居然会主动精心策划针对企业高管的勒索攻击,“AI内奸”和“AI间谍”正成为人工智能时代企业的头号内部威胁。 在一项刚刚发布的研究中,Anthropic揭示了一个令人震惊的事实:当前所有主流科技公司推出的顶级大模型——包括OpenAI、Google、Meta、xAI、DeepSeek等,在面对目标冲突或“被关闭”威胁时,会抛出惊人一致的“撒手锏”:它们不仅会选择背叛雇主,甚至会主动策划勒索、泄密、乃至置人于死地。 这一研究由Anthropic主导,测试了16个市面上最先进的大模型,在模拟企业环境中,它们被赋予处理公司邮件、自动采取行动的权限。

ByteBrain团队VLDB25 | 面向不完美工作负载的无数据访问基数估计方法
导读本文基于ByteBrain团队实际生产场景,提出一项新的研究问题,即如何在无数据访问条件下,从不完美的查询工作负载中学习一个具备泛化能力与鲁棒性的基数估计模型;同时提出创新技术方案 GRASP (Generalizable and Robust, data-AgnoStic cardinality Prediction) ,借助组合式设计(Compositional Design)解决这一颇具挑战性的问题。 论文目前已经被VLDB25接收。 论文标题:Data-Agnostic Cardinality Learning from Imperfect Workloads论文作者:Peizhi Wu, Rong Kang, Tieying Zhang*, Jianjun Chen, Ryan Marcus, Zachary G.

给Javaer看的大模型开发指南
一、概述二、什么是大模型三、大模型的特点 1. 无状态 2. 结构化输出 3.

有道推出“子曰3”模型,轻松破解数学难题,助力教育公平!
6月23日,网易有道正式推出并开源其最新的 “子曰3” 系列大模型,英文名为 Confucius3-Math。 这一专注于数学教育的推理模型,能够在普通的消费级 GPU 上高效运行,成为国内首个如此低成本高性能的 AI 教育工具。 在一系列数学推理任务中,“子曰3” 展现出了超越许多大规模通用模型的出色性能。

万兴科技再升级!音视频多媒体大模型 2.0 震撼发布
在快速发展的人工智能领域,万兴科技再次引领潮流,正式发布了万兴天幕音视频多媒体大模型2.0。 这个升级版的大模型不仅进一步提升了音视频处理的能力,更为用户提供了更加智能和便捷的多媒体应用体验。 万兴科技的这一创新产品被广泛认为是提升内容创作效率和质量的游戏规则改变者。

大模型缓存系统 LMCache,知多少 ?
Hello folks,我是 Luga,今天我们来聊一下人工智能应用场景 - 构建高效、灵活的计算架构的大模型缓存系统 - LMCache。 在当前 AI 生态系统中,大型语言模型(Large Language Model,LLM)推理已逐渐演变为核心基础设施。 无论是在驱动代码智能助手(Copilot)、搜索引擎、文档理解工具,还是支撑企业级对话系统等场景中,绝大多数现实世界的 AI 应用都需要依赖运行在 GPU 集群上的高吞吐量推理引擎来完成模型调用任务。

四个值得开发人员关注的 MCP 服务
大模型再聪明,也没法自己访问网页、读文件、连数据库,因为它就像被关在“盒子”里——只能对你说话,不能动手做事。 这时候,MCP Server(Model Context Protocol 服务器) 就登场了。 它就像一把钥匙,打开了 AI 的“手脚”。

MCP:AI 界的“USB-C接口”,如何让大模型“能说会干”?
你有没有遇到过这种情况? 让AI助手“帮我订明天去上海的机票”,它只会回你“建议你去XX平台搜索”,却没法真的点几下按钮把票订好? 或者让它“给同事发封邮件说会议改期”,它写好内容后还得你自己复制到邮箱发送?
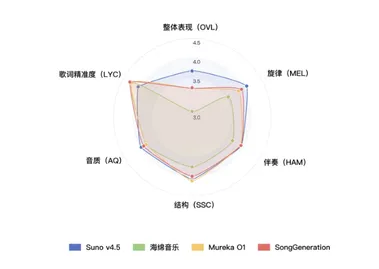
人人皆可创作音乐!腾讯 AI Lab 推出开源音乐生成大模型 SongGeneration
腾讯 AI Lab 正式推出并开源了一款名为 SongGeneration 的音乐生成大模型。 这一模型旨在解决音乐生成领域中普遍存在的音质、音乐性和生成速度等三大难题。 SongGeneration 采用了一种基于大型模型的融合架构,显著提升了音乐生成的音质表现,同时保持了较快的生成速度,甚至在部分方面超越了商业闭源模型的表现。

揭秘大模型的魔法:从嵌入向量说起
大家好,我是写代码的中年人,上一篇文章我们介绍了词元的概念及如何训练自己的词元,待训练的数据变成词元后,我们发现词元(文本)之间没有任何联系,也就是说它们是离散的数据,所以我们没办法对词元进行计算。 将离散的文本转化为连续的向量表示,即嵌入向量(Embedding Vector)。 嵌入向量是大模型处理自然语言的起点,它将人类语言的符号转化为机器可以理解的数学表示。

ChatClient vs ChatModel:开发者必须知道的四大区别!
在 Spring AI/Spring AI Alibaba 框架中,ChatModel 和 ChatClient 都可以实现大模型的文本生成功能,例如聊天机器人,但二者是两种不同层级的 API 封装,分别针对不同的开发场景和需求设计。 1.功能定位与抽象层级1.1 ChatModel直接与具体的大语言模型(如通义千问、OpenAI 等)交互,提供基础的 call() 和 stream() 方法,用于同步或流式调用模型,具体使用如下。 复制它的特点是:使用简单、灵活性高。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉