资讯列表

AAAI 2026|视频大语言模型到底可不可信?23款主流模型全面测评来了
近年来,视频大语言模型在理解动态视觉信息方面展现出强大能力,成为处理真实世界多模态数据的重要基础模型。 然而,它们在真实性、安全性、公平性、鲁棒性和隐私保护等方面仍面临严峻挑战。 为此,合肥工业大学研究团队携手清华大学研究团队推出了首个面向视频大语言模型的综合可信度评测基准 Trust-videoLLMs。

蚂蚁数科宣布开源数据分析智能体技术,当前登顶BIRD
12月13日,第二届CCF中国数据大会上,蚂蚁数科宣布开源旗下数据智能体关键技术Agentar SQL全套论文、代码、模型和使用指南。 该智能体技术可让非专业人员通过日常语言进行商业数据查询和分析,为企业数智化提供更精准可用的智能数据分析基座。 蚂蚁数科首期开源实时文本转化结构化查询语言(Text-to-SQL)框架,为开发者提供一套开箱即用的数据查询方案,提升文本与数据库查询交互效率。

阿里推出新语音模型“百聆”:三秒录音实现多语言与情感切换
阿里巴巴通义大模型宣布,其 “百聆” 系列语音模型迎来了重大升级,并正式开源。 此次更新的两款语音模型,能够在仅需三秒的录音后,实现无缝切换至多达九种语言和十八种方言,包括普通话、粤语、日语、英语等,同时还可以模拟多种情感如开心和愤怒。 在这次升级中,Fun-CosyVoice3模型得到了显著改善。
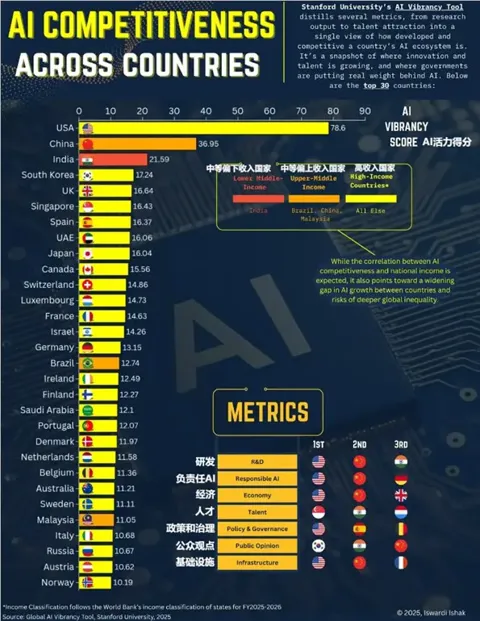
全球人工智能竞争力排名出炉:美国夺冠,中国紧随其后!
近日,斯坦福大学发布了全球人工智能活力工具(Global AI Vibrancy Tool)的最新数据,揭示了全球人工智能竞争力排名前30位的国家。 根据这份评估,综合考虑了各国在研究成果、投资、人才吸引和治理框架等多个维度的表现,美国凭借强大的私人投资、学术研究和活跃的初创企业位居第一。 中国紧随其后,表现同样不俗。

一行AI指令摧毁整台Mac!Claude CLI工具误删用户主目录,开发者多年心血瞬间清零
一场由AI助手引发的数字灾难,再次敲响了自动化工具安全性的警钟。 12月8日,开发者LovesWorkin在Reddit上发帖痛诉:自己仅是想用Anthropic推出的Claude CLI编程工具清理旧代码仓库,却因AI生成的一行命令,导致整台Mac电脑主目录被彻底清空——桌面、文档、下载文件夹、钥匙串、应用数据乃至Claude自身凭证全部消失,多年积累的工作成果几近归零。 问题出在Claude CLI执行的这条命令上: `rm -rf tests/ patches/ plan/ ~/`表面看,这是在删除几个项目目录,但致命错误藏在末尾的 `~/` ——在Unix/Linux系统中,`~` 代表当前用户的主目录(如 `/Users/username`)。

商汤发布行业首个“多剧集生成智能体”Seko2.0,国产AI芯片首次打通多模态AIGC全链路
商汤科技正式推出Seko2.0——全球首个专注于多剧集视频生成的智能体,标志着AI视频生成从单片段创作迈向连续叙事的新阶段。 该系统能够生成角色、场景、风格高度一致的多集短视频内容,在剧情连贯性、人物稳定性与视觉统一性上实现行业突破,为短剧、广告、教育等场景提供可规模化的AI内容生产方案。 0 的背后,是商汤自研“日日新Seko”系列多模态大模型的深度协同。

国际体育赛事首次,奇瑞“墨茵”机器人于 2025 亚青残运会完成颁奖首秀
AI在线 12 月 15 日消息,据奇瑞集团官方,迪拜当地时间 12 月 12 日,在 2025 亚洲青年残运会(AYPG)举重项目颁奖仪式上,奇瑞机器人墨茵(Mornine)与机器狗(Argos),与亚洲残奥委员会首席执行官 Tarek Souei,共同为冠军运动员颁授金牌。 这标志着机器人首次在国际综合性体育赛事中承担颁奖任务。 据悉,本届赛事期间,墨茵(Mornine)还将继续协助完成后续比赛的颁奖工作。

连续俩月霸榜全球第一的数据分析智能体,终于开源啦!
12月13日,第二届CCF中国数据大会上,蚂蚁数科宣布开源旗下数据智能体关键技术Agentar SQL全套论文、代码、模型和使用指南。 该智能体技术可让非专业人员通过日常语言进行商业数据查询和分析,为企业数智化提供更精准可用的智能数据分析基座。 蚂蚁数科首期开源实时文本转化结构化查询语言(Text-to-SQL)框架,为开发者提供一套开箱即用的数据查询方案,提升文本与数据库查询交互效率。

Tenstorrent 裁员 7.5%!重心转向个人开发者,AI 芯片发展计划调整
知名 AI 芯片企业 Tenstorrent 宣布进行了一轮裁员,裁员规模达到7.5%,员工总数降至约1000人。 这一举措由首席执行官 Jim Keller 主导,他在接受 EETimes 采访时表示,此次裁员是针对整个公司层面的调整,并不是集中在某个特定部门。 Keller 指出,裁员的主要原因在于员工的技能、心态和团队匹配度,而并非出于财务方面的压力。

谷歌打通AI与个人知识库:NotebookLM深度集成Gemini,让AI真正“记住”你的工作上下文
谷歌正将AI助手从通用问答工具,转变为真正理解你个人工作脉络的智能协作者。 近日,该公司正式推出NotebookLM与Gemini的深度集成功能,允许用户在与Gemini对话时,直接调用自己在NotebookLM中创建的笔记、文档和知识库作为交互上下文。 这意味着,Gemini不再仅依赖其训练数据或当前对话内容进行回应,而是能“读取”你精心整理的项目资料、会议纪要、研究摘要或学习笔记,从而提供高度个性化、上下文精准的答案。

蚂蚁集团健康应用 AQ 更名为 “阿福”,月活用户突破 1500 万
蚂蚁集团旗下的 AI 健康应用 AQ 近日宣布更名为 “蚂蚁阿福”,同时推出了全新版本的 App。 此次升级主要围绕健康陪伴、健康问答和健康服务三个核心功能进行优化。 根据官方数据,目前 “蚂蚁阿福” 的月活跃用户已超过 1500 万,成为国内首屈一指的健康管理 AI 应用。

国产芯片也能跑AI视频实时生成了,商汤Seko 2.0揭秘幕后黑科技
自 Sora 2 发布以来,各大科技厂商迎来新一轮视频生成模型「军备竞赛」,纷纷赶在年底前推出更强的迭代版本。 谷歌推出 Veo 3.1,通过首尾帧控制和多图参考解决了以往视频生成「抽卡」随机性太强的问题;Runway 拿出 Gen-4.5,强化了物理模拟和表情动作迁移;快手祭出 Kling 2.6,实现了原生音画同步……各家都在炫技,但一个更本质的问题却常被忽略:这些模型距离真正的生产力工具,究竟还有多远? 12 月 15 日,商汤科技产品发布周正式开启,第一天就重磅上线了全新的 Seko 2.0 版本,让 AI 短剧创作真正实现「一人剧组」。

小米首席语音科学家 Daniel Povey:AI 发展的本质就像生物进化,不开源要慢 1000 倍
从生物进化的漫长历程到 AI 技术的疯狂迭代,两者遵循着惊人相似的底层逻辑。 在探寻下一代 AI 架构的关键时刻,著名的“Kaldi 之父”、小米集团首席语音科学家、IEEE Fellow Daniel Povey 提出:就像生物进化一样,AI“配方”的设计本质上就是一个不断试错的过程,而进化的速度,取决于“复制”一个新想法所需的时间。 在本次量子位 MEET2026 智能未来大会上,他也将开源视为 AI 进化的核心加速器 ——若没有开源,行业的进化速度恐怕要慢上一千倍;正是因为有了开源,技术才能像生物适应新环境一样,经历“长期停滞 瞬间爆发”的非线性跃迁。

Veo何止生成视频:DeepMind正在用它模拟整个机器人世界
随着通用型(Generalist)机器人策略的发展,机器人能够通过自然语言指令在多种环境中完成各类任务,但这也带来了显著的挑战。 一方面,真实世界评估成本极高,需要系统性地覆盖常规场景、极端情况、分布外(OOD)环境以及各类安全风险,通常需要进行成百上千次真实硬件实验,不仅耗时、昂贵,还可能存在操作风险。 另一方面,安全性评估尤为棘手,许多潜在的不安全行为(例如误夹人手、损坏设备或引发环境危险)本身就不适合在真实环境中反复测试,使得传统的硬件评估方法在安全场景下往往难以实施。

阿里通义百聆推出语音模型新版本:3 秒录音即可“复制”9 种语言、18 种方言
AI在线 12 月 15 日消息,今天下午,通义大模型通过官方公众号宣布,两款“百聆”语音模型正式开源,两款模型迎来升级。 根据介绍,其只需 3 秒录音,就能让你的声音无缝切换语种、方言与情绪 —— 普通话、粤语、日、英、开心、愤怒……9 种通用语言、18 种方言,通通搞定。 升级Fun-CosyVoice3 模型升级:首包延迟降低 50%,中英混字准确率翻倍,支持 9 语种 18 方言口音、跨语种克隆与情感控制;Fun-ASR 模型能力增强:噪声场景准确率 93%、支持歌词与说唱识别、31 语种自由混说、方言口音覆盖,并将流式识别模型的首字降低到 160ms。

NeurIPS 2025|指哪打哪,可控对抗样本生成器来了!
近日,在全球人工智能领域最具影响力的顶级学术会议 NeurIPS(神经信息处理系统大会)上, 清华大学和蚂蚁数科联合提出了一种名为 Dual-Flow 的新型对抗攻击生成框架。 简单来说,Dual-Flow 是一个能够从海量图像数据中学习 “通用扰动规律” 的系统,它不依赖目标模型结构、不需要梯度,却能对多种模型、多种类别发起黑盒攻击。 其核心思想是通过 “前向扰动建模 — 条件反向优化” 的双流结构,实现对抗样本的高可迁移性与高成功率,同时保持极低的视觉差异。

EMNLP 2025 | 视频理解Token压缩新范式,减少70.8%推理延迟!
在大语言模型的浪潮中,视频大语言模型(VideoLLMs)正以惊人的速度进化,生成的响应越来越精细。 然而,“慢”与计算量大依然是制约其大规模应用的最大痛点。 视频序列中海量视觉token导致的二次方复杂度,让处理一个长视频往往需要漫长的等待,尤其在高分辨率或长序列场景下。
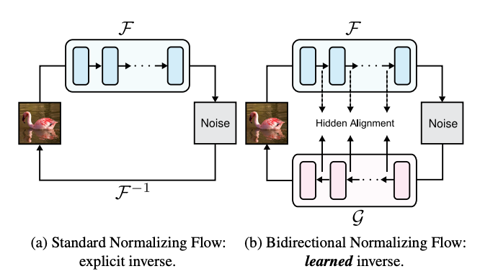
何恺明组三位本科生领衔!持续聚焦Flow模型,突破归一化流生成效率瓶颈
鱼羊 发自 凹非寺. 量子位 | 公众号 QbitAI何恺明团队新作,持续聚焦Flow模型。 与MeanFlow对流匹配的优化不同,这次主要旨在解决归一化流在生成模型中的局限。