
作者张书海是华南理工大学博士四年级学生,主要研究方向为 AI 生成检测、对抗防御、模型加速等,在人工智能国际顶级会议 NeurIPS、ICML、ICLR、CVPR 和 IJCAI、ICCV 以及领域权威期刊 IEEE TIP、TCSVT 和 Neural Networks 发表论文共 15 篇。
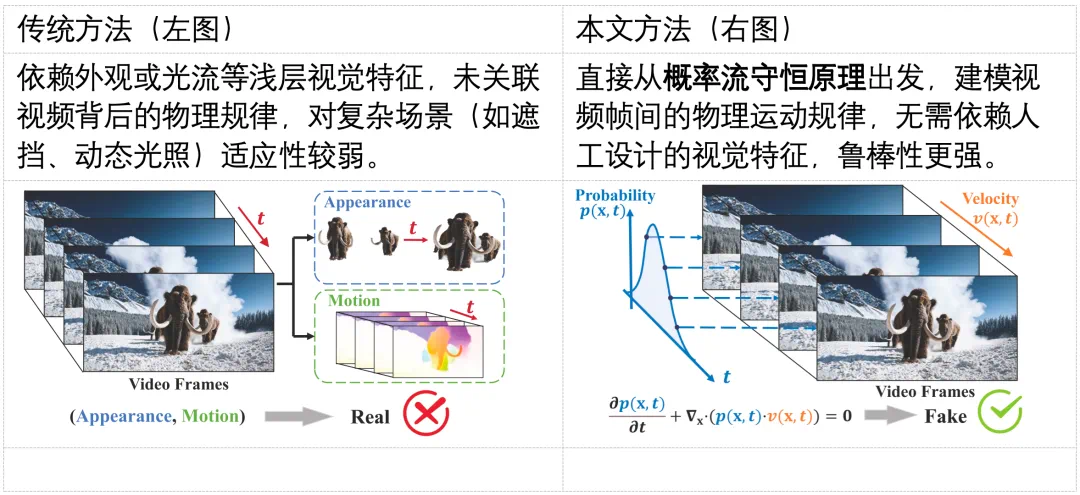
随着生成式 AI(如 Sora)的发展,合成视频几乎可以以假乱真,带来了深度伪造与虚假信息传播的风险。现有检测方法多依赖表层伪影或数据驱动学习,难以在高质量生成视频中保持较好的泛化能力。其根本原因在于,这些方法大都未能充分利用自然视频所遵循的物理规律,挖掘自然视频的更本质的特征。
真实世界的视觉现象受物理过程支配,而生成模型难以完美遵循这些规律。因此,基于物理时空一致性的生成视频检测范式更具普适性和可解释性。然而,高维时空物理规律通常由复杂偏微分方程刻画,直接建模这些规律极具挑战性,如何构建有效的物理驱动的统计量,仍是核心难题。
本文介绍发表于 NeurIPS 2025 的文章《Physics-Driven Spatiotemporal Modeling for AI-Generated Video Detection》。
文章从第一性原理出发,提出了归一化时空梯度(NSG)统计量,通过概率流守恒原理量化视频空间概率梯度与时间密度变化的比值,揭示生成视频中的物理不一致性;理论分析了生成视频与真实视频的 NSG 分布差异,证明了生成视频与真实视频在该统计量的 MMD 距离大于真实视频之间的距离;基于该统计量提出了通用的视频检测方法 NSG-VD,该方法对自然视频的分布进行建模,不依赖特定生成模型,对未知生成范式(如 Sora)和迁移场景具有较强的检测效果。

论文链接: https://arxiv.org/abs/2510.08073v1
代码链接: https://github.com/ZSHsh98/NSG-VD
实验表明 NSG-VD 方法在 Recall 和 F1-score 指标分别超越已有最新方法 16.00% 和 10.75%。
研究背景:AI 视频检测的困境
尽管生成式 AI 技术在视频合成领域取得了突破性进展,但检测领域的研究却面临着新的瓶颈。与图像不同,视频同时包含空间结构与时间动态两类复杂依赖关系,其真实演化过程往往受到多种物理约束(如运动连续性、能量守恒等)共同支配。要准确识别生成视频,检测模型不仅需要理解空间纹理的统计特征,还必须捕捉时间维度上连贯且可解释的变化模式。
然而,现有大多数检测方法仍主要聚焦于表层信号的不一致性,如局部光流异常或视觉纹理伪影。这些特征在早期生成模型中较为明显,但在如今高质量的视频生成中已被显著削弱。另一方面,依赖大规模标注数据的深度学习方法虽然在特定数据集上取得了优异表现,却难以泛化至未见过的生成范式,特别是在新兴模型(如 Sora)出现后,检测性能会急剧退化。
因此,当前 AI 视频检测的核心困境在于:如何超越表面特征层面的统计差异,从自然视频的物理演化规律出发,构建一种具有普适性性且对未知生成模型稳健的检测框架。
基于这一思考,作者提出一个关键问题:
如何从视频本身的物理层面刻画自然视频的时空演化规律,从而揭示生成视频中极其细微且潜在的物理异常?
事实上,真实世界中物体的运动遵循着明确的物理约束,例如一辆车从左向右行驶时,其像素的亮度与位置变化应当是连续且符合运动规律的。换言之,我们可将视频的演化过程视为一种「概率流体」的时空流 —— 真实视频中的动态如同稳定、连续的流,而许多 AI 生成的视频则可能在流上表现出断裂、抖动或其他违反物理一致性的异常。
因此,作者将视频的演化过程形式化为一种概率流的时空流动,并通过归一化时空梯度(NSG)统计量来量化这种流的物理一致性。
物理一致性建模:从概率流守恒到时空梯度
首先将视频帧序列建模为高维空间中的概率分布演化过程。设 x 表示视频帧在空间中的像素表示,t 表示时间,p (x,t) 为视频在时刻 t 的概率密度函数。类比于流体力学中的质量流动 [1],定义概率流密度(probability flow density):
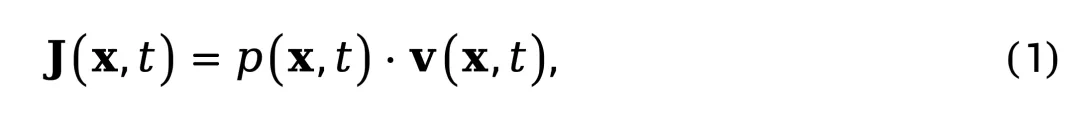
其中 v (x,t) 表示概率流速度场,描述了概率密度在时空中的演化方向与速率。
概率质量守恒要求系统满足连续性方程(continuity equation)[2],这是物理学中描述守恒量传输的基本方程:
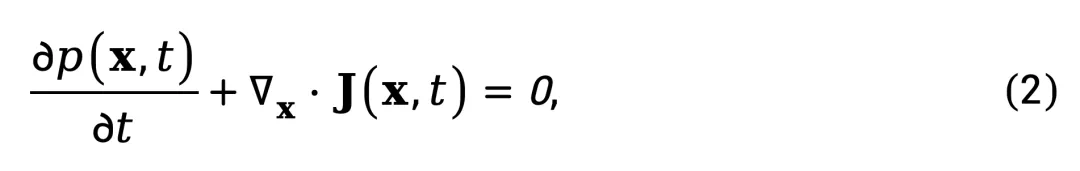
其中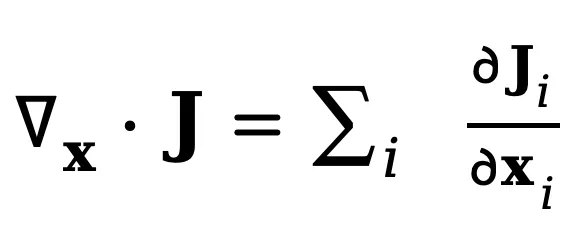 表示概率流密度 J 的散度,衡量了某点处概率流的净流出量。直观上,该方程表明:某点概率密度的增加率(∂p/∂t)等于该点处概率流的净流入量(−∇⋅J)。换句话说,概率质量不会凭空产生或消失,只会在空间中连续流动。注意该守恒方程是普适的物理表达形式,描述任意时间演化的概率密度的守恒规律 [2],而不仅限于视频。
表示概率流密度 J 的散度,衡量了某点处概率流的净流出量。直观上,该方程表明:某点概率密度的增加率(∂p/∂t)等于该点处概率流的净流入量(−∇⋅J)。换句话说,概率质量不会凭空产生或消失,只会在空间中连续流动。注意该守恒方程是普适的物理表达形式,描述任意时间演化的概率密度的守恒规律 [2],而不仅限于视频。
将 J (x,t) 代入上式,并对 logp (x,t) 应用链式法则,整理可得:
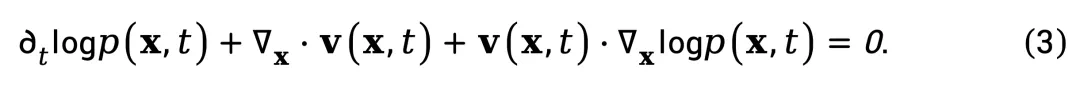
该式揭示了速度场 v (x,t) 如何同时编码概率分布的时间演化与空间梯度。
为求解 v (x,t),可以关注式(3)的主导项。在平滑变化的分布假设 [3] 下,散度项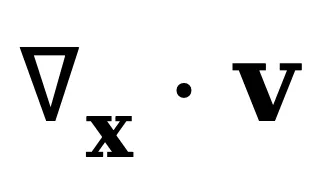 是次要的,这一条件在流体力学 [2] 与量子力学 [4] 中被广泛采用,则式(3)可简化为:
是次要的,这一条件在流体力学 [2] 与量子力学 [4] 中被广泛采用,则式(3)可简化为:
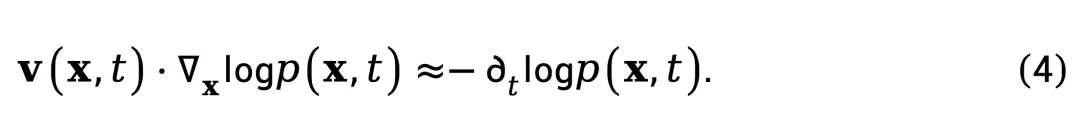
该式表明,在概率分布平滑演化的区域,速度场与空间概率梯度的点积近似于时间概率变化率的负值。由于式(4)中 v (x,t) 的解不唯一,作者通过归一化处理来提取本质特征。将两边除以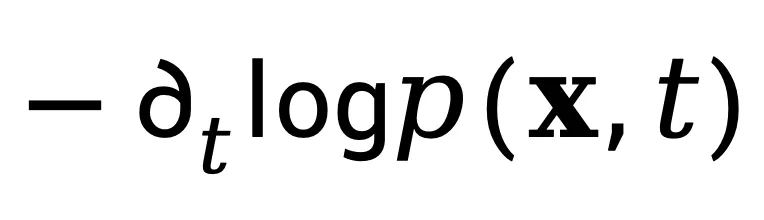 ,得到:
,得到:
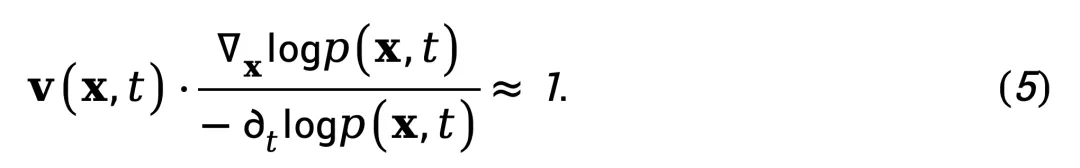
归一化时空梯度(NSG)统计量
式(5)表明,真实视频会保持速度场与空间概率梯度对时间密度变化比值的乘积恒定。基于此,定义归一化时空梯度(NSG)统计量:
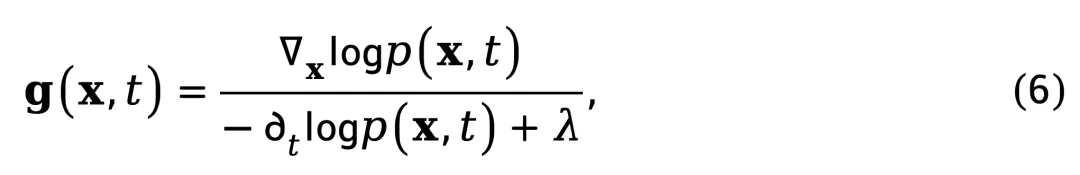
其中,λ 是维持数值稳定而加的正则项。该统计量衡量了单位时间密度变化所对应的空间概率梯度强度与方向,刻画视频在时空维度上的动态一致性。虽然式 (4) 为便于估计弱化了散度项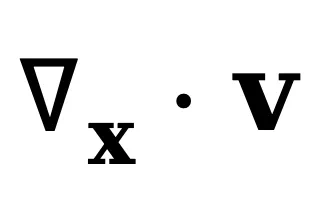 ,但 NSG 并不依赖于严格的
,但 NSG 并不依赖于严格的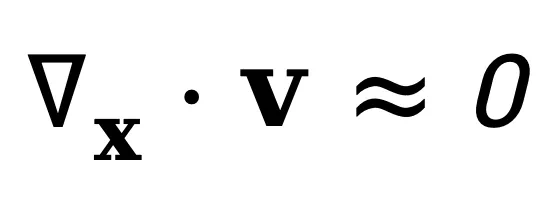 假设,这是因为 NSG 的比值结构同时建模式 (3) 中来自时间导数与空间梯度二者的信号且通过比值进行放大,从而仍能有效揭示时空不一致性,且实验表明本方法在复杂场景下仍保持稳健性。
假设,这是因为 NSG 的比值结构同时建模式 (3) 中来自时间导数与空间梯度二者的信号且通过比值进行放大,从而仍能有效揭示时空不一致性,且实验表明本方法在复杂场景下仍保持稳健性。
从物理直觉上看,真实视频的 NSG 呈现平滑连续的「流线」结构,反映出自然运动的连贯性;而 AI 生成视频在此过程中出现断层、抖动等非物理现象,即违反了连续性方程。具体而言:
分子
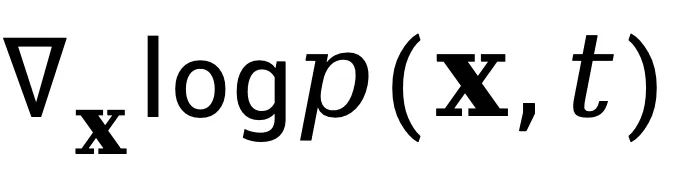 :表示视频在空间维度上的概率分布梯度,反映了像素亮度或纹理结构的局部变化强度与方向。
:表示视频在空间维度上的概率分布梯度,反映了像素亮度或纹理结构的局部变化强度与方向。分母
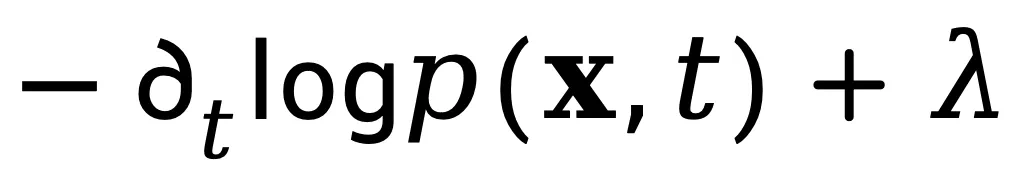 :表示视频在时间维度上的密度变化率,描述了帧间像素分布演化的动态特性。
:表示视频在时间维度上的密度变化率,描述了帧间像素分布演化的动态特性。
两者结合后,NSG 为不同视频场景提供了统一的一致性度量特征,可稳健揭示生成视频中的物理异常。
NSG 的计算近似
在提出归一化时空梯度(NSG)之后,关键问题在于:如何在实际视频中有效、精确地估计该统计量?由于它们涉及高维概率密度的显式建模,直接计算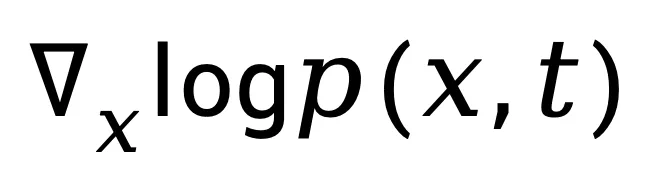 和
和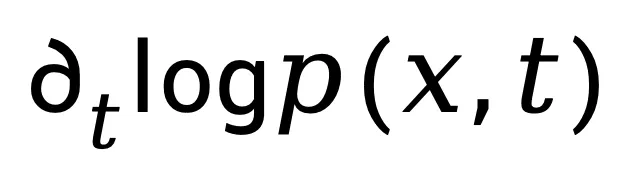 是极其困难的。为此,作者引入了扩散模型(Diffusion Model)的梯度学习能力,构建了一个高效的 NSG 估计器。
是极其困难的。为此,作者引入了扩散模型(Diffusion Model)的梯度学习能力,构建了一个高效的 NSG 估计器。
空间梯度估计:用扩散模型建模梯度特征
现代扩散模型(或更广义的 score-based 模型)本质上学习的是数据分布的 score 函数 [5]:
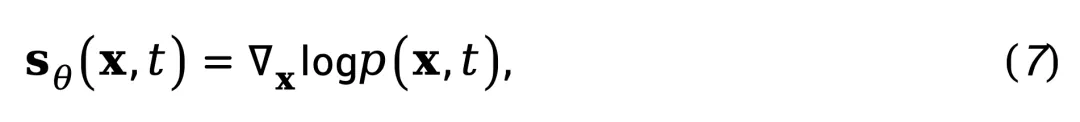
即概率密度对输入的梯度。这意味着,扩散模型实际上隐式捕获了真实数据在高维空间中的概率流结构。因此,可以用一个预训练的 score 网络 s_θ,来近似计算视频帧的空间概率梯度:
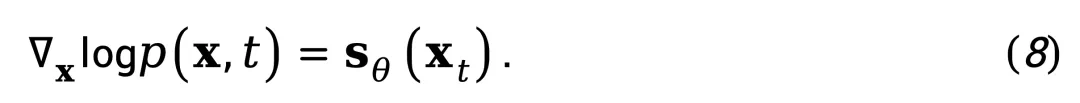
式(8)实现了从生成模型到判别器的转换,作者不再利用扩散模型生成视频,而是让它「感知」视频帧是否符合自然分布的空间结构。
时间导数估计:基于亮度不变假设
在时间维度上,直接求取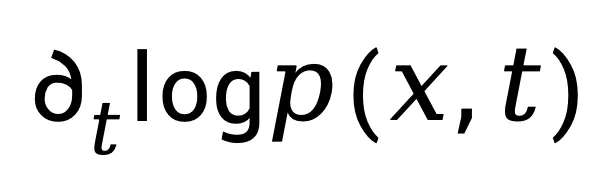 依然不可行。作者基于亮度不变假设(brightness constancy assumption)[6] 可以近似得到:
依然不可行。作者基于亮度不变假设(brightness constancy assumption)[6] 可以近似得到:
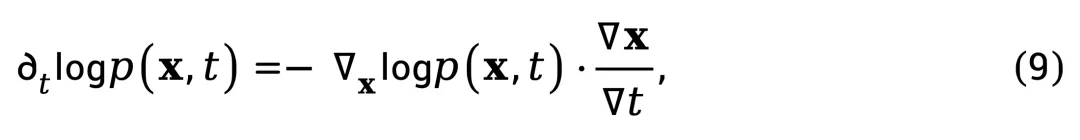
其中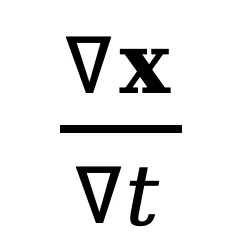 可通过帧间差分获得。该项刻画了像素在时序方向上的变化速率,等价于一种「局部运动感知」特征。
可通过帧间差分获得。该项刻画了像素在时序方向上的变化速率,等价于一种「局部运动感知」特征。
总的估计表达式
将上式与 score 估计结合,可得到 NSG 的可计算近似式:
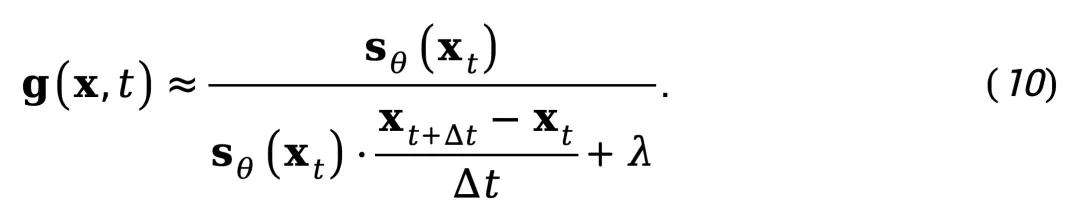
该公式仅需一次 diffusion 模型前向计算(用于获取 s_θ(x_t))与帧间差分,即可在无需显式光流估计或复杂运动分解的情况下,求得视频的 NSG 分布。
NSG-VD:基于物理一致性的时空视频检测框架
在获得 NSG 特征后,作者提出检测算法 NSG-VD。
核心思想:通过计算待测视频与真实视频参考集在 NSG 特征空间中的分布差异,利用最大均值差异(MMD)作为检测指标,从而揭示生成视频在物理一致性上的异常特征。
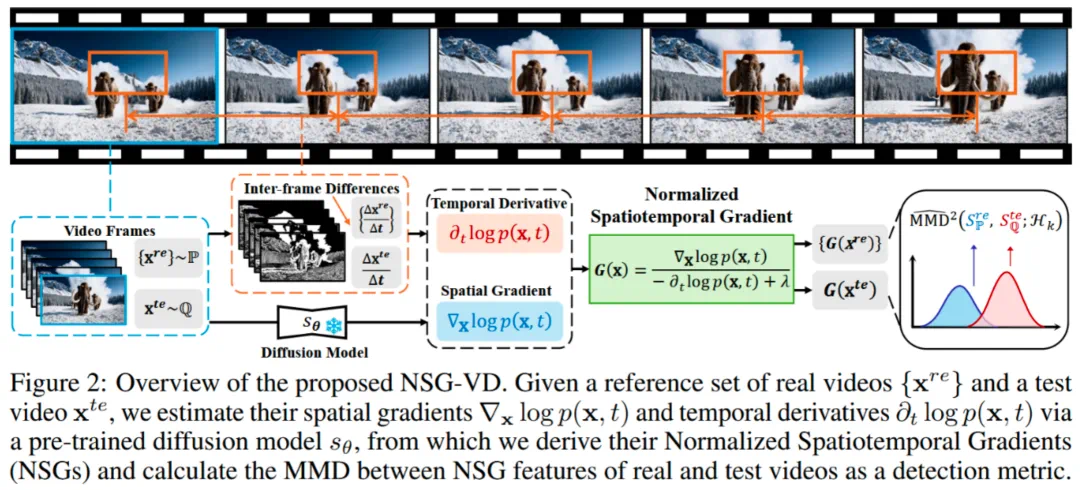
检测流程
首先,构建一组真实视频参考集:

并为每个视频 x 提取其在 T 帧上的 NSG 特征序列:

给定一个待检测视频 ,计算其 NSG 特征
,计算其 NSG 特征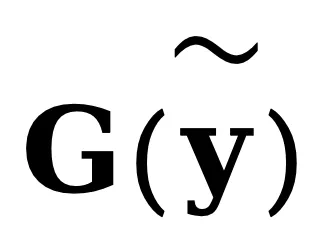 与参考集特征分布之间的最大均值差异,用于量化二者在特征空间的分布距离:
与参考集特征分布之间的最大均值差异,用于量化二者在特征空间的分布距离:
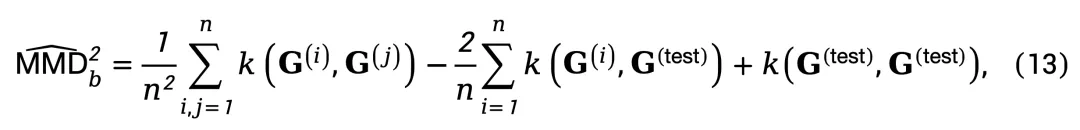
其中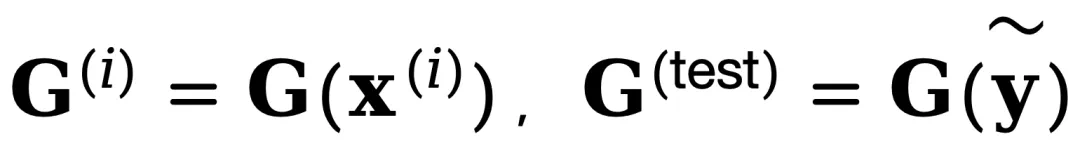 ,核函数 k_ω 将 NSG 特征映射至高维再生核希尔伯特空间,以捕捉细微的分布差异。值得注意的是,尽管 MMD 传统上用于分布级比较,近期研究表明其在单样本检测中也能有效地量化单个样本与参考分布的偏差 [7,8]。但必须强调,NSG-VD 的核心优势源自 NSG 本身对物理一致性的建模,而非仅依赖于 MMD 的检测能力。
,核函数 k_ω 将 NSG 特征映射至高维再生核希尔伯特空间,以捕捉细微的分布差异。值得注意的是,尽管 MMD 传统上用于分布级比较,近期研究表明其在单样本检测中也能有效地量化单个样本与参考分布的偏差 [7,8]。但必须强调,NSG-VD 的核心优势源自 NSG 本身对物理一致性的建模,而非仅依赖于 MMD 的检测能力。
随后,定义检测函数:
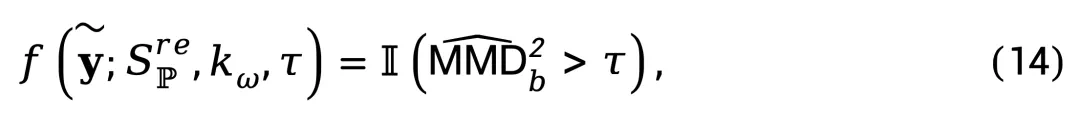
其中 I (⋅) 为指示函数,τ 为判定阈值。根据函数输出进行视频真伪分类:
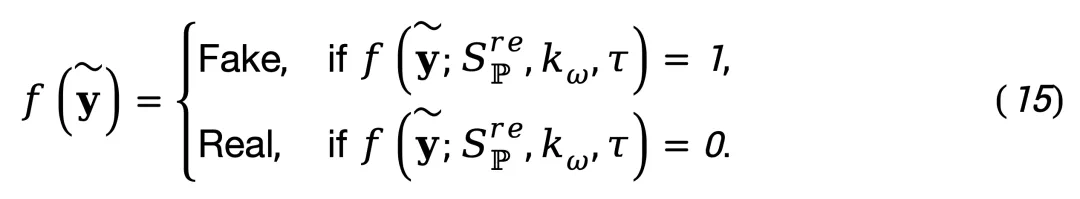
为增强判别能力,作者采用可学习的深度核 [9] 并在训练集数据上对其参数进行训练。
理论保障
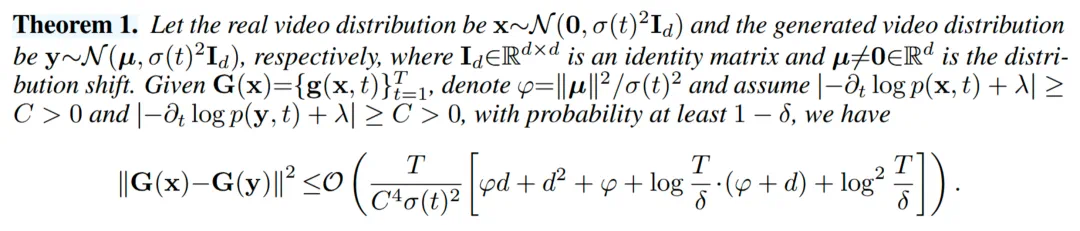
该定理表明,真实视频和生成视频的 NSG 特征距离上界与分布偏移程度 μ 有关。分布偏移越小,两者特征距离上界越小;偏移越大,分离越明显。这也意味着真实数据间的 NSG 特征的 MMD 比真实与生成数据间的更小,据此可用 NSG 特征区分真实和生成视频。
实验验证:跨生成模型与数据场景的性能分析
作者在大型基准 GenVideo 上进行了全面评估,包含 10 个不同的生成模型,涵盖开源和闭源系统。实验表明,NSG-VD 在多个标准评测中显著优于现有基线方法:
标准评测设置下的卓越性能
NSG-VD 在 Kinetics-400(真实视频) 与 Pika(生成视频) 的混合数据训练后,展现出出色的泛化能力。在十类 AI 生成视频上的平均检测性能达到 Recall 88.02%、F1 90.87%,已全面超越此前的最佳方法 DeMamba。特别是在 Sora 等闭源生成模型检测上,NSG-VD 取得了 78.57% 的 Recall,相比 DeMamba 的 48.21% 提升超过 30 个百分点,展现出显著的性能优势。
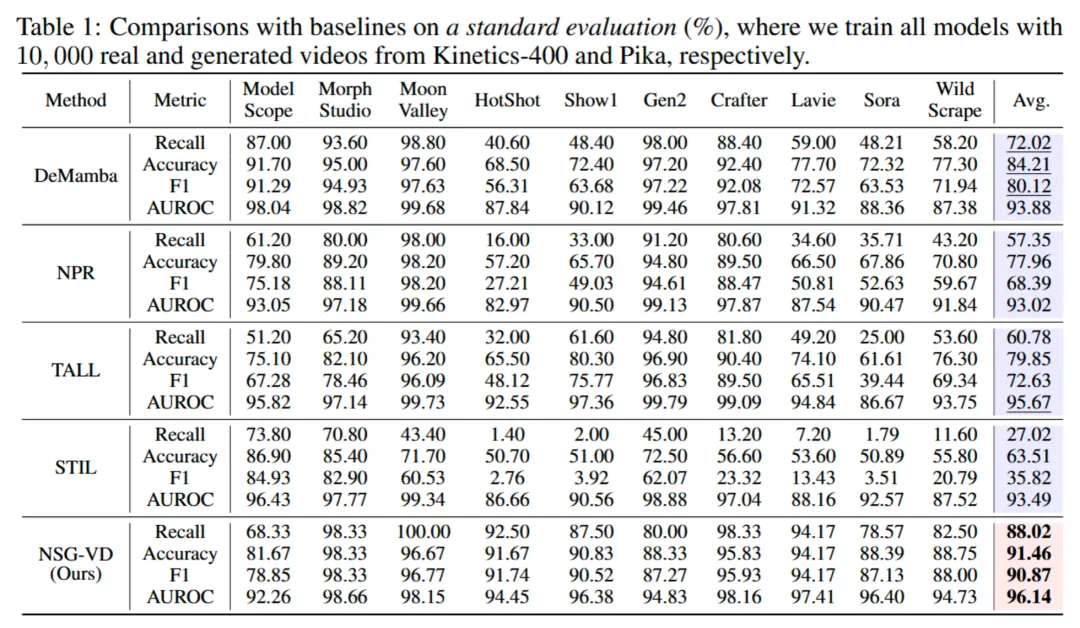
数据不平衡场景下的鲁棒性
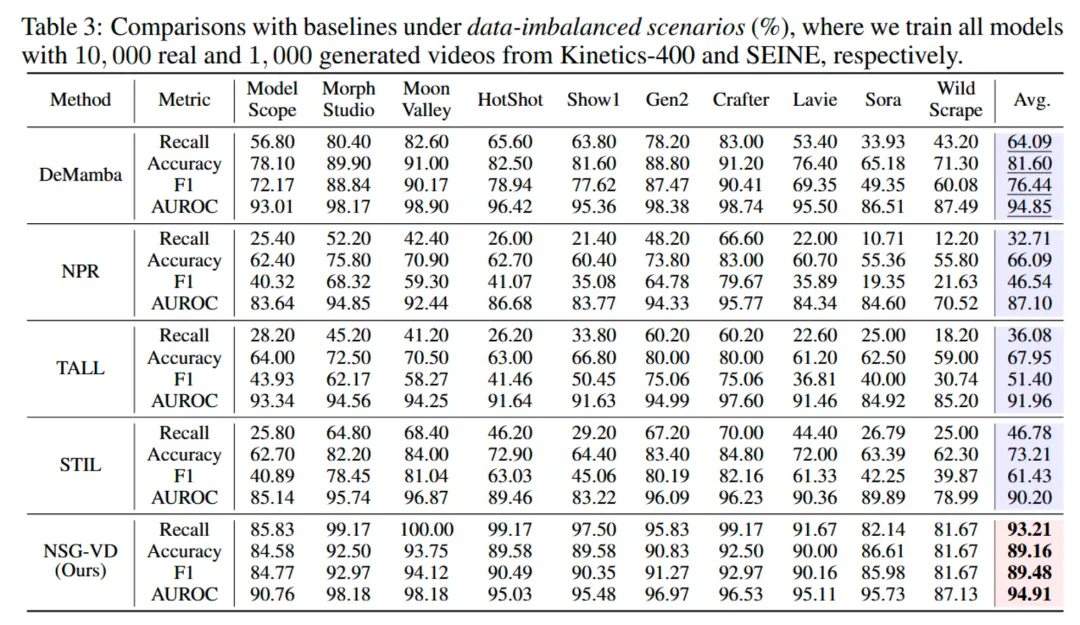
在实际应用中,获取大规模 AI 生成视频 的训练数据往往具有较高成本与难度。为评估模型在更贴近真实场景下的表现,作者在训练集仅包含 1,000 条 SEINE 的生成数据上进行了实验。
结果表明,即使在仅使用 1,000 条 AI 生成视频 进行训练的条件下,NSG-VD 仍展现出显著的稳健性与泛化能力:其在 Sora 上的召回率(Recall)高达 82.14%,远超 DeMamba (33.93%) 与 NPR (10.71%) 等基线模型。这充分验证了 NSG-VD 的高数据效率,其性能提升并非依赖于大规模训练数据,而源于基于物理一致性的第一性原理建模的有效性。
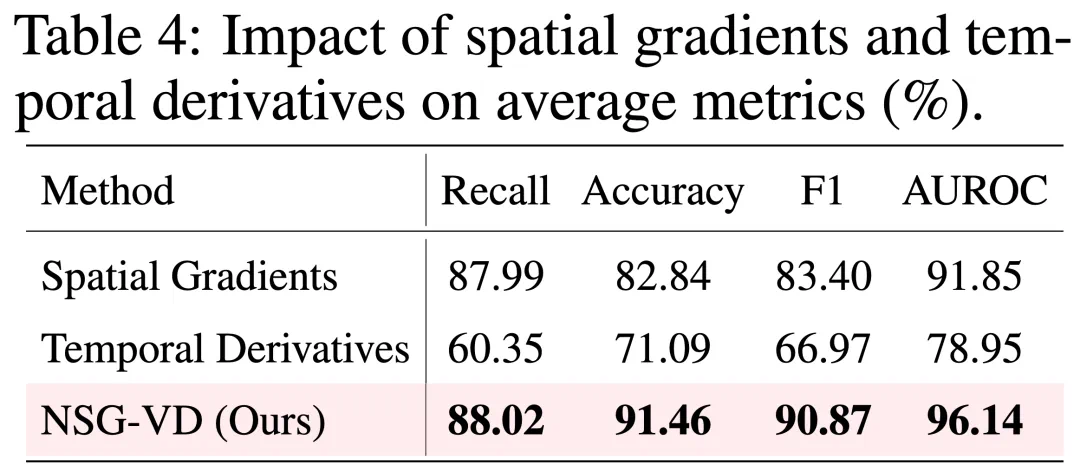
消融研究:验证物理建模的有效性
为进一步验证 NSG 各组成模块的作用,作者进行了系统性的消融实验。
实验结果表明,当仅使用空间概率梯度时,模型的 Recall 为 87.99%;仅使用时间密度变化时,Recall 降至 60.35%。将两者进行物理一致性融合后,NSG-VD 的 Recall 提升至 88.02%,F1 值进一步达到 90.87%。这一结果充分说明,基于物理公式的时空联合建模能够有效捕捉视频生成过程中的细微差异,不仅验证了该建模范式的必要性,也凸显了其显著的性能优势。
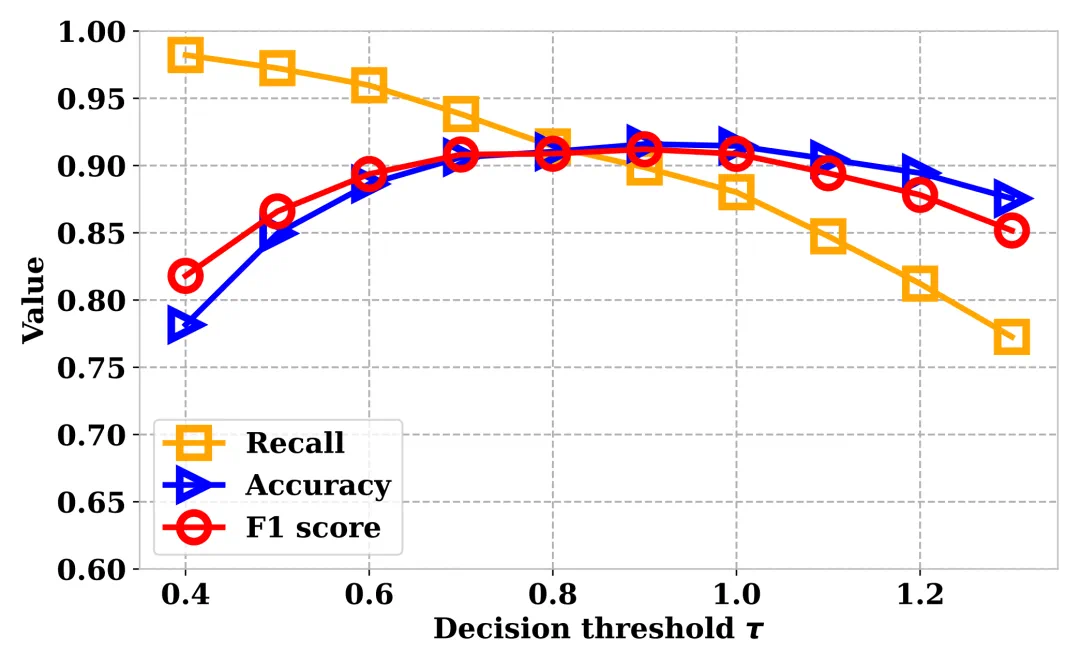
决策阈值鲁棒性分析
在实际部署中,方法的超参数敏感性至关重要。对此,作者分析了决策阈值 τ 的影响:
结果表明,在 τ∈[0.7,1.1] 的阈值范围内,NSG-VD 的各项指标(Recall、Accuracy、F1)稳定性,证实了 NSG 特征对真伪视频的强大判别能力。该方法的核心在于物理驱动的时空梯度建模,而非依赖生成器特定伪影,因而能够稳健地检测来源多样的生成内容。
总结与展望
本文提出了基于物理守恒的时空建模视频检测框架 NSG-VD,通过归一化时空梯度(NSG)统计量量化视频在空间和时间维度上的物理一致性,实现对 AI 生成视频的通用检测。实验表明,NSG-VD 在多种生成模型、数据不平衡场景及迁移测试中均表现出卓越的泛化能力和稳健性,显著优于现有方法。
NSG-VD 的核心创新在于将物理一致性约束引入检测任务,通过 NSG 特征捕捉生成视频中潜在的物理规律违例。这种物理驱动范式无需依赖特定生成模式的数据,在面对多样化生成内容时展现出强鲁棒性,即便在数据不平衡场景下也能保持稳定性能。
在当前「真假难辨」的生成时代,NSG-VD 引领我们从「图像的真实」走向「物理的真实」—— 不关注视频有多逼真,而关注其是否遵守物理规律。尽管该方法仍依赖一定的物理假设并存在计算开销,未来工作将着力于开发更精细的物理模型、优化轻量化计算方案,并探索实时检测应用场景的可行性。
参考文献
[1] Hodge, W. B., S. V. Migirditch, and William C. Kerr. "Electron spin and probability current density in quantum mechanics." American Journal of Physics 82.7 (2014): 681-690.
[2] Batchelor, George Keith. An introduction to fluid dynamics. Cambridge university press, 2000.
[3] Panton, Ronald L. Incompressible flow. John Wiley & Sons, 2024.
[4] Böhm, Arno. Quantum mechanics: foundations and applications. Springer Science & Business Media, 2013.
[5] Song, Yang, and Stefano Ermon. "Generative modeling by estimating gradients of the data distribution." Advances in neural information processing systems 32 (2019).
[6] Horn, Berthold KP, and Brian G. Schunck. "Determining optical flow." Artificial intelligence 17.1-3 (1981): 185-203.
[7] Zhang, Shuhai, et al. "Detecting Machine-Generated Texts by Multi-Population Aware Optimization for Maximum Mean Discrepancy." The Twelfth International Conference on Learning Representations.
[8] Zhang, Shuhai, et al. "Detecting adversarial data by probing multiple perturbations using expected perturbation score." International conference on machine learning. PMLR, 2023.
[9] Liu, Feng, et al. "Learning deep kernels for non-parametric two-sample tests." International conference on machine learning. PMLR, 2020.


