
本文的作者来自清华大学、北京大学、武汉大学和上海交通大学,主要作者为清华大学硕士生袁承博、武汉大学本科生周睿和北京大学博士生刘梦真,通讯作者为清华大学交叉信息研究院的高阳助理教授。
近期,Google DeepMind 发布新一代具身大模型 Gemini Robotics 1.5,其核心亮点之一便是被称为 Motion Transfer Mechanism(MT)的端到端动作迁移算法 —— 无需重新训练,即可把不同形态机器人的技能「搬」到自己身上。不过,官方技术报告对此仅一笔带过,细节成谜。
正当业内还在揣摩 MT 的「庐山真面目」时,清华、北大等高校联合团队率先把同类思路推到更高维度:直接把「动作迁移」做到人类 VR 数据上!
更难得的是,他们第一时间放出完整技术报告、训练代码与权重,全部开源可复现。下面带你快速拆解这项「人类→机器人」零样本动作迁移新范式。

论文链接:https://arxiv.org/abs/2509.17759
项目链接:https://motiontrans.github.io/
代码地址:https://github.com/michaelyuancb/motiontrans
什么是 MotionTrans 框架

MotionTrans:端到端、零样本、多任务的迁移人类技能
该论文提出 MotionTrans—— 业界纯端到端、人类→机器人的 Zero-shot RGB-to-Action 技能迁移框架,一举打通「看人会」到「我会做」的最后一公里。
零样本迁移:无需任何同任务机器人演示,仅靠人类佩戴 VR 采集的 数据,机器人即可一次性学会倒水、拔插座、关电脑、收纳等日常操作,实现真正的「眼会到手会」。
小样本精进:在零样本基础上,再用极少量(约 5–20 条)机器人本体数据微调,即可把 13 种人类技能推至高成功率。
端到端且架构无关:整套算法为端到端,且与机器人模型架构完全解耦;作者已在 Diffusion Policy 与 VLA 两大主流范式上「即插即用」,验证零样本迁移的通用性与可扩展性。
MotionTrans 算法是怎么实现的
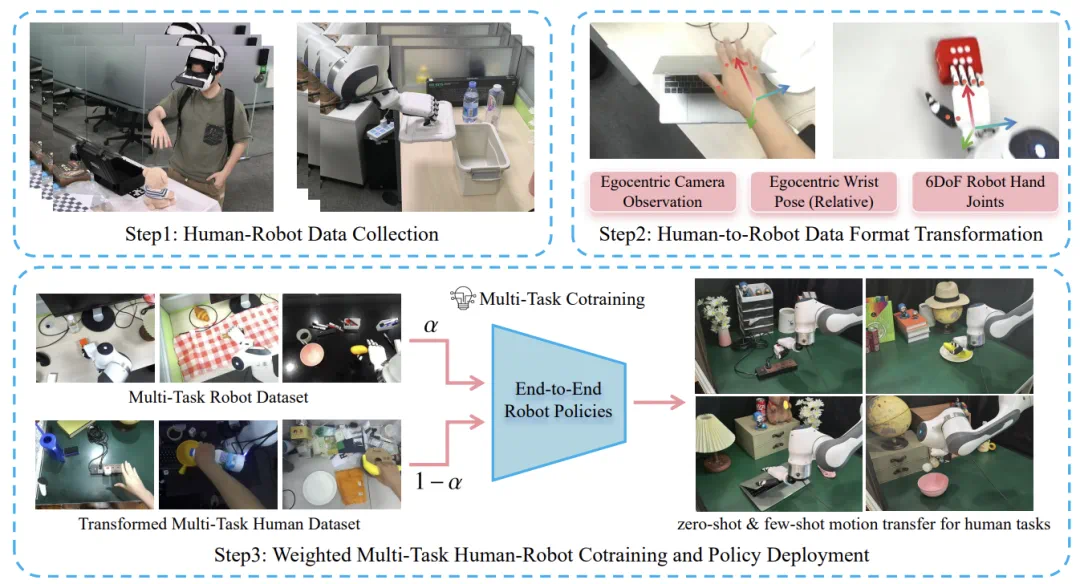
MotionTrans算法框架概览图
MotionTrans 算法框架是一套简单易用,方便扩展的系统。具体来说,团队首先自研了基于 VR 设备的人类数据采集系统(已开源)。该系统支持便携式的同时采集人类第一人称视频、头部运动、腕部位姿和手部动作。
然后,团队通过坐标系变换和手部重定向(Retargeting)等方法,将人类数据转换为机器人格式。具体来说:
第一人称视频:人类数据与机器人数据都使用第一人称视角来作为视觉感知。
相对腕部动作表征:为了进一步缩小人类动作与机器人动作之间的差距,团队使用相对位腕部姿(Relative Pose)来作为腕部动作表征。
手部重定向:团队使用 Dex-Retargeting 工具将人类手部动作转换为机器手对应的关节运动。
除此之外,团队还提出使用人类 - 机器人统一的动作归一化(Unfied Action Normalization)以及赋权重的人类 - 机器人联合训练算法(Weighted Human-Robot CoTraining),来进一步实现人类向机器人技能迁移的效果。MotionTrans 是一套通用的端到端训练框架。
因此,团队选择了最为主流的 Diffusion Policy 和 VLA 模型来作为模型架构。最后,团队采集了一个大规模人类 - 机器人数据数据集,包含 3200 + 轨迹、15 个机器人任务、15 个 (与机器人任务不同的) 人类任务和超过 10 个真实生活场景。
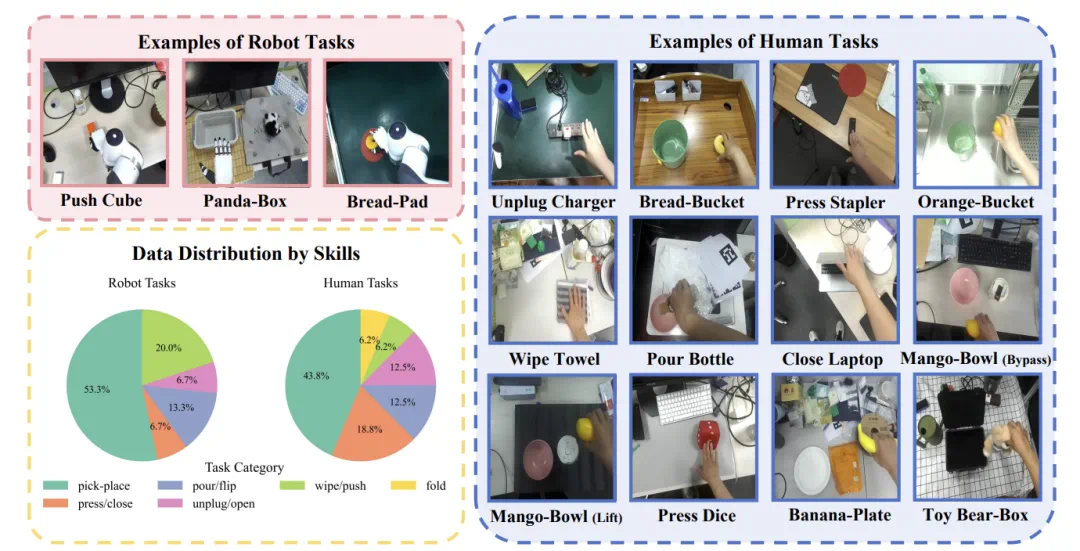
MotionTrans Dataset:高多样性的大规模人类-机器人数据集
零样本表现:直接从人类数据学会若干技能
团队首先评估零样本迁移:直接把「人类集合」里的任务部署到机器人,对于这些任务,全程未采集过任何一条机器人演示。
结果显式,在全部 13 个任务上,机器人模型的平均成功率可以达到 20 %,其中:Pick-and-Place 系列表现最佳,成功率可达 60% – 80%;VLA 模型在 「关电脑」任务上更是拿下 100 % 一次性通关;其它更为困难的任务,如拔插座、开盒子、避障放置等也取得可观的成功率。
除此之外,即便成功率为 0 的任务,MotionTrans 依旧学会了正确的动作方向与趋势。以擦桌子为例,模型虽未能把抹布推到足够远,但已清晰输出 “向前推” 的连续动作,验证了框架在零机器人数据条件下能够捕获任务核心语义。

MotionTrans支持零样本实现端到端的人类向机器人技能迁移
微调后表现:仅用少量机器人微调数据,精通 13 个新任务
在随后的「小样本微调」阶段,团队只给每个「人类原生」任务补采了 5 条机器人轨迹 —— 短短几分钟的示教,便让模型在 13 个任务上的平均成功率从 20% 的零样本基线跃至约 50%;当把机器人轨迹增加到 20 条,平均成功率更是直达到 80%。
除此之外,实验结果显示,同时使用机器人数据和人类数据联合训练的 MotionTrans 方法要显著优于对比的 Baseline 方法。
最后,团队还实施了大量消融试验和探索性实验,来验证 MotionTrans 框架设计的合理性,以及揭示 Motion Transfer 发生的底层原理与机制。
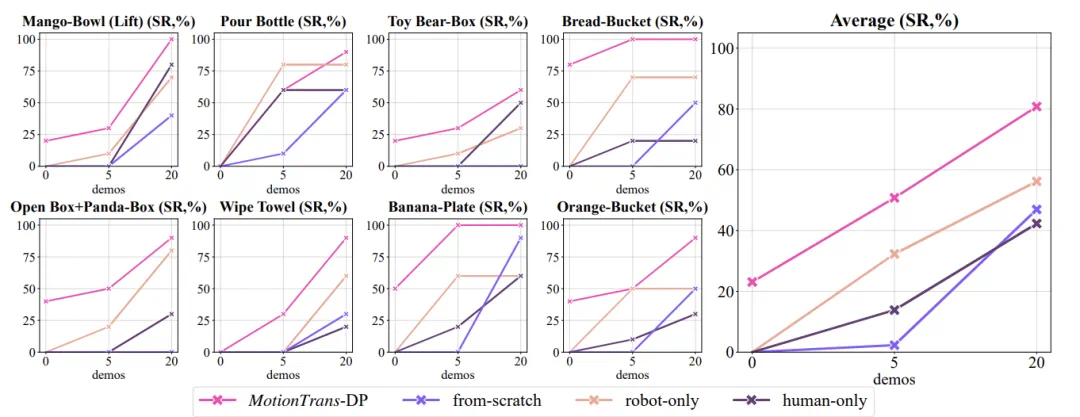
MotionTrans算法机器人数据微调效果曲线图
总结:人类数据学习的全新视角
MotionTrans 首次向社区证明:即便是最前沿的端到端 VLA 模型,也能在「零机器人演示」的严苛设定下,仅凭人类 VR 数据就解锁全新的技能。
这一结果改变了人们对人类数据的认知 —— 它不再只是提升鲁棒性或加速收敛的 「调味剂」,而是足以独立充当「主菜」,让机器人直接习得陌生任务。框架本身简洁直白、模块化设计,采、转、训三步即插即用,未来面对更大规模的数据集或参数量级的模型,只需横向扩容即可适用。
最后,团队开源了所有的数据、代码和模型,为后续的相关研究提供支持。
更多细节请参阅原论文。


