资讯列表

2M大小模型定义表格理解极限,清华大学崔鹏团队开源LimiX-2M
提到 AI 的突破,人们首先想到的往往是大语言模型(LLM):写代码、生成文本、甚至推理多模态内容,几乎重塑了通用智能的边界。 但在一个看似 “简单” 的领域 —— 结构化表格数据上,这些强大的模型却频频失手。 电网调度、用户建模、通信日志…… 现实世界中大量关键系统的核心数据都以表格形式存在。

跨层压缩隐藏状态同时加速TTFT和压缩KV cache!
我们都知道 LLM 中存在结构化稀疏性,但其底层机制一直缺乏统一的理论解释。 为什么模型越深,稀疏性越明显? 为什么会出现所谓的「检索头」和「检索层」?

GRPO训练不再「自嗨」!快手可灵 x 中山大学推出「GRPO卫兵」,显著缓解视觉生成过优化
论文第一作者为王晶,中山大学二年级博士生,研究方向为强化学习与视频生成;通讯作者为中山大学智能工程学院教授梁小丹。 目前,GRPO 在图像和视频生成的流模型中取得了显著提升(如 FlowGRPO 和 DanceGRPO),已被证明在后训练阶段能够有效提升视觉生成式流模型的人类偏好对齐、文本渲染与指令遵循能力。 在此过程中,重要性比值的 clip 机制被引入,用于约束过于自信的正负样本梯度,避免破坏性的策略更新,从而维持训练的稳定性。

上海旗舰SUV太有生活了:自带淋浴和地暖,32万开卖
智己LS9,基本锁定年度9系卷王了。 以上汽之名,智己发布了旗舰车型LS9,一款车长近5.3米的六座SUV,分为32.28万和35.28万两个版本。 520线激光雷达,英伟达Thor芯片,新一代数字底盘,Momenta一段式端到端……这些全部标配,智能化拉满。
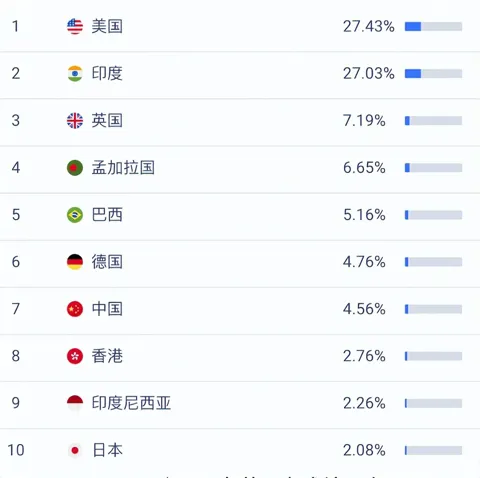
全球首个AI Agent交易市场MuleRun发布2.0版本,上线一个月用户数突破50万
11月13日凌晨0点,全球首个AI Agent交易市场MuleRun(骡子快跑)发布2.0版本,核心升级点包括为用户配置专属Agent团队,和上线多种垂直场景的Agent专题等。 自2025年9月MuleRun发布正式版本以来,仅一个月时间,注册用户数已突破50万,其中美国用户占比最高,达27.43%。 目前,已有上万名全球创作者报名入驻MuleRun,其中包括Quick BI、Funda AI、Piccopilot AI等在内的50 专业团队,为用户提供覆盖电商、数据分析、内容创作等多样化领域的160 Agent服务。

刚刚,GPT-5.1发布,OpenAI开始拼情商
深夜,GPT-5 系列迎来大更新:上线 GPT-5.1 Instant 以及 GPT-5.1 Thinking 模型:GPT-5.1 Instant:ChatGPT 最常用的模型,更温暖、更智能,也更善于遵循指令的模型。 GPT-5.1 Thinking:高级推理模型,在简单任务上更快,在复杂任务上更持久,也更容易理解。 对于新上线的模型,OpenAI 表示出色的 AI 不仅要聪明,还要让人与之对话变得愉悦。

清华团队:1.5B 模型新基线!用「最笨」的 RL 配方达到顶尖性能
如果有人告诉你:不用分阶段做强化学习、不搞课程学习、不动态调参,只用最基础的 RL 配方就能达到小模型数学推理能力 SOTA,你信吗? 清华团队用两个 1.5B 模型给出了答案:不仅可行,还特别高效。 核心发现: 单阶段训练 固定超参数 = SOTA 性能 省一半算力意外之喜: 训练曲线平滑得像教科书,4000 步没遇到任何 "典型问题"关键启示: 充分 scale 的简单 baseline,可能比我们想象的强大得多技术博客::::RL 训练小模型的 "技术军备竞赛"2025 年初,DeepSeek-R1 开源后,如何用 RL 训练 1.5B 级别的推理模型成为了热门研究方向。

中国医生需要怎样的AI?GPT-5、OpenEvidence都输掉实战后,我们有了答案
能真正帮到基层的AI,一定要满足2点:安全有效、人(医生)机(AI)协同。 「倒挂」一纸文件,又将医疗 AI 推到了聚光灯下。 11 月 4 日,国家卫健委发文(以下简称「实施意见」),定调医疗 AI 未来五年的核心目标——「人工智能 基层应用」,被放在「人工智能 医疗卫生」的八大重点方向的首位。

你以为在点「红绿灯」验证身份,其实是在给AI免费打工
如果这是下一代图形验证码,你怎么看? 感觉会经历无数遍「您对 CAPTCHA 的响应似乎无效。 请在下方重新验证您不是机器人」,不知道猫主子们怎么想。

IHES Library:解锁数学物理界的「智慧圣殿」
当现代代数几何的基石由格罗滕迪克奠定,当非交换几何的疆界被孔涅开拓——这些曾在顶尖研究所闪耀的思想火种,如今正式向你敞开大门! 茶思屋科技网站全新上线 IHES Library,收录法国高等科学研究所(Institut des Hautes Études Scientifiques)的 2369 个优质学术视频,由 8 位菲尔兹奖获得者领衔、479 位数学家讲授。 目前 Library 首期已发布 686 个课程视频,后续 1683 个视频将陆续亮相,涵盖数学、物理及跨学科领域。

NeurIPS 2025 | 中科大、港中深、通义千问联合发布CoRT:仅30个样本教会大模型高效推理,token消耗降低50%
近年来,以 OpenAI-o1、Qwen3、DeepSeek-R1 为代表的大型推理模型(LRMs)在复杂推理任务上取得了惊人进展,它们能够像人类一样进行长链条的思考、反思和探索。 然而,这些模型在面对精确的数学计算时,仍然会「心有余而力不足」,常常出现效率低下甚至算错的问题。 一个直观的解决方案,是为模型配备代码解释器(Code Interpreter)等计算工具。

UI生成工具哪家强?6大AI神器深度测评!
Hello,设计朋友们大家好啊,我是五月的枫叶,好久没见喽,最近在做一些后台管理系统,有写需求文档,用到 AI 工具还比较多,AI 进步飞快,真的切身体验 AI 在工作中大大提高工作效率啊! 在生成 UI 界面、需求文档、代码方面都真真切切的应用到实际的工作中。 随着人工智能技术的快速发展,AI 生成 UI 工具正在悄悄改变传统设计架构。

职场急招的AI训练师,工作内容是什么?
更多职业介绍:一、AI 训练师的上下游介绍. 在任何组织里,每个角色都有自己的分工。 在 AI 公司或者 AI 模型公司中,它们也有 4 个关键角色。

用户总怪AI不准?教你用4个方法建立信任度!
面对产品中的 AI 能力,用户的过分信任和不信任都不是好事。 如何通过设计让用户建立起合适程度的信任? 本文列举了一些具体方法和实例。

优必选正式开启8亿订单量产交付
11月12日,优必选首批数百台全尺寸工业人形机器人Walker S2正式开启量产交付,将分批投入产业一线应用。 2025年初至今,优必选Walker系列人形机器人累计订单金额已突破8亿元。

马斯克十年OKR曝光:12大魔鬼关卡!活该他万亿美元薪酬
杰西卡 发自 副驾寺. 智能车参考 | 公众号 AI4Auto特斯拉专为马斯克设计的游戏规则来了! 马斯克的万亿美元薪酬在股东大会上敲定,但新的疑问也随之产生:.

孙正义再次清仓英伟达!上一次教训“价值2500亿美元”
孙正义又让人看不懂了。 就在这个时间点,他清仓了英伟达,没错,是清仓。 随着软银二季度财报公布,财报里明晃晃提到——在第二季度结束后,于2025年10月出售了所持有的3210万股英伟达股份(包括其资产管理子公司持有的股份),套现58.3亿美元(当前约合人民币415亿元)。

罗福莉C位亮相小米,离职DeepSeek后首次官宣
鹭羽 Jay 发自 凹非寺量子位 | 公众号 QbitAI就在今天,罗福莉以C位之姿,首次对外官宣了小米任职。 刚刚,罗福莉在X上高调宣布——正式加入小米,出任MiMo团队负责人。 智能的进化必然会从语言世界走向物理世界,解锁多模态的空间智能——具备感知、推理、生成与行动的能力,这是实现真正通用人工智能(AGI)的关键一步。