从ChatGPT到DeepSeek,强化学习(Reinforcement Learning, RL)已成为大语言模型(LLM)后训练的关键一环。
然而,随着模型参数规模的不断扩大,一个长期被忽视的问题正悄然成为性能瓶颈:重要性采样真的「重要」吗?
近期,由快手与清华合作的研究团队发现,现有的结果监督强化学习范式存在一种深层次的权重错配现象,它不仅让模型「过度自信」,甚至可能导致熵坍缩与训练早熟收敛。
为此,他们提出了一种简单但有效的算法:ASPO(Asymmetric Importance Sampling Policy Optimization)。

「重要性采样」其实并不重要
在强化学习中,重要性采样(Importance Sampling, IS)用于修正旧策略与新策略之间的分布差异,从而让模型能「重用旧数据」而不偏离目标分布。
在小规模强化学习中,这个理论确实有效;然而,在大语言模型的结果监督强化学习中,这一机制却开始「失灵」。
研究团队通过实验证明:
在GRPO类算法中,IS不仅没有带来分布修正的好处,反而成为引发训练不稳定的元凶。
研究者在实验中对比了两种做法:
- 保留原始的IS权重;
- 完全移除IS权重,将其全部设置为1.0。
结果令人惊讶:
- 两种方法在最终准确率上几乎没有差异;
- 移除IS后的模型训练曲线反而更加平滑、稳定;
- 熵值下降速度放缓,重复率降低,KL散度更稳定。
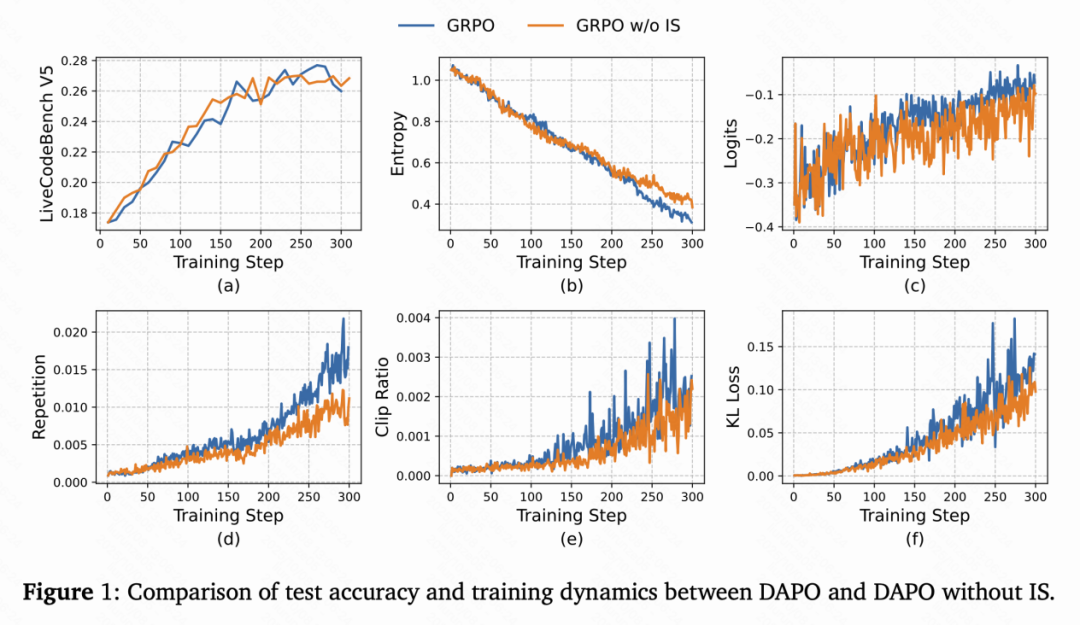
为什么会出现这种现象?
其一,结果监督强化学习中的优势值本身就是不准确的:一方面,不同token对最终答案的贡献是不同的,它们的优势值不应该相同;另一方面,正确的回答中可能包含不正确的推理步骤,这些错误步骤的优势值甚至是相反的。
其二,如下图所示,正优势token的平均IS权重高于负优势token,学习高概率正优势token导致熵下降。
上述分析说明,IS在结果监督强化学习算法中不再是「校正项」,而是变成了token级的权重。
放大权重错配的真相:被放大的「正样本」
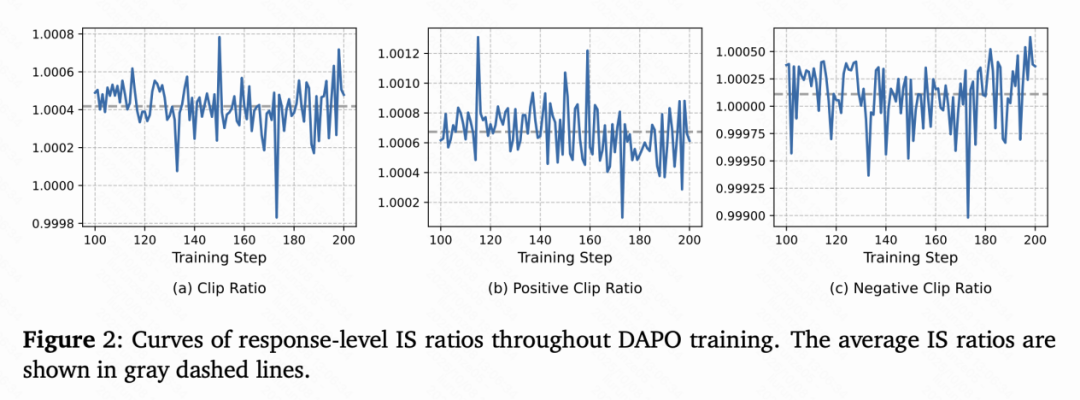
研究团队进一步深入分析发现,IS权重在LLM场景下出现了非对称性错误:
- 对于负优势token,IS权重的变化符合预期:在旧策略概率一定时,当前概率较高,其IS权重也较高,起到合理的抑制作用;
- 但对于正优势token,权重分布却完全反了:在旧策略概率一定时,当前概率越高的token权重越高,概率越低的token权重越低。
也就是说,模型在更新时,会进一步强化那些已经「高分」的token,而忽视那些仍然需要改进的低概率token。这种偏差不断积累,形成一种自我强化循环(self-reinforcing loop),最终导致模型陷入局部最优、输出重复、甚至熵崩塌。
上述权重错配问题在三维空间下清晰可见:
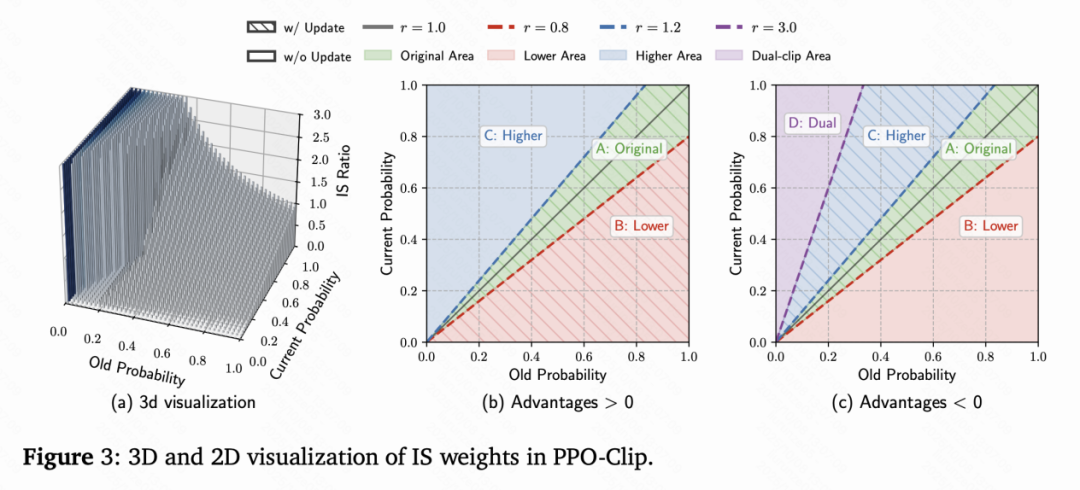
在旧策略概率一定时,当前高概率token的更新权重居高不下,而低概率token被压制至几乎无梯度更新。结果是模型的行为因此逐渐僵化——「越来越像自己」,但也越来越缺乏探索与多样性。
核心思想:翻转正样本权重
ASPO的核心创新,正如其名所示,是一次「不对称翻转」(Asymmetric Importance Sampling,AIS)。
它将正优势token的重要性采样权重取倒数,让低概率token得到更强的更新,而高概率token被适当削弱:
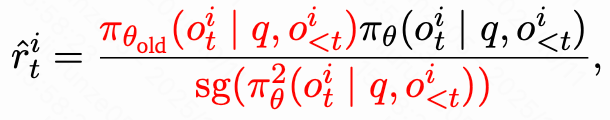
其中,sg(·)表示停止梯度操作。
在此基础上,ASPO还引入了一个Dual-Clipping(软双重裁剪)机制,用于裁剪掉翻转正样本权重后导致的极端值。在裁剪过程中,ASPO采用了类似CISPO中的软裁剪方法,既限制了极端比率导致的不稳定,又保留了正样本梯度的有效流动。
此外,对于所有token,ASPO仍保留原有的硬裁剪机制,对IS比例大于1+ε的正样本和IS比例小于1-ε的负样本裁剪值和梯度。
通过梯度分析,研究者发现:
ASPO在梯度上翻转了IS权重项,使梯度与token概率的倒数成正比,即概率越低的token,更新的梯度越大,增大低概率token的学习力度。
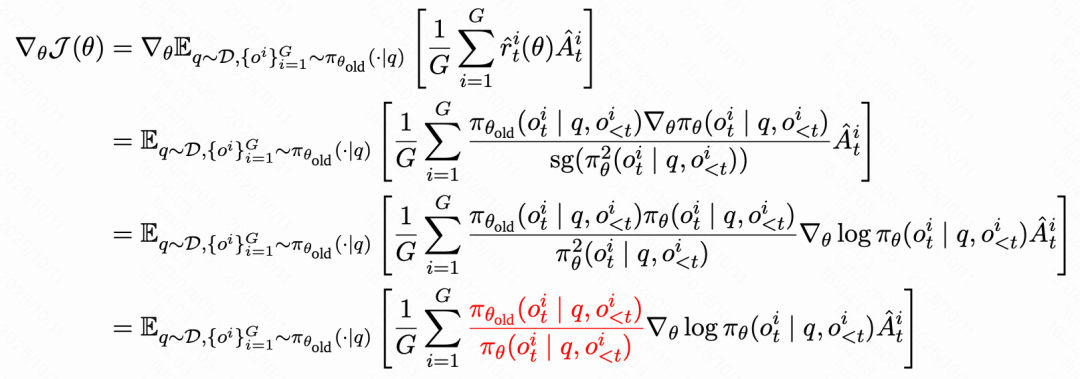
实验结果:更强、更稳
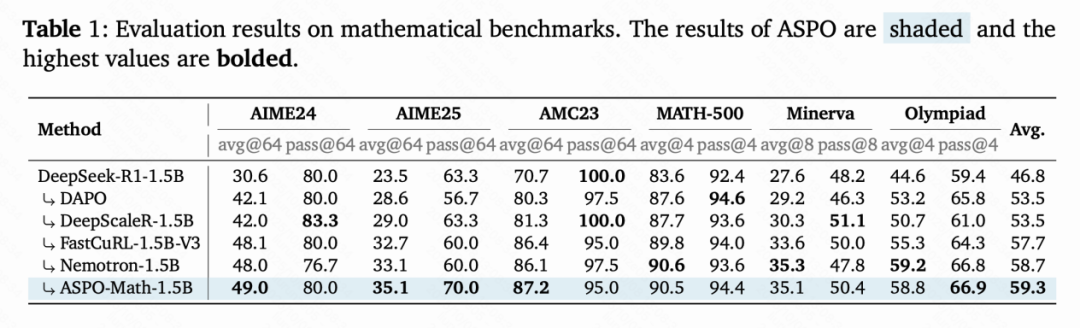
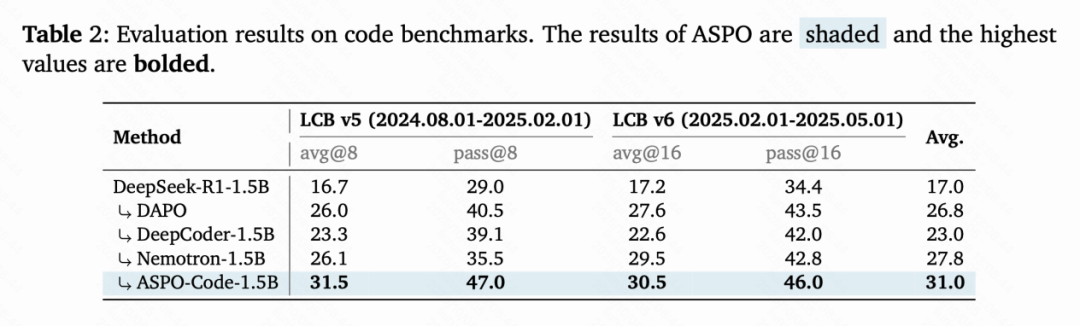
在一系列数学推理(AIME24/25、AMC23、MATH-500、Minerva、Olympiad)和代码生成(LiveCodeBench v5/v6)基准测试中,ASPO展现出显著优势:
- 相比于base model,数学任务平均性能提升 12.5%,代码生成任务平均性能提升 17.0%;
- 训练过程更平滑,无明显熵坍塌;
- 在代码基准LiveCodeBench v5上,ASPO达到了31.5 avg@8 / 47.0 pass@8的成绩,领先主流RL方法(DAPO、DeepScaleR、Nemotron等)。
训练动力学分析
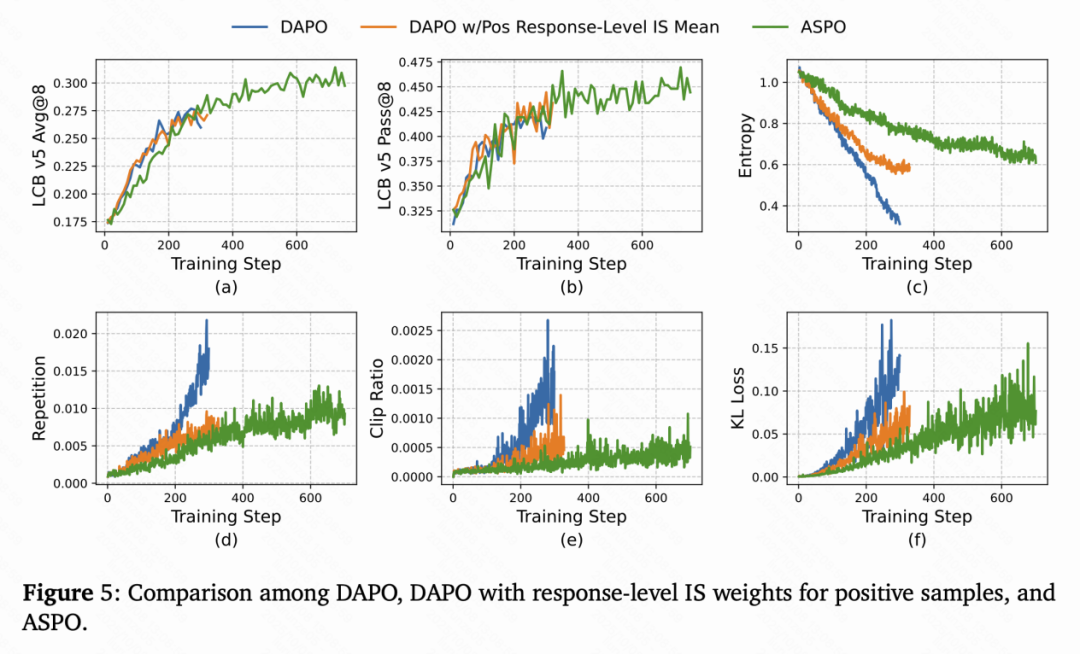
不仅如此,ASPO的训练曲线也展现出前所未有的稳定性:
- 熵下降更平缓——避免了传统算法中的「熵坍缩」问题;
- 重复率更低——输出更加多样;
- KL散度与Clip Ratio稳定;
- 训练过程无明显震荡,表现出典型的「健康收敛」特征。
论文链接:https://arxiv.org/abs/2510.06062GitHub:https://github.com/wizard-III/Archer2.0HuggingFace:https://huggingface.co/collections/Fate-Zero/archer20-68b945c878768a27941fd7b6


