音频

亚马逊 SageMaker已部署 Mistral AI 的 Voxtral 模型
近日,Mistral AI 推出了其 Voxtral 模型,旨在结合文本和音频处理功能,为多种应用场景提供支持。 Voxtral 系列包括两种不同的模型:Voxtral-Mini-3B-2507和 Voxtral-Small-24B-2507,前者为一个优化过的3亿参数模型,适合快速音频转录和基础的多模态理解,而后者则拥有240亿参数,支持更复杂的音频文本智能和多语言处理,非常适合企业级应用。 这两个模型均支持长达30至40分钟的音频上下文,具有自动语言检测功能,并可以处理多达32,000个标记。
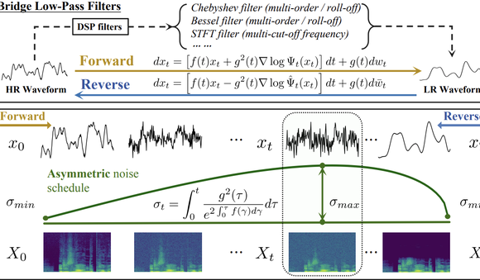
清华大学生数科技:从波形到隐空间,AudioLBM引领音频超分新范式
音频超分辨率(Audio Super-Resolution, Audio SR),即从低采样率音频恢复出高采样率版本,是提升语音清晰度、音乐细节与沉浸式音频体验的关键技术。 无论是在老旧录音修复、语音通信增强,还是音乐制作与多模态生成中,高分辨率音频都能显著提升听感与表现力。 然而,由于高频细节在低采样率信号中被严重损失,这一任务一直是音频生成领域的核心挑战。

6秒造一个「视频博主」,Pika让一切图片开口说话
制作一个视频需要几步? 可以简单概括为:拍摄 配音 剪辑。 还记得 veo3 发布时引起的轰动吗?
腾讯混元开源语音数字人模型HunyuanVideo-Avatar:图+音频,让图中的主角说话唱。
腾讯发布了一款创新技术 ——HunyuanVideo-Avatar 语音数字人模型,并将其开源。 这一技术能够仅凭一张图片和一段音频,生成自然、真实的数字人说话或唱歌视频,标志着短视频创作进入了全新阶段。 HunyuanVideo-Avatar 模型的核心功能在于其智能理解能力。

全新音频问答模型 Omni-R1:利用文本驱动的强化学习和自动生成的数据推进音频问答
最近,一项来自 MIT CSAIL、哥廷根大学、IBM 研究所等机构的研究团队提出了一个名为 Omni-R1的全新音频问答模型。 该模型在 Qwen2.5-Omni 的基础上,通过一种名为 GRPO(Group Relative Policy Optimization)的强化学习方法进行优化,显示出在音频问答任务中的出色表现。 Omni-R1在著名的 MMAU 基准测试中创造了新的最先进成绩,涵盖了声音、语音和音乐等多个音频类别。

Stability AI与Arm推出手机级音频生成AI:7秒内创建11秒立体声
Stability AI和Arm联合发布了一款名为"稳定音频开放小型"(Stable Audio Open Small)的紧凑型文本转音频模型,该模型能够在约7秒内生成长达11秒的高质量立体声音频片段,且经过优化可在智能手机等移动设备上运行。 这一突破基于加州大学伯克利分校研究人员开发的"对抗相对对比"(Adversarial Relativistic-Contrastive,ARC)技术。 该模型在高端硬件如Nvidia H100GPU上的表现更为惊人,能够在仅75毫秒内完成44kHz立体声音频的生成,实现了近乎实时的音频合成能力。

国产MiniMax语音模型横扫国际舞台,迈入个性化语音新时代
在人工智能领域的快速发展中,国产大模型的进步速度让人惊叹。 早在今年初,DeepSeek-R1以超低成本获得了超越 OpenAI 的表现,令人重新审视国外大模型的垄断地位。 如今,MiniMax 再次带来了重磅消息:其全新一代文本转语音(TTS)模型 “Speech-02” 在国际权威的语音评测榜单 Artificial Analysis 上强势登顶,击败了 OpenAI 和 ElevenLabs 等行业巨头。

Stability AI开源341M超轻量文字转语音模型,手机本地跑,音频生成仅需8秒!
近日,Stability AI携手芯片巨头Arm,正式开源了一款轻量级文字转音频模型——Stable Audio Open Small。 这款仅有3.41亿参数的模型,专为Arm CPU优化,能够在智能手机等移动设备上本地运行,生成高质量音频样本仅需不到8秒。 AIbase深入解析这一技术突破,探索其对音频创作和移动AI生态的深远影响。

SDS 技术首次用于音频:英伟达携手 MIT 推 Audio-SDS,参数化控制 AI 音效生成
SDS 技术广泛应用于文本生成 3D 图像和图像编辑中,英伟达融合该技术推出 Audio-SDS,结合预训练模型的生成先验知识,能够直接根据高级文本提示调整 FM 合成参数、冲击音模拟器或分离掩码,将信号处理的清晰可解释性与现代扩散模型的灵活性融为一体。
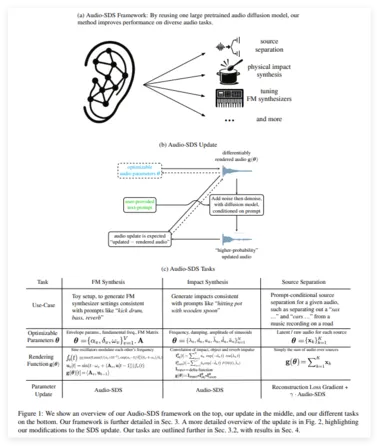
NVIDIA AI推出Audio-SDS,革新音效生成与多任务音频处理
NVIDIA AI研究团队发布了一项突破性技术——Audio-SDS,将Score Distillation Sampling(SDS)技术扩展至文本条件音频扩散模型,显著提升了音效生成、音源分离及多任务音频处理的能力。 这一创新成果已在学术界和工业界引发热议。 技术核心:SDS赋能音频扩散模型Audio-SDS基于NVIDIA此前在图像生成领域广泛应用的SDS技术,通过将其适配到预训练的音频扩散模型,实现了从单一模型到多任务音频处理的跨越。
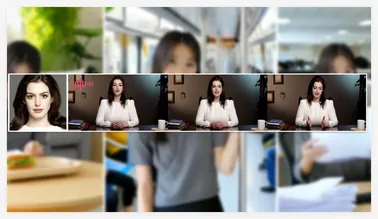
音频同步与视频编辑!腾讯混元开源一致性视频生成工具HunyuanCustom
腾讯开源的一致性视频生成工具 “HunyuanCustom”,该模型不仅能生成生动的视频内容,还能实现音频与口型的同步。 这一创新技术的发布,标志着在深度伪造视频领域的一次重要进步。 一图生成,深度伪造不再遥远HunyuanCustom 的最大亮点在于用户只需提供一张图像,就能创造出深度伪造风格的视频。

谷歌推出iPad专属Gemini应用,赋能多任务处理新体验
近日,谷歌正式发布了一款专为iPadOS设计的全新应用 ——Gemini。 这款应用的推出旨在提升用户在多任务处理和创作方面的效率,充分利用了 iPad 的大屏幕优势。 Gemini 支持分屏功能,让用户能够在同一界面上同时进行多个任务,极大地方便了用户的日常使用。

NotebookLM音频概览新增多语言支持 中文音频表现亮眼
2025 年 4 月 30 日 - AIbase报道:谷歌旗下AI研究助手NotebookLM迎来重大更新,其音频概述(Audio Overviews)功能现已支持超过 50 种语言,其中包括备受期待的中文音频支持。 这一突破性进展得益于谷歌Gemini模型的原生音频处理能力,为全球用户提供了更便捷的多语言学习与内容创作体验。 多语言支持打破语言壁垒NotebookLM的音频概述功能自 2024 年 9 月推出以来,以其将上传文档转化为类似播客的生动讨论而广受好评。

Phi-4-multimodal:图、文、音频统一的多模态大模型架构、训练方法、数据细节
Phi-4-Multimodal 是一种参数高效的多模态模型,通过 LoRA 适配器和模式特定路由器实现文本、视觉和语音/音频的无缝集成。 训练过程包括多阶段优化,确保在不同模式和任务上的性能,数据来源多样,覆盖高质量合成数据。 它的设计体现了小型语言模型在多模态任务上的潜力。

Stability AI与 Arm 合作 推出离线生成音频技术
Stability AI因其Stable Diffusion文本生成图像模型而闻名。 最近,该公司与全球半导体巨头 Arm 展开合作,致力于将生成音频人工智能能力引入移动设备。 这一合作使得Stable Audio Open模型能够完全在 Arm CPU 上运行,用户可以在设备上快速生成音效、音频样本和制作元素,且无需互联网连接。
ElevenLabs 发布 Scribe 语音转文本模型,准确率创新高、英语达 96.7%
ElevenLabs 是一家备受瞩目的人工智能语音克隆与生成初创公司,近日推出了其最新的语音转文本模型 ——Scribe v1。 该模型声称在多种语言中都达到了最高的准确性,用户可以通过其官网进行体验。 根据 ElevenLabs 的基准测试,Scribe 在将口语准确转换为文本方面,超越了谷歌的 Gemini2.0Flash、OpenAI 的 Whisper v3和 Deepgram Nova-3,取得了前所未有的低错误率。
谷歌扩展NotebookLM Plus,个人用户也能享受AI记笔记新体验
谷歌最近宣布,NotebookLM Plus 的付费版本现已向订阅谷歌 One AI Premium 计划的个人用户开放。 这一消息的发布距 NotebookLM Plus 在谷歌云和谷歌工作区首次推出企业版不到两个月,显示出谷歌对个人用户需求的重视。 NotebookLM Plus 于去年12月首次推出,作为一款 AI 驱动的笔记和研究助手,旨在为用户提供更高的使用限制和更多的高级功能。

OpenAI 语音转写工具 Whisper 被曝存在重大缺陷:会凭空生成大段虚假内容
当地时间 27 日,据美联社报道,超过十位软件工程师、开发人员和学术研究人员称,OpenAI 的语音转写工具 Whisper 存在一个重大缺陷:有时会凭空生成大段甚至整句虚假内容。 这些专家指出,这些生成的文本(AI在线注:业内通常称为“AI 幻觉”)可能涉及种族言论、暴力措辞,甚至杜撰的医疗建议。 专家们认为,这一问题尤其令人担忧,因为 Whisper 已被广泛应用于全球多个行业,包括用于翻译和转录访谈内容、生成常见消费科技文本及制作视频字幕。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉