音频

氛围感拉满:微软新专利探索 Copilot AI 应用,匹配视频等生成音乐
科技媒体 Windows Report 昨日(10 月 4 日)发布博文,报道称微软公司获得了一项新的专利,构想 Copilot 在未来能辅助用户创建和视频、文本、PowerPoint 等匹配的音乐或者背景音乐。AI在线注:微软该专利名为《Artificial intelligence model for composing audio scores》,主要探讨了基于输入内容,来创建音乐的方法。该专利主要概述了以下步骤:收集数据:收集大量的训练数据,这些数据包括许多包含视频和音频组件的视听数据集。分析提取:分析数据

阿里通义千问开源 Qwen2-Audio 7B 语音交互大模型:自由互动,无需输入文本
感谢阿里通义千问开源 Qwen2-Audio 系列的两个模型 Qwen2-Audio-7B 和 Qwen2-Audio-7B-Instruct。作为一个大规模音频语言模型,Qwen2-Audio 能够接受各种音频信号输入,并根据语音指令执行音频分析或直接响应文本,有两种不同的音频交互模式:语音聊天:用户可以自由地与 Qwen2-Audio 进行语音互动,而无需文本输入音频分析:用户可以在互动过程中提供音频和文本指令对音频进行分析官方在一系列基准数据集上进行了测试,Qwen2-Audio 超越了先前的最佳模型。▲ Q

AI 根据声音内容帮照片“对口型”,蚂蚁集团开源 EchoMimic 项目
蚂蚁集团 10 日开源了名为 EchoMimic 的新项目,其能够通过人像面部特征和音频来帮人物“对口型”,结合面部标志点和音频内容生成较为稳定、自然的视频。该项目具备较高的稳定性和自然度,通过融合音频和面部标志点(面部关键特征和结构,通常位于眼、鼻、嘴等位置)的特征,可生成更符合真实面部运动和表情变化的视频。其支持单独使用音频或面部标志点生成肖像视频,也支持将音频和人像照片相结合做出“对口型”一般的效果。据悉,其支持多语言(包含中文普通话、英语)及多风格,也可应对唱歌等场景。 AI在线附相关链接:项目地址: G

比尔・盖茨展望“AI 智能体”:能提供心理治疗服务,还能当女友
播客节目 Next Big Idea Club 上周末发布了对微软创始人比尔・盖茨的采访,盖茨谈到了人工智能、超级智能等话题。主持人 Rufus Griscom 询问了比尔盖茨对人工智能未来发展的看法。“1980 年,你曾有过灵光一现的一瞬:当时你宣布每家每户、每个桌子上都将有一台计算机。你认为 AI 会有怎样的发展?你认为我们的每个耳朵里都会有一个‘AI 顾问(AI advisor)’吗?”盖茨回答道,“AI 顾问”的硬件外形并不重要。例如耳机既能增强音频、又能消除音频,还能使音频更清晰,这是一个非常重要的硬件形
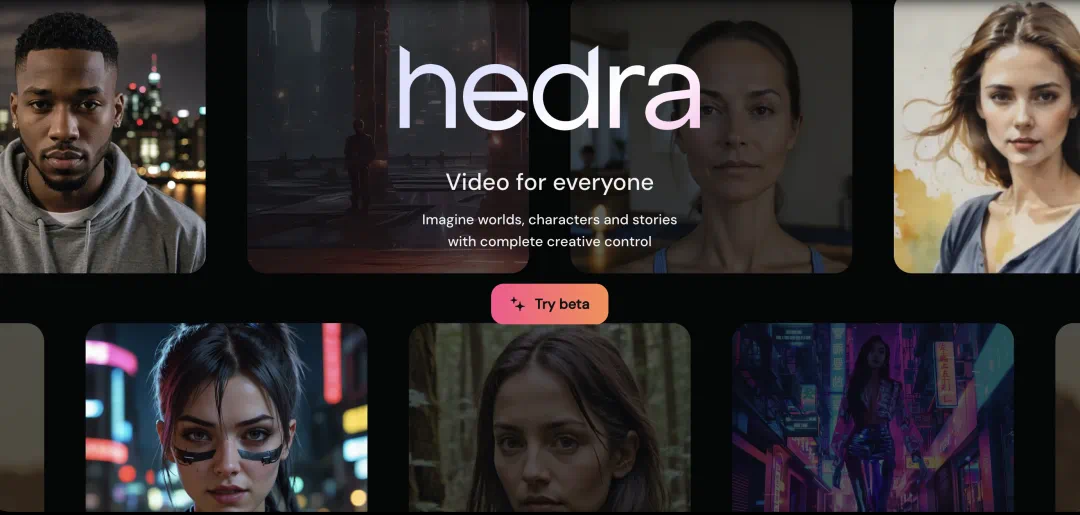
吊打阿里EMO?让马斯克唱Rap、奥特曼说脱口秀的AI神器出圈,人人免费可用
机器之能报道编辑:杨文以大模型、AIGC为代表的人工智能浪潮已经在悄然改变着我们生活及工作方式,但绝大部分人依然不知道该如何使用。因此,我们推出了「AI在用」专栏,通过直观、有趣且简洁的人工智能使用案例,来具体介绍AI使用方法,并激发大家思考。 我们也欢迎读者投稿亲自实践的创新型用例。最近,AI 圈刮起一股「让照片开口唱歌」的风潮。例如,让霉霉唱碧昂丝《Halo》的 Hallo、斯坦福创业团队的 Proteus、以及之前阿里出品的 EMO。就在昨天,又有一家名为 Hedra 的公司前来踢馆,推出了基础模型 ——

Stable Audio Open 开源 AI 模型发布:48.6 万个样本训练,可创建 47 秒短音频 / 音效等
Stability AI 立足 Stable Diffusion 文生图模型,进一步向音频领域拓展,推出了 Stable Audio Open,可以基于用户输入的提示词,生成高质量音频样本。Stable Audio Open 最长可以创建 47 秒的音乐,非常适合鼓点、乐器旋律、环境音和拟声音效,该开源模型基于 transforms 扩散模型(DiT),在自动编码器的潜在空间中操作,提高生成音频的质量和多样性。Stable Audio Open 目前已经开源,IT之家附上相关链接,感兴趣的用户可以在 Hugging

Stable Audio 2.0 发布:生成最长 3 分钟音频,能帮音乐家补全创意作品
Stability AI 近日发布新闻稿,宣布推出 Stable Audio2.0,可以基于用户输入的提示词,生成最长 3 分钟的完整音轨。Stable Audio 2.0 在此前 1.0 版本基础上,进一步为音频生成扩展了前奏、副歌、收尾和立体声效果等内容,最长可以生成 3 分钟的音频内容。Stable Audio 2.0 扩充了生成功能之外,还提供了音频生成音频功能,基于用户上传的一小段音频内容,扩展生成、补充相关的音频内容。IT之家附上演示视频如下: 例如音乐家如果在创作某段音乐的时候“卡壳”了,可以上传某段
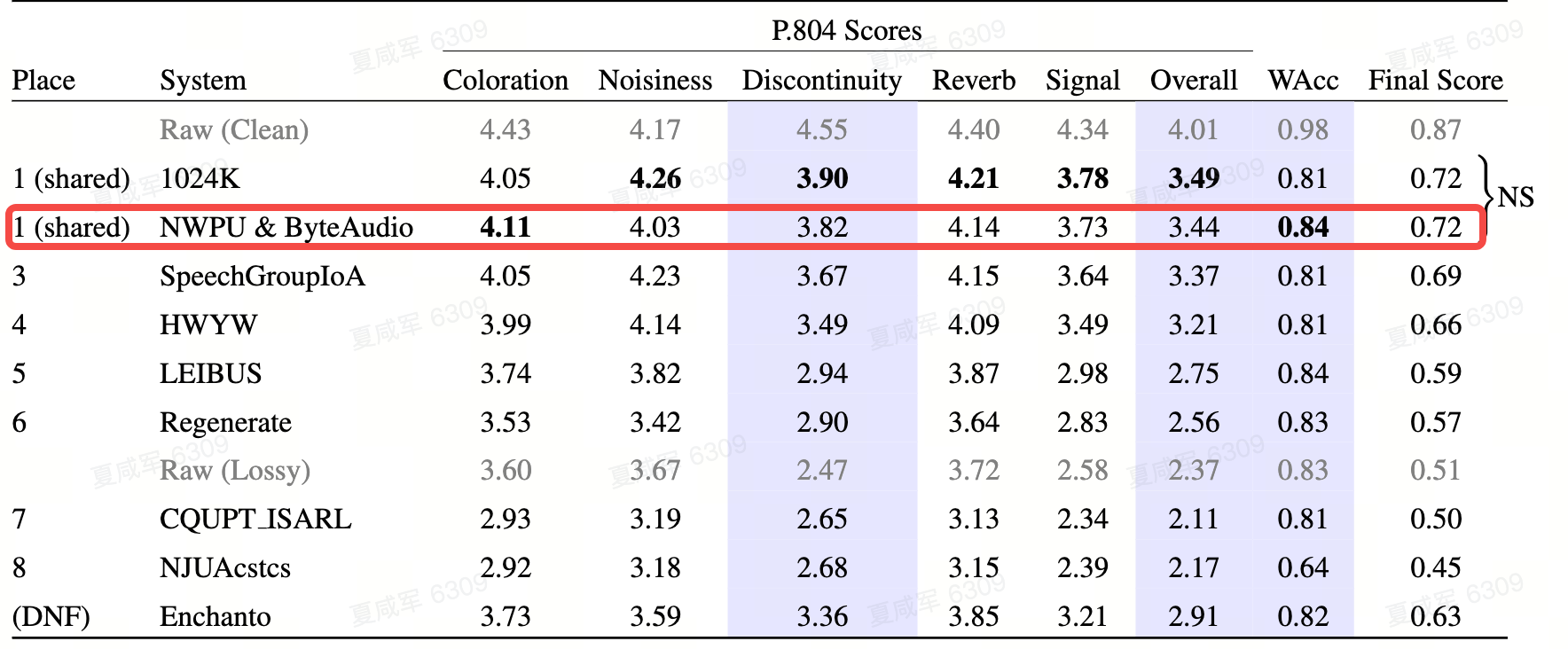
ICASSP 2024|字节跳动流媒体音频团队创新方案解决丢包补偿、通用音质修复问题
在本届ICASSP 2024 各类音频国际挑战赛中,字节跳动流媒体音频团队联合西北工业大学音频语音与语言处理研究实验室,在丢包补偿(Packet Loss Concealment, PLC)与音质修复(Speech Signal Improvement, SSI)两个挑战赛道中,多项指标上表现优秀,分别取得第一和第二的成绩,达到国际领先水平。ICASSP峰会上的音频挑战赛由国际音频顶级会议 ICASSP 和微软联合发起,旨在激发各研究构在音频效果与音质提升上的研究,自第一届举办以来就吸引了亚马逊、腾讯、阿里巴巴、百
试了试Meta的最新语音生成器,逼真得有点毛骨悚然
机器之能报道编辑:吴昕这段《小红帽》故事中的所有音频都是 AI 生成的,你能听出来吗?机器之能报道编辑:吴昕这段《小红帽》故事中的所有音频都是 AI 生成的,你能听出来吗?试听地址: Audiobox Maker,你可以在 Meta 刚刚发布的一个新的交互式网站 audiobox.metademolab 上找到它。有了它,仅用几分钟的时间,机器之心也随意生成了关于五月天假唱热搜的对话:试听地址: Audiobox Maker ,即使是小白用户也可以设计、生成不同人物(比如小红帽、大灰狼和外婆)的声音文件,同时添加不

Meta开源文本生成音乐大模型,我们用《七里香》歌词试了下
年初,谷歌推出了音乐生成大模型 MusicLM,效果非常不错。有人称这比大火的 ChatGPT 还重要,几乎解决了音乐生成问题。近日,Meta 也推出了自己的文本音乐生成模型 MusicGen,并且非商业用途免费使用。
腾讯QQ黑科技亮相2021谷歌开发者大会官网,基于TFlite部署AI语音降噪
当6亿用户习惯每天通过QQ发送语音和进行视频通话,或者在群里与网友语音接龙完成一场Pia戏,又或是与好友一起派对语音答题的时候,大家可曾想过,在不同场景下始终清晰、流畅的QQ音视频体验背后,到底是什么黑科技在支撑这些场景中“声”与“话”的美好?今年11月16日召开的谷歌2021开发者大会期间,大会官网更新了一则案例——《TensorFlow助力:AI语音降噪打造QQ音视频通话新体验》,作者正是QQ音视频通话技术团队。作为谷歌TensorFlow的优秀应用案例,腾讯QQ团队在该文中详细揭秘了语音增强技术在QQ音视频功

引入多感官数据学习,华人学者Ruohan Gao摘得2021 UT-Austin最佳博士论文奖
UT-Austin 本年度的最佳博士论文奖获得者 Ruohan Gao,目前是斯坦福大学的博士后研究员。
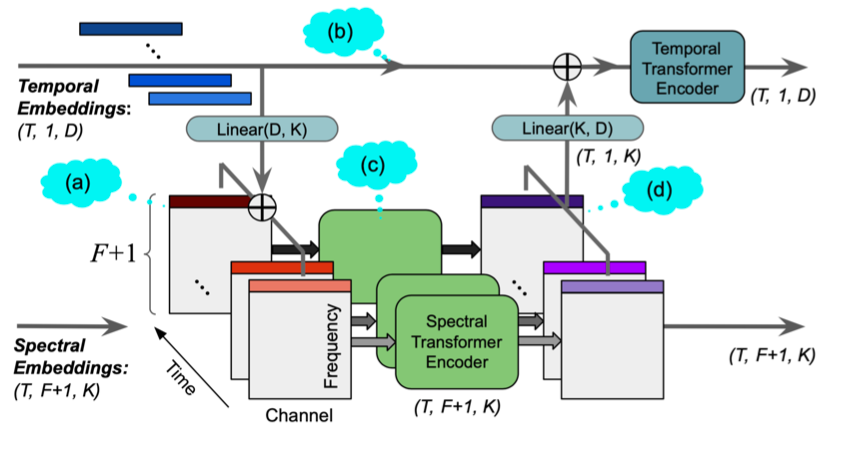
抖音「神曲」那么多,字节跳动是如何玩转亿级曲库的?
在今年的音乐科技顶会 ISMIR 2021(International Society for Music Information Retrieval)上,字节跳动海外技术团队有 7 篇论文入选,涵盖了音乐分类、音乐标签、音源分离、音乐结构分析等多个技术方向。如今抖音已经成为音乐宣发的一个重要渠道。一支支音乐先在抖音上以短视频 BGM 火起来,再扩散到各大音乐平台上。抖音神曲甚至成了很多音乐平台的一个重要分类。有人说神曲能火是因为歌词和旋律简单,听得多了就印在脑子里。但是对一个有着海量用户、复杂多样内容场景的短视频
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉