作为一个大规模音频语言模型,Qwen2-Audio 能够接受各种音频信号输入,并根据语音指令执行音频分析或直接响应文本,有两种不同的音频交互模式:
语音聊天:用户可以自由地与 Qwen2-Audio 进行语音互动,而无需文本输入
音频分析:用户可以在互动过程中提供音频和文本指令对音频进行分析
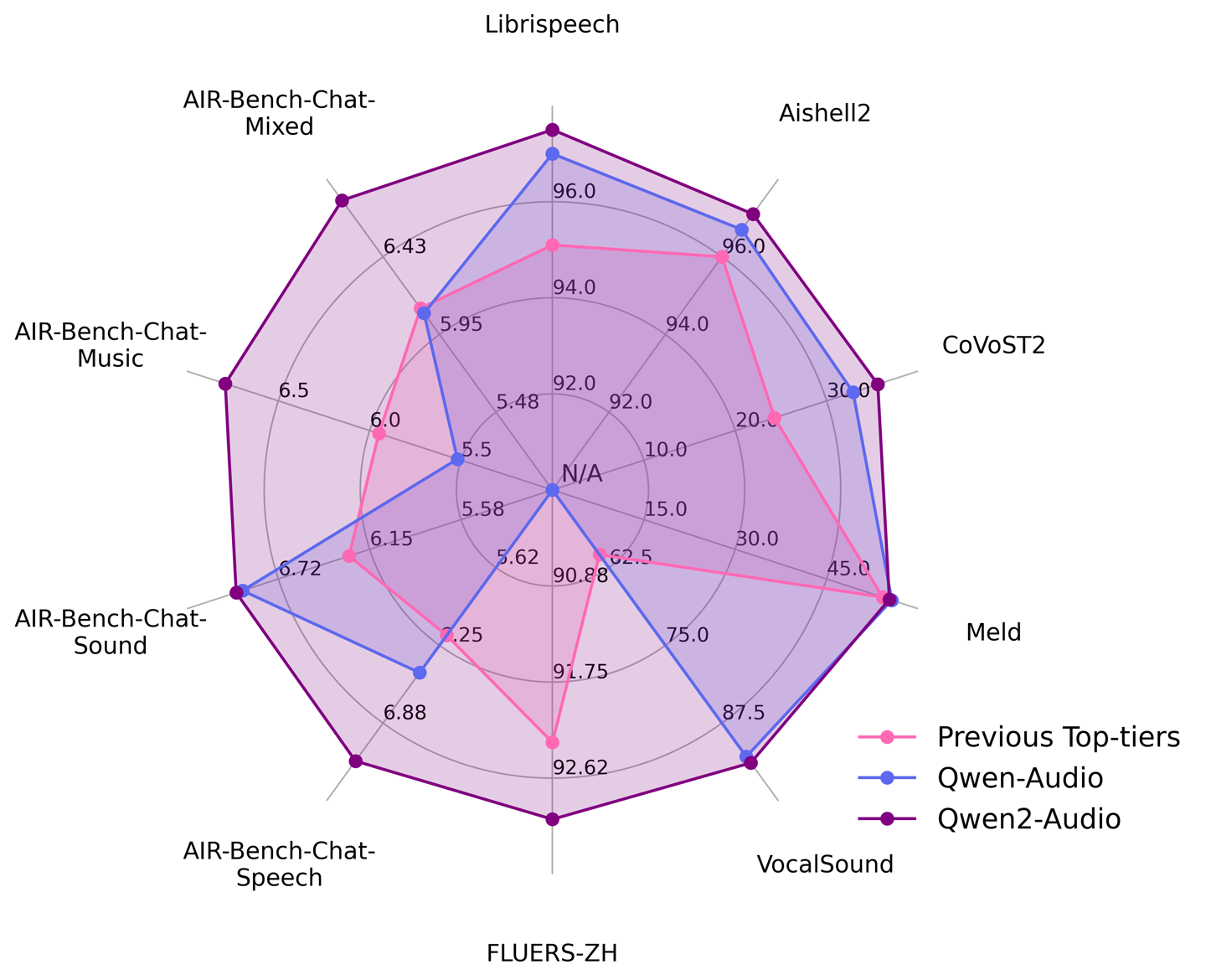
官方在一系列基准数据集上进行了测试,Qwen2-Audio 超越了先前的最佳模型。
AI在线附相关链接如下:
试用链接:https://huggingface.co/spaces/Qwen/Qwen2-Audio-Instruct-Demo
论文地址:https://arxiv.org/abs/2407.10759
评估标准:https://github.com/OFA-Sys/AIR-Bench
开源代码:https://github.com/QwenLM/Qwen2-Audio