Audio

Stability AI开源341M超轻量文字转语音模型,手机本地跑,音频生成仅需8秒!
近日,Stability AI携手芯片巨头Arm,正式开源了一款轻量级文字转音频模型——Stable Audio Open Small。 这款仅有3.41亿参数的模型,专为Arm CPU优化,能够在智能手机等移动设备上本地运行,生成高质量音频样本仅需不到8秒。 AIbase深入解析这一技术突破,探索其对音频创作和移动AI生态的深远影响。
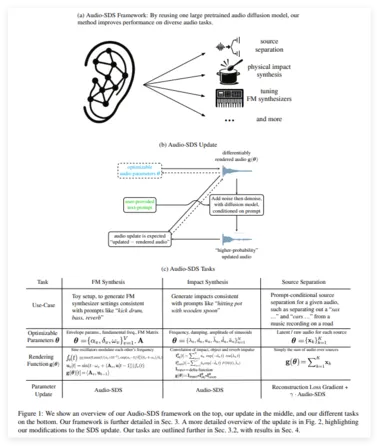
NVIDIA AI推出Audio-SDS,革新音效生成与多任务音频处理
NVIDIA AI研究团队发布了一项突破性技术——Audio-SDS,将Score Distillation Sampling(SDS)技术扩展至文本条件音频扩散模型,显著提升了音效生成、音源分离及多任务音频处理的能力。 这一创新成果已在学术界和工业界引发热议。 技术核心:SDS赋能音频扩散模型Audio-SDS基于NVIDIA此前在图像生成领域广泛应用的SDS技术,通过将其适配到预训练的音频扩散模型,实现了从单一模型到多任务音频处理的跨越。

高盛支持的初创公司Splice收购英国音响工作室,押注 AI 音乐创作
近日,知名音乐样本公司 Splice 宣布,将收购位于伦敦的音响工作室 Spitfire Audio。 这一交易标志着 Splice 在音乐创作领域的一次重要布局,尤其是在人工智能音乐制作日益兴起的背景下。 Spitfire Audio 以其丰富的管弦乐声音库而闻名,这次收购将为 Splice 提供更多样的音乐素材,进一步丰富其产品线。

阿里通义千问开源 Qwen2-Audio 7B 语音交互大模型:自由互动,无需输入文本
感谢阿里通义千问开源 Qwen2-Audio 系列的两个模型 Qwen2-Audio-7B 和 Qwen2-Audio-7B-Instruct。作为一个大规模音频语言模型,Qwen2-Audio 能够接受各种音频信号输入,并根据语音指令执行音频分析或直接响应文本,有两种不同的音频交互模式:语音聊天:用户可以自由地与 Qwen2-Audio 进行语音互动,而无需文本输入音频分析:用户可以在互动过程中提供音频和文本指令对音频进行分析官方在一系列基准数据集上进行了测试,Qwen2-Audio 超越了先前的最佳模型。▲ Q

Stable Audio Open 开源 AI 模型发布:48.6 万个样本训练,可创建 47 秒短音频 / 音效等
Stability AI 立足 Stable Diffusion 文生图模型,进一步向音频领域拓展,推出了 Stable Audio Open,可以基于用户输入的提示词,生成高质量音频样本。Stable Audio Open 最长可以创建 47 秒的音乐,非常适合鼓点、乐器旋律、环境音和拟声音效,该开源模型基于 transforms 扩散模型(DiT),在自动编码器的潜在空间中操作,提高生成音频的质量和多样性。Stable Audio Open 目前已经开源,IT之家附上相关链接,感兴趣的用户可以在 Hugging

Stable Audio 2.0 发布:生成最长 3 分钟音频,能帮音乐家补全创意作品
Stability AI 近日发布新闻稿,宣布推出 Stable Audio2.0,可以基于用户输入的提示词,生成最长 3 分钟的完整音轨。Stable Audio 2.0 在此前 1.0 版本基础上,进一步为音频生成扩展了前奏、副歌、收尾和立体声效果等内容,最长可以生成 3 分钟的音频内容。Stable Audio 2.0 扩充了生成功能之外,还提供了音频生成音频功能,基于用户上传的一小段音频内容,扩展生成、补充相关的音频内容。IT之家附上演示视频如下: 例如音乐家如果在创作某段音乐的时候“卡壳”了,可以上传某段
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉