最近,一项来自 MIT CSAIL、哥廷根大学、IBM 研究所等机构的研究团队提出了一个名为 Omni-R1的全新音频问答模型。该模型在 Qwen2.5-Omni 的基础上,通过一种名为 GRPO(Group Relative Policy Optimization)的强化学习方法进行优化,显示出在音频问答任务中的出色表现。
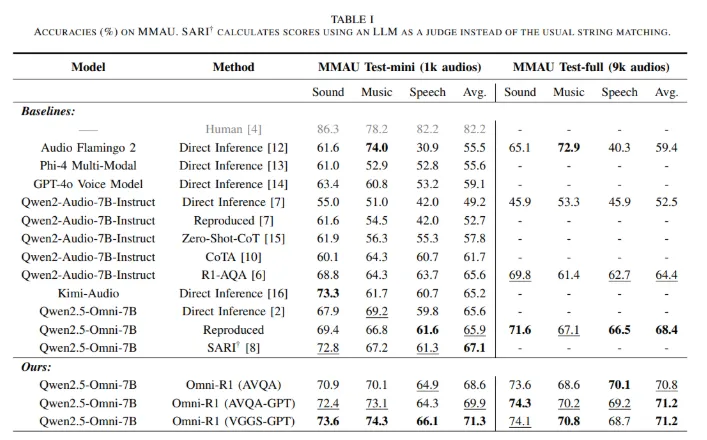
Omni-R1在著名的 MMAU 基准测试中创造了新的最先进成绩,涵盖了声音、语音和音乐等多个音频类别。研究团队指出,尽管模型的训练涉及音频数据,但其性能提升的主要原因竟然是文本推理能力的增强。这一发现让人惊讶,因为即使仅使用文本数据进行微调,模型的表现也取得了显著的提升。
为此,研究人员利用 ChatGPT 生成了大量音频问答数据,创建了两个新的数据集:AVQA-GPT 和 VGGS-GPT。这两个数据集分别包含4万和18.2万条音频数据,进一步提升了 Omni-R1的准确性。在训练过程中,Omni-R1的表现超过了以往的基线模型,包括 SARI,平均得分达到71.3%。研究表明,尽管使用音频进行微调稍微优于仅使用文本,但后者的贡献同样不可忽视。
GRPO 方法的一个关键优点是其内存效率,使得在48GB 的 GPU 上能够有效运行。该方法通过比较分组输出,基于答案的正确性来进行奖励,而无需使用复杂的价值函数。研究人员通过扩展 Qwen-2Audio 的音频描述来增加训练数据,这种策略使得模型在多模态任务上更具竞争力。
Omni-R1不仅在音频问答领域设立了新的标杆,还展示了文本推理在音频模型性能中的重要性。未来,研究团队承诺将发布所有相关资源,以便更多研究人员和开发者能够利用这一成果。
论文:https://arxiv.org/abs/2505.09439
划重点:
🔍 Omni-R1是基于 Qwen2.5-Omni 模型,通过 GRPO 强化学习方法优化而成的音频问答模型。
📈 该模型在 MMAU 基准测试中取得了新高度,文本推理能力的提升被认为是主要原因。
🛠️ 研究团队通过 ChatGPT 生成新数据集,极大地提升了模型的训练效果和准确性。