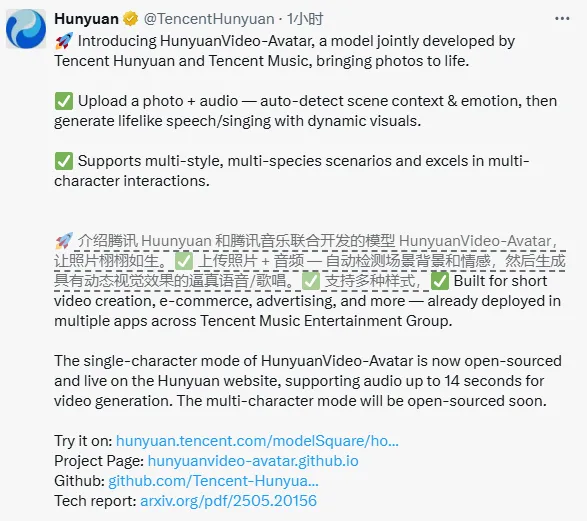
腾讯发布了一款创新技术 ——HunyuanVideo-Avatar 语音数字人模型,并将其开源。这一技术能够仅凭一张图片和一段音频,生成自然、真实的数字人说话或唱歌视频,标志着短视频创作进入了全新阶段。
HunyuanVideo-Avatar 模型的核心功能在于其智能理解能力。用户只需上传一张人物图像和相应的音频,模型便能自动分析音频中的情感和人物所处环境。例如,如果上传一张在海滩上弹吉他的女性的照片,并搭配抒情音乐,模型将自动生成一段该女性在弹唱的动态视频,展现自然的表情、唇形同步及全身动作。
适用广泛的应用场景
这一技术的应用场景非常广泛,涵盖短视频创作、电商广告等多种领域。HunyuanVideo-Avatar 能够生成各种场景下的对话、表演等视频片段,极大地降低了视频制作的时间和成本。无论是快速制作产品介绍视频,还是进行多人互动广告,HunyuanVideo-Avatar 都能提供出色的支持。
业内领先的效果
在技术方面,HunyuanVideo-Avatar 展现了显著的优势。与传统工具相比,HunyuanVideo-Avatar 不仅支持头部驱动,还能实现半身和全身场景的表现,提升视频的真实感和表现力。同时,模型在主体一致性和音画同步方面的表现超越了多种开闭源方案,处于业内顶尖水平。
多样化的风格支持
HunyuanVideo-Avatar 支持多种风格、物种和多人场景,包括赛博朋克、2D 动漫和中国水墨画等。创作者可以轻松上传卡通角色或虚拟形象,生成风格化的动态视频,满足动漫、游戏等领域的创作需求。此外,在多人互动场景中,模型能够精准驱动多个角色,确保各角色的唇形、表情和动作与音频完美同步,实现自然的互动。
这一切的背后是腾讯混元团队与腾讯音乐天琴实验室共同研发的技术创新,包括角色图像注入模块、多模态扩散 Transformer 架构、音频情感模块和面部感知音频适配器等,确保了视频的动态性和角色一致性。
HunyuanVideo-Avatar 的单主体能力已在腾讯混元官网上线,用户可以通过 “模型广场” 体验这一技术。目前支持上传不超过14秒的音频生成视频,未来还将逐步推出更多功能。
体验入口:https://hunyuan.tencent.com/modelSquare/home/play?modelId=126
项目主页:https://hunyuanvideo-avatar.github.io
Github:https://github.com/Tencent-Hunyuan/HunyuanVideo-Avatar


