科技媒体 marktechpost 昨日(5 月 12 日)发布博文,报道称英伟达携手麻省理工学院(MIT),推出了 Audio-SDS,一种基于文本条件的音频扩散模型扩展技术。
音频扩散模型近年来在生成高质量音频方面表现卓越,但其局限在于难以优化明确且可解释的参数。
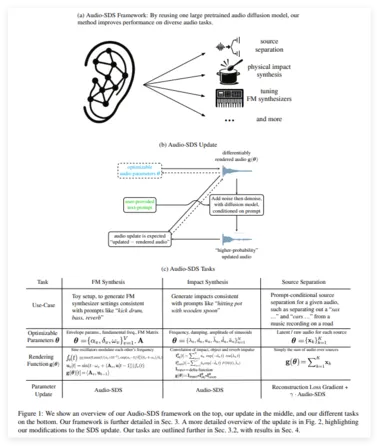
英伟达和 MIT 的科研团队首次将 Score Distillation Sampling(SDS)方法应用于音频领域,结合预训练模型的生成能力与参数化音频表示,无需大规模特定数据集,可应用于 FM 合成器参数校准、物理冲击音合成和音源分离三大任务。
SDS 技术广泛应用于文本生成 3D 图像和图像编辑中,英伟达融合该技术推出 Audio-SDS,结合预训练模型的生成先验知识,能够直接根据高级文本提示调整 FM 合成参数、冲击音模拟器或分离掩码。

研究团队通过基于解码器的 SDS、多步去噪和多尺度频谱图等方法,实验结果表明,Audio-SDS 在主观听觉测试和客观指标(如 CLAP 分数、信号失真比 SDR)上均表现出色。
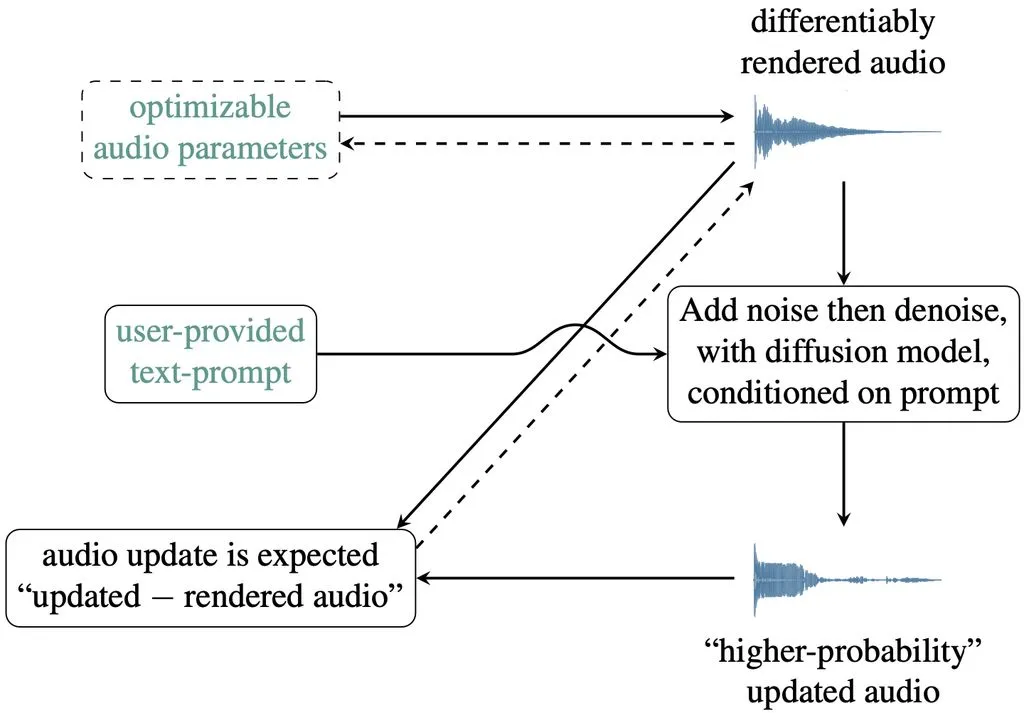
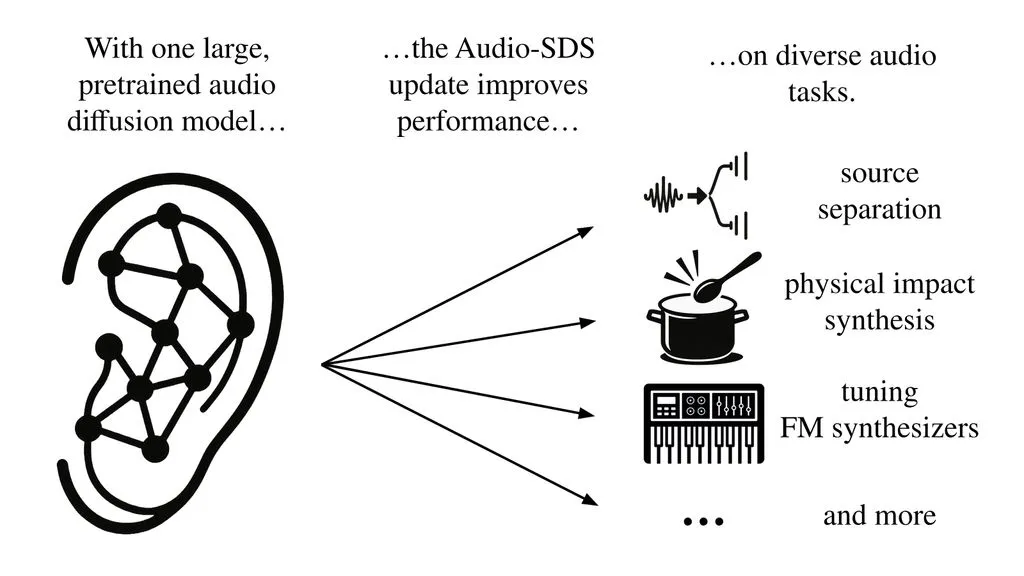
Audio-SDS 的创新在于,它用单一预训练模型支持多种音频任务,消除了对大规模领域特定数据集的依赖。尽管如此,研究团队也指出,模型覆盖范围、潜在编码伪影和优化敏感性等问题仍需解决。
AI在线附上参考地址
Score Distillation Sampling for Audio: Source Separation, Synthesis, and Beyond
Audio-SDS Overview