推理

微软发布 Phi-4 系列小语言 AI 推理模型,AIME 2025 跑分超满血版 Deepseek R1
微软昨日(4 月 30 日)发布 Phi-4-reasoning 系列推理模型,通过监督微调 Phi-4,并利用 o3-mini 生成的高质量“可教导”提示数据集训练,专为复杂推理任务设计。
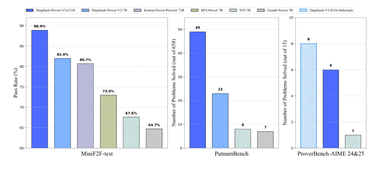
数学推理新标杆!DeepSeek-Prover-V2 实现数学证明的飞跃
在人工智能领域,最近一项重磅技术发布引发广泛关注 ——DeepSeek-Prover-V2。 这一模型不仅在推理性能上取得了显著提升,还被誉为通向人工通用智能(AGI)的关键一步。 DeepSeek-Prover-V2在推理能力和训练效率上都进行了革命性的创新,给数学推理研究带来了新的希望。

中国开源大模型新成员:小米推理大模型首秀!
编辑 | 云昭进入2025以来,中国大模型的开源力量一骑绝尘,甚至盖过了Llama的势头。 今天,中国开源大模型,迎来新成员! 4月30日,赶在五一前,一条“为Reasoning而生”的Xiaomi Mimo开源模型的发布消息不胫而走,发布渠道是小米6天前新注册的公众号Xiaomi Mimo。

70亿参数干翻320亿?小米扔出“核弹级”AI MiMo 你的“破电脑”也能跑赢奥数题和复杂代码!
小米正式在Hugging Face平台发布其首个专为推理(Reasoning)设计的开源大模型——MiMo-7B。 据AIbase了解,MiMo-7B通过从预训练到后训练的强化学习(RL)优化,展现了在数学、代码和通用推理任务上的卓越性能,超越了多个32亿参数以上的基线模型。 社交平台上的热烈讨论凸显了其对AI社区的深远影响,相关细节已通过Hugging Face(huggingface.co/xiaomi/MiMo-7B)与小米官网(xiaomi.com)公开。
小米首个推理大模型开源Xiaomi MiMo,70 亿参数
全球知名科技公司小米正式发布其首个针对推理(Reasoning)而生的大型开源模型 ——Xiaomi MiMo。 该模型旨在解决当前预训练模型在推理能力上的瓶颈,探索如何更有效地激发模型的推理潜能。 MiMo 的推出标志着小米在人工智能领域的一次重要尝试,尤其是在数学推理和代码竞赛方面,表现出色。
小米首个推理大模型Xiaomi MiMo开源
2025年4月30日,小米公司宣布开源其首个为推理(Reasoning)而生的大模型「Xiaomi MiMo」。 这一模型的发布标志着小米在人工智能领域迈出了重要的一步,特别是在推理能力的提升上取得了显著进展。 「Xiaomi MiMo」的诞生旨在探索如何激发模型的推理潜能,特别是在预训练增长见瓶颈的情况下。

ICLR 2025|首个动态视觉-文本稀疏化框架来了,计算开销直降50%-75%
本文由华东师范大学和小红书联合完成,共同第一作者是华东师范大学在读硕士、小红书 NLP 团队实习生黄文轩和翟子杰,通讯作者是小红书 NLP 团队负责人曹绍升,以及华东师范大学林绍辉研究员。 多模态大模型(MLLMs)在视觉理解与推理等领域取得了显著成就。 然而,随着解码(decoding)阶段不断生成新的 token,推理过程的计算复杂度和 GPU 显存占用逐渐增加,这导致了多模态大模型推理效率的降低。

Grok 3.5测试版下周上线,专为SuperGrok用户打造,专注火箭发动机与电化学技术解答
xAI宣布Grok3.5测试版将于下周正式推出,首批仅对SuperGrok订阅用户开放。 据AIbase了解,该版本以其在火箭发动机和电化学等领域的精准技术解答能力引发热议,号称“全球首个人工智能能从第一性原理推理,生成网络上不存在的答案”。 社交平台上的讨论显示,Grok3.5的专项技术能力与开放性备受期待,相关细节已通过xAI官网(x.ai)与社交媒体逐步公开。

阿里Qwen3深度解析:新一代开源大语言模型的革新与突破
Qwen3是什么?阿里Qwen3是通义千问系列的最新一代开源大语言模型(LLM),于2025年4月29日正式发布。 作为全球首个支持“混合推理”的模型,Qwen3包含8款不同规模的模型,涵盖稠密模型(如0.6B、4B、32B)和混合专家模型(MoE,如30B-A3B、235B-A22B),采用Apache2.0协议开源,支持免费商用。 其核心目标是提供高性能、低成本的AI解决方案,同时覆盖从边缘设备到企业级服务器的全场景需求。
Ollama 支持全线的 Qwen 3 模型
Ollama官方宣布已全面支持阿里巴巴通义千问最新一代大语言模型系列——Qwen3。 这一重要更新进一步丰富了Ollama的开源模型生态,为开发者、企业及AI爱好者提供了更强大的本地化部署选择,显著提升了在多种场景下的AI应用灵活性与效率。 Qwen3模型:性能与规模并重Qwen3是阿里巴巴通义千问团队推出的最新一代大语言模型,涵盖从0.6亿到2350亿参数的广泛模型规模,包括高效的混合专家(MoE)模型。

北京大学推出新基准评测PHYBench,挑战AI物理推理能力!
最近,北京大学物理学院联合多个院系,推出了一项名为 “PHYBench” 的全新评测基准,旨在检验大模型在物理推理上的真实能力。 该项目由朱华星老师和曹庆宏副院长主导,汇聚了来自物理学院和其他学科的200多名学生,其中不少人曾在全国中学生物理竞赛中获金牌。 PHYBench 设计了500道精心制作的高质量物理题,这些题目涵盖高中物理、大学物理及物理奥林匹克竞赛的各个层面。
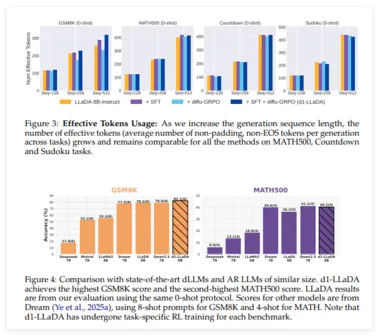
大幅提升 AI 推理速度:UCLA 与 Meta AI 联合推出 d1 框架
在人工智能领域,UCLA 和 Meta AI 的研究人员联合推出了一种名为 d1的新框架,该框架通过强化学习技术显著提升了扩散式大语言模型(dLLMs)的推理能力。 虽然传统的自回归模型如 GPT 受到了广泛关注,但 dLLMs 凭借其独特的优势,若能加强推理能力,将为企业带来新的效率和应用前景。 扩散式语言模型与自回归模型的生成方式截然不同。

上交大等探索键值压缩的边界:MILLION开源框架定义模型量化推理新范式,入选顶会DAC 2025
本篇工作已被电子设计自动化领域顶级会议 DAC 2025 接收,由上海交大计算机学院蒋力教授与刘方鑫助理教授带领的 IMPACT 课题组完成,同时也获得了华为 2012 实验室和上海期智研究院的支持。 第一作者是博士生汪宗武与硕士生许鹏。 在通用人工智能的黎明时刻,大语言模型被越来越多地应用到复杂任务中,虽然展现出了巨大的潜力和价值,但对计算和存储资源也提出了前所未有的挑战。

Qwen3正式确认本周发布,阿里云AI新篇章即将开启
阿里云Qwen团队通过社交平台正式确认,Qwen3系列模型将于本周内发布,标志着其旗舰大语言模型(LLM)与多模态能力的又一次重大升级。 据AIbase了解,Qwen3将推出包括0.6B、4B、8B、30B-A3B在内的多种模型规模,支持高达256K的上下文长度,涵盖推理与非推理任务。 社交平台上的热烈讨论凸显了其全球影响力,相关细节已通过Hugging Face与Qwen官网逐步公开。

字节Seed 团队推出 PHD-Transformer,成功扩展预训练长度,解决 KV 缓存问题!
近日,字节跳动的 Seed 团队在人工智能领域再传佳音,推出了一种新型的 PHD-Transformer(Parallel Hidden Decoding Transformer),这项创新突破了预训练长度的限制,有效解决了推理过程中的 KV 缓存膨胀问题。 随着大型推理模型的迅速发展,研究人员在后训练阶段尝试通过强化学习方法来生成更长的推理链,并在复杂的推理任务上取得了显著成果。 受到启发,字节 Seed 团队决定探索在预训练阶段进行长度扩展的可能性。

基于奖励驱动和自组织演化机制,全新框架ReSo重塑复杂推理任务中的智能协作
本文由上海人工智能实验室,悉尼大学,牛津大学联合完成。 第一作者周恒为上海 ailab 实习生和 Independent Researcher 耿鹤嘉。 通讯作者为上海人工智能实验室青年科学家白磊和牛津大学访问学者,悉尼大学博士生尹榛菲,团队其他成员还有 ailab 实习生薛翔元。

7B超越GPT!1/20数据,无需知识蒸馏,马里兰等推出全新视觉推理方法
在大模型时代,视觉语言模型(Vision-Language Models, VLMs)正在从感知走向推理。 在诸如图像问答、图表理解、科学推理等任务中,VLM不再只需要「看见」和「描述」,而是要能「看懂」和「想清楚」。 然而,当前主流的推理能力提升方法普遍存在两个问题:1.

RL真让大模型更会推理?清华新研究:其能力边界或仍被基座「锁死」
近年来,RLVR(可验证奖励的强化学习)训练大模型在数学、代码等各项任务中表现惊艳,大模型的推理能力快速提升,强化学习因而被视为重要的推手。 然而,其中直指核心的重要问题却悬而未决:强化学习真的能让大模型获得超越基础模型的新推理能力吗? 清华大学LeapLab团队联合上海交通大学开展的最新实证研究,通过实验现象揭示了一个值得关注的问题:当前的 RLVR 方法似乎尚未突破基座模型的能力上限。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉