推理

英伟达推出新型模型 Cosmos-Reason1 ,让 AI 更好理解物理世界
近日,英伟达发布了其最新的 Cosmos-Reason1系列模型,旨在提升人工智能在物理常识和具身推理方面的能力。 随着人工智能在语言处理、数学及代码生成等领域取得显著进展,如何将这些能力扩展到物理环境中成为了一大挑战。 物理 AI(Physical AI)不同于传统的人工智能,它依赖于视频等感官输入,并结合现实物理法则来生成反应。

ChatGPT转型计划曝光!不再只是回答问题,而是通过穿插使用工具变身行动助手
AI Agent今天是初级工程师,6个月后是高级工程师,一年后是架构师。 这是OpenAI CPO Kevin Weil在接受最新访谈时提出的构想。 他表示,ChatGPT将从回答问题转变为为用户做事。
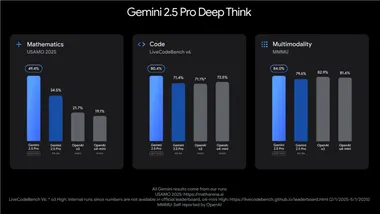
谷歌Gemini 2.5 Pro Deep Think发布:并行推理重塑AI复杂问题解决
在2025年5月20日的Google I/O开发者大会上,谷歌DeepMind正式推出了Gemini2.5Pro Deep Think模式,这一实验性增强推理模式为AI处理复杂任务树立了新标杆。 Deep Think模式通过并行推理技术,使Gemini2.5Pro在数学、编码和多模态推理等领域的表现达到行业领先水平。 并行推理技术,显著提升复杂任务表现Deep Think模式采用前沿的并行推理技术,允许模型在生成响应前探索多个假设路径,从而提升答案的准确性和深度。

CoT推理大溃败?哈佛华人揭秘:LLM一思考,立刻就「失智」
DeepSeek-R1火了,推理模型火了,思维链(Chain-of-Thought,CoT)火了! 模型很聪明,问题是:它还听你的话吗? 思维链很好,但代价呢?

蚂蚁武威:下一代「推理」模型范式大猜想
R1 之后,长思维链成为研究下一代基础模型中 “推理”(Reasoning)能力的热门方向。 一方面,R1 证明了大模型深度思考的可行性;与此同时,尽管 R1 展现出了强大的性能,大模型推理的序幕实则才刚刚拉开。 此外,R1 在海外掀桌也给国内人工智能的研究带来一个显著影响,即:越来越多的研究者敢于站在更高视角思考,提出前瞻引领的技术思想。

谷歌 DeepMind 通过强化学习微调提升 AI 决策能力
近期,谷歌 DeepMind 团队与约翰・开普勒林茨大学 LIT AI 实验室合作,开展了一项关于人工智能语言模型的新研究。 他们采用了强化学习微调(RLFT)技术,旨在提升语言模型的决策能力。 这项研究的重点在于,通过思维链的强化训练,解决了模型在决策过程中存在的一些关键问题。

ICML 2025 | 大模型深度思考新范式:交替「推理-擦除」解决所有可计算问题
作者介绍:本文第一作者是丰田工业大学芝加哥 PhD 学生杨晨晓,研究兴趣是机器学习理论和大模型推理,在 ICML,NeurIPS,ICLR 等顶级会议上发表过论文。 本文提出一个交替「推理 - 擦除」的深度思考新范式 PENCIL,比传统 CoT 更高效地解决更复杂的推理任务。 理论上,我们证明 PENCIL 可用最优空间与最优时间下解决所有可计算问题,而这对于传统的 CoT 是不可能的!

前苹果工程师公司ElastixAI筹集 1600 万美元,专注优化大语言模型的推理技术
最近,在美国西雅图成立了一家新创公司 ElastixAI,该公司由几位资深工程师创立,旨在解决大型语言模型部署过程中的成本和复杂性问题。 ElastixAI 专注于开发一种 AI 推理平台,旨在优化大型语言模型的运行方式。 该公司在刚成立几个月内,成功融资1600万美元,由位于贝尔维尤的风险投资公司 FUSE 领投。

看图猜位置不输o3!字节发布Seed1.5-VL多模态推理模型,在60个主流基准测试中拿下38项第一
在60个主流基准测试中拿下38项第一! 字节发布轻量级多模态推理模型Seed1.5-VL,仅用532M视觉编码器 200亿活跃参数就能与一众规模更大的顶尖模型掰手腕,还是能带图深度思考的那种。 相关技术报告也第一时间公开了。

仅20B参数!字节推出Seed1.5-VL多模态模型,实现38项SOTA
在上海举办的火山引擎 FORCE LINK AI 创新巡展上,字节跳动正式发布了最新的视觉 - 语言多模态模型 ——Seed1.5-VL。 该模型凭借其出色的通用多模态理解和推理能力,成为此次活动的焦点,吸引了众多业界专家和开发者的关注。 Seed1.5-VL 的显著特点是其增强的多模态理解与推理能力。

字节跳动发布新一代多模态大模型,挑战谷歌 Gemini 2.5 Pro
在人工智能领域竞争日益激烈的今天,字节跳动的 Seed 团队于5月13日正式发布了其最新的多模态大模型 Seed1.5-VL,旨在为智能体技术的进步铺平道路。 该模型经过超过3万亿 tokens 的多模态数据预训练,不仅具备强大的通用多模态理解和推理能力,还显著降低了推理成本。 与谷歌近期推出的 Gemini2.5Pro 相比,Seed1.5-VL 在性能上表现不相上下。

推理模型越来越强,大模型微调还有必要吗?
最近笔者在将大模型服务应用于实际业务系统时,首先一般习惯性用一些闭源api服务,花上几块钱快速测试下流程,然后在去分析下大模型效果。 如果通过几次调整Prompt或者超参数还是出现的bad cases比较多(比如输出结果的结构化有问题,输出结果不理想,在某些专业领域不同模型结果表现不一并且效果比较差),这个时候需要考虑下通过微调的方式来训练大模型。 现在的大模型推理能力越来越厉害,人们开始怀疑:我们还需要花时间和资源去微调大模型吗?

强迫模型自我争论,递归思考版CoT热度飙升!网友:这不就是大多数推理模型的套路吗?
CoT(Chain-of-thought)大家都很熟悉了,通过模仿「人类解题思路」,进而大幅提升语言模型的推理能力。 这几天,一个名为 CoRT(Chain-of-Recursive-Thoughts)的概念火了! 从名称上来看,它在 CoT 中加入了「递归思考」这一步骤。

UGMathBench动态基准测试数据集发布 可评估语言模型数学推理能力
近日,魔搭ModelScope社区宣布发布一项名为UGMathBench的动态基准测试数据集,旨在全面评估语言模型在本科数学广泛科目中的数学推理能力。 这一数据集的问世,填补了当前在本科数学领域评估语言模型推理能力的空白,并为研究者提供了更为丰富和具有挑战性的测试平台。 随着人工智能技术的飞速发展,自然语言模型在自动翻译、智能客服、医疗、金融等多个领域展现出巨大潜力。
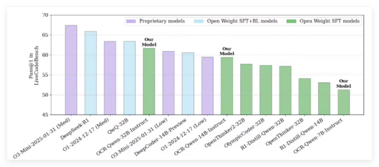
英伟达开源新一代OCR代码推理 AI 模型,超越 OpenAIo3-Mini表现
英伟达在技术界引起广泛关注,正式发布了其最新的 Open Code Reasoning(OCR)模型套装。 这一模型的推出,不仅展示了英伟达在人工智能领域的创新能力,也为开发者提供了强有力的工具,助力他们在代码推理和生成任务中取得更好的成绩。 ** 模型参数与架构:多样化选择 **英伟达的 OCR 模型套装共包含三种不同参数规模,分别为32B、14B 和7B。

英伟达新开源模型 Llama-Nemotron 震撼发布,推理性能超越 DeepSeek-R1
近日,英伟达正式推出了其最新开源模型系列 ——Llama-Nemotron,该系列模型不仅在推能力上超越了 DeepSeek-R1,更是在内存效率和吞吐量上实现了显著提升。 根据最新发布的技术报告,Llama-Nemotron 的训练过程与众不同,采用了合成数据监督微调与强化学习的方法,以全方位提升模型的推理能力。 Llama-Nemotron 系列模型包括 LN-Nano8B、LN-Super49B 和 LN-Ultra253B。

月之暗面 Kimi 长思考模型 API 正式发布
月之暗面科技有限公司宣布正式发布其最新的长思考模型API——kimi-thinking-preview。 这一模型具备多模态推理能力和通用推理能力,擅长深度推理,能够帮助用户解决复杂的代码问题、数学难题和工作中的挑战。 kimi-thinking-preview模型是目前最新的k系列思考模型,用户可以通过简单的API调用轻松使用。

用多模态LLM超越YOLOv3!强化学习突破多模态感知极限|开源
超越YOLOv3、Faster-RCNN,首个在COCO2017 val set上突破30AP的纯多模态开源LLM来啦! 华中科技大学、北京邮电大学等多所高校研究团队共同推出的Perception-R1(PR1),在视觉推理中最基础的感知层面,探究rule-based RL能给模型感知pattern带来的增益。 PR1重点关注当下主流的纯视觉(计数,通用目标检测)以及视觉语言(grounding,OCR)任务,实验结果展现出在模型感知策略上的巨大潜力。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉