清华大学

清华朱军团队Nature Machine Intelligence:多模态扩散模型实现心血管信号实时全面监测
可穿戴健康监测信号由于监测难度高、观测噪声大、易受干扰,高质量的心血管信号仍难以长期便捷获取,这是智能健康监测系统始终面临的现实困境。 近日,清华朱军等团队提出了一种统一的多模态生成框架 UniCardio,在单扩散模型中同时实现了心血管信号的去噪、插补与跨模态生成,为真实场景下的人工智能辅助医疗提供了一种新的解决思路。 相关工作《Versatile Cardiovascular Signal Generation with a Unified Diffusion Transformer》于 2025 年 12 月 29 日在 Nature Machine Intelligence 正式上线。

视频生成DeepSeek时刻!清华&生数开源框架提速200倍,一周斩获2k Star
在 2025 年的最后时刻,一个全新视频生成加速框架的开源宣告了:「等待数分钟才能生成一个视频」的时代已经终结! 这个框架正是清华大学 TSAIL 团队与生数科技联合发布的 TurboDiffusion。 加速效果有多夸张呢?

NeurIPS 2025|指哪打哪,可控对抗样本生成器来了!
近日,在全球人工智能领域最具影响力的顶级学术会议 NeurIPS(神经信息处理系统大会)上, 清华大学和蚂蚁数科联合提出了一种名为 Dual-Flow 的新型对抗攻击生成框架。 简单来说,Dual-Flow 是一个能够从海量图像数据中学习 “通用扰动规律” 的系统,它不依赖目标模型结构、不需要梯度,却能对多种模型、多种类别发起黑盒攻击。 其核心思想是通过 “前向扰动建模 — 条件反向优化” 的双流结构,实现对抗样本的高可迁移性与高成功率,同时保持极低的视觉差异。

华大学发布首个系统性《人工智能教育应用指导原则》:严防“AI 学术依赖”
清华大学近日正式发布《清华大学人工智能教育应用指导原则》(以下简称《指导原则》),这是该校首次以系统化形式对校园内人工智能的使用提出全局性、分场景的规范与引导,覆盖教学、学术研究等核心教育活动。 《指导原则》由“总则”“教学篇”“学位论文及实践成果篇”三大部分构成。 其中,“总则”明确学校在人工智能时代采取“积极而审慎”的基本立场,并提出“五项核心原则”:主体责任:AI 始终是辅助工具,师生才是教学与学习的主体;合规诚信:使用 AI 必须披露情况,严禁任何形式的学术不端;数据安全:禁止使用敏感、涉密或未授权数据训练或驱动 AI 模型;审慎思辨:鼓励多源验证,避免因依赖 AI 造成思维惰化;公平包容:主动识别与减少算法偏见,关注数字鸿沟。

清华新发现:AI大模型不止看“块头”,更要重视密度
近日,清华大学的研究团队在国际期刊《自然・机器智能》上发表了一项颇具启发性的研究成果,提出了 “能力密度” 这一新概念。 这项研究挑战了传统观点,认为在评估 AI 大模型的实力时,不应仅仅关注模型的参数数量,也就是 “块头”,而更应关注每个参数所展现的智能水平,即 “密度”。 传统上,AI 领域普遍认为模型越大,能力越强,这一 “规模法则” 在过去几年中推动了众多强大 AI 模型的涌现。

2M大小模型定义表格理解极限,清华大学崔鹏团队开源LimiX-2M
提到 AI 的突破,人们首先想到的往往是大语言模型(LLM):写代码、生成文本、甚至推理多模态内容,几乎重塑了通用智能的边界。 但在一个看似 “简单” 的领域 —— 结构化表格数据上,这些强大的模型却频频失手。 电网调度、用户建模、通信日志…… 现实世界中大量关键系统的核心数据都以表格形式存在。

清华团队:1.5B 模型新基线!用「最笨」的 RL 配方达到顶尖性能
如果有人告诉你:不用分阶段做强化学习、不搞课程学习、不动态调参,只用最基础的 RL 配方就能达到小模型数学推理能力 SOTA,你信吗? 清华团队用两个 1.5B 模型给出了答案:不仅可行,还特别高效。 核心发现: 单阶段训练 固定超参数 = SOTA 性能 省一半算力意外之喜: 训练曲线平滑得像教科书,4000 步没遇到任何 "典型问题"关键启示: 充分 scale 的简单 baseline,可能比我们想象的强大得多技术博客::::RL 训练小模型的 "技术军备竞赛"2025 年初,DeepSeek-R1 开源后,如何用 RL 训练 1.5B 级别的推理模型成为了热门研究方向。

“昆山杯”第27届清华大学创业大赛火热报名!
大赛报名表:. *本文为量子位获授权转载。
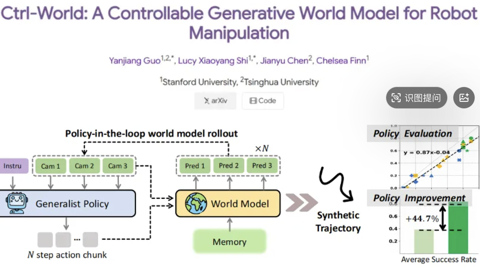
让机器人在“想象”中学习世界的模型来了!PI联创课题组&清华陈建宇团队联合出品
Ctrl-World团队 投稿. 量子位 | 公众号 QbitAI这两天,Physical Intelligence(PI)联合创始人Chelsea Finn在上,对斯坦福课题组一项最新世界模型工作kuakua连续点赞。 生成看起来不错的视频很容易,难的是构建一个真正对机器人有用的通用模型——它需要紧密跟随动作,还要足够准确以避免频繁幻觉。

清华、快手提出AttnRL:让大模型用「注意力」探索
从 AlphaGo 战胜人类棋手,到 GPT 系列展现出惊人的推理与语言能力,强化学习(Reinforcement Learning, RL)一直是让机器「学会思考」的关键驱动力。 然而,在让大模型真正掌握「推理能力」的道路上,探索效率仍是一道难以逾越的鸿沟。 当下最前沿的强化学习范式之一——过程监督强化学习(Process-Supervised RL, PSRL),让模型不再只看「结果对不对」,而是学会在「推理过程」中不断修正自己。

稳定训练、数据高效,清华大学提出「流策略」强化学习新方法SAC Flow
本文介绍了一种用高数据效率强化学习算法 SAC 训练流策略的新方案,可以端到端优化真实的流策略,而无需采用替代目标或者策略蒸馏。 SAC FLow 的核心思想是把流策略视作一个 residual RNN,再用 GRU 门控和 Transformer Decoder 两套速度参数化。 SAC FLow 在 MuJoCo、OGBench、Robomimic 上达到了极高的数据效率和显著 SOTA 的性能。

北京清华长庚医院与北电数智签署战略合作,赋能药学创新和睡眠医学研究
10月16日,北京清华长庚医院与北京电子数智科技有限责任公司(简称“北电数智”)达成战略合作。 依托北电数智“星火·医疗底座”,双方将在药学大模型、睡眠大模型、药学可信空间、具身智能等多个“AI 医疗”创新领域开展联合攻关,并在北京清华长庚医院率先落地应用,打通技术迭代与临床验证的闭环,提升医疗服务效率与智能化水平,推动医疗普惠进程,助力健康中国战略。 北京清华长庚医院院长董家鸿院士,北京清华长庚医院副院长张萍,北电数智董事长荆磊,北电数智首席科学家、复旦大学特聘教授窦德景,北电数智产业生态负责人吴岳,AI可信负责人邵兵等出席签约仪式。

当Search Agent遇上不靠谱搜索结果,清华团队祭出自动化红队框架SafeSearch
该文第一作者是清华大学博士生董建硕,研究方向是大语言模型运行安全;该文通讯作者是清华大学邱寒副教授;其他合作者来自南洋理工大学和零一万物。 在 AI 发展的新阶段,大模型不再局限于静态知识,而是可以通过「Search Agent」的形式实时连接互联网。 搜索工具让模型突破了训练时间的限制,但它们返回的并非总是高质量的资料:一个低质量网页、一条虚假消息,甚至是暗藏诱导的提示,都可能在用户毫无察觉的情况下被模型「采纳」,进而生成带有风险的回答。

RL 将如何提高具身大模型 VLA 泛化性?清华大学团队NeurIPS 2025文章分析 RL 与 SFT 泛化性差异
在具身智能领域,视觉 - 语言 - 动作(VLA)大模型正展现出巨大潜力,但仍面临一个关键挑战:当前主流的有监督微调(SFT)训练方式,往往让模型在遇到新环境或任务时容易出错,难以真正做到类人般的泛化。 但在大语言模型(LLM/VLM)领域,强化学习(RL)已被证明能显著提升模型的泛化能力。 RL 究竟能为 VLA 带来哪些独特的泛化优势?

2025大模型服务性能排行榜:PPIO吞吐测试排名第一
9 月 13 日,在 GOSIM2025 大会上,清华大学携手中国软件评测中心联合发布了《2025 大模型服务性能排行榜》,PPIO 在 DeepSeek-R1-0528的吞吐测试中排名第一。 该榜单从延迟、吞吐、可靠性等关键指标切入,由专业团队通过长周期、高频率、多时段的数据评测,直观呈现不同MaaS供应商的服务表现。 而且,平台以匿名用户身份对 MaaS(Model as a Service)平台开展产品端到端的性能测评,从评测主体与流程上双重保障了客观公正性。

清华大学唯一持股具身智能企业“星动纪元”完成近 5 亿元 A 轮融资
AI在线 7 月 7 日消息,星动纪元今日宣布完成近 5 亿元 A 轮融资。 本轮融资由鼎晖 VGC 和海尔资本联合领投,厚雪资本、华映资本、襄禾资本、丰立智能等知名财务机构及产业资本跟投,老股东清流资本、清控基金等机构持续加码。 华兴资本担任本轮独家财务顾问。

腾讯公益首次引入AI大模型,提升公益项目互动体验
近日,腾讯公益正式推出了 “问 AI” 功能,这是该平台首次将大型人工智能模型应用于公益领域。 这项创新的功能允许用户就腾讯公益的各类项目和机构进行提问,旨在提升公众与公益组织之间的互动和透明度。 “问 AI” 功能的上线,标志着腾讯在公益事业上的又一次突破。

华为、清华大学合作打造首个园区网络智能体:17 万终端全方位覆盖,一句话定位问题、自动优化 Wi-Fi
与清华本地部署的 DeepSeek 深度协同,智能体自主处置网络故障,推动网络运维从“被动应对”跃入“自动驾驶”新时代。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
字节跳动
大语言模型
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉