
从 AlphaGo 战胜人类棋手,到 GPT 系列展现出惊人的推理与语言能力,强化学习(Reinforcement Learning, RL)一直是让机器「学会思考」的关键驱动力。
然而,在让大模型真正掌握「推理能力」的道路上,探索效率仍是一道难以逾越的鸿沟。
当下最前沿的强化学习范式之一——过程监督强化学习(Process-Supervised RL, PSRL),让模型不再只看「结果对不对」,而是学会在「推理过程」中不断修正自己。
然而,传统的过程监督强化学习方法在探索效率和训练成本上仍存在明显瓶颈。
为此,来自清华和快手的研究团队提出了一种新框架 AttnRL,通过引入注意力机制作为探索的「指南针」,显著提升了过程监督强化学习的效率与性能。

论文标题:Attention as a Compass: Efficient Exploration for Process-Supervised RL in Reasoning Models
论文链接:https://arxiv.org/abs/2509.26628
GitHub:https://github.com/RyanLiu112/AttnRL
HuggingFace:https://huggingface.co/papers/2509.26628
过程监督RL的现实困境
传统的结果监督强化学习方法对所有token赋予相同的奖励信号,忽略了推理过程中的细粒度质量。过程监督强化学习方法虽然能提供更精细的奖励,但在分支位置选择和采样策略上效率低下,导致训练成本高昂:
分支策略粗糙:往往按固定长度或熵划分,忽视语义和推理行为;
采样效率低下:在简单和困难问题间一视同仁,导致大量计算浪费在简单问题上;
训练流程冗余:每次训练需进行两次采样,显著增加了时间与计算成本。
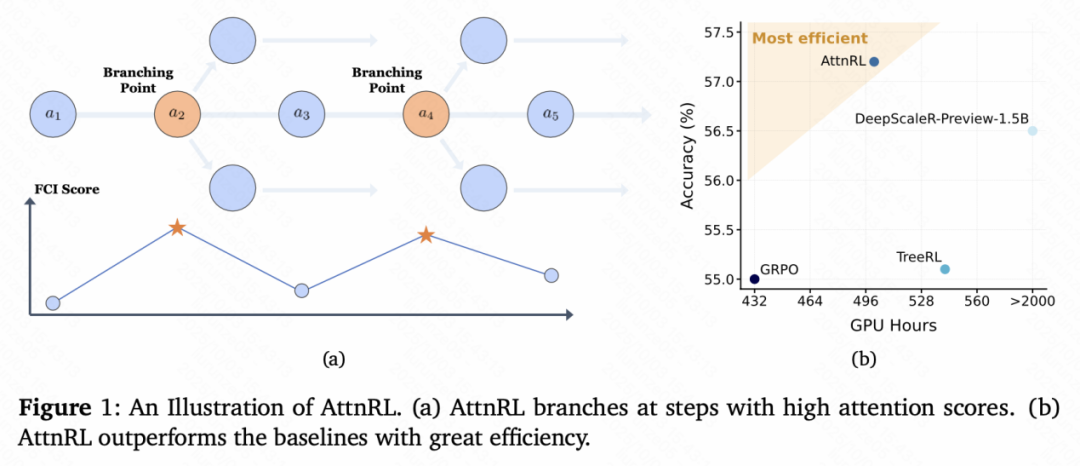
为解决这些难题,研究者提出了全新的过程监督强化学习框架——AttnRL,并将注意力机制首次引入推理探索过程,使「注意力」真正成为模型的推理「指南针」。如上图所示,AttnRL 在注意力分数高的步骤进行分支,并在效果和效率上超过了基线方法。
研究核心:让注意力引导探索
研究团队的关键洞察是:在大模型的推理过程中,那些注意力得分高的步骤,往往恰好对应「真正的思考时刻」——模型在规划、自我验证或转折时的关键推理节点。
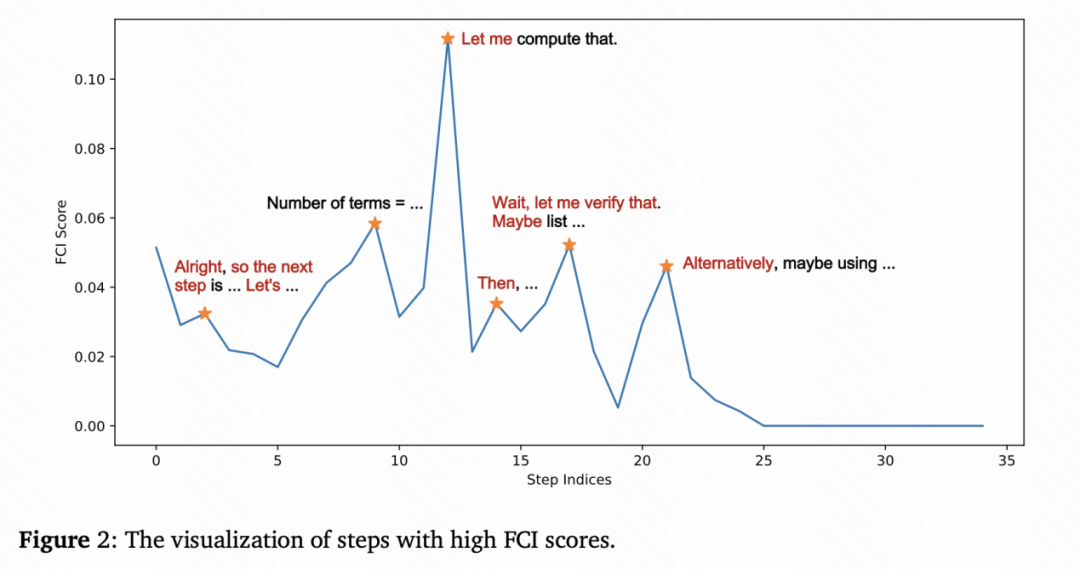
因此,AttnRL 提出了一种创新的探索方式:
不再随机地从任意位置「分支探索」,而是让模型从高注意力的关键步骤出发,去探索新的推理路径。
论文将这种策略称为Attention-based Tree Branching(ATB),ATB会分析推理序列中的每个步骤,通过计算「前向上下文影响力(Forward Context Influence, FCI)」分数来衡量其对后续推理的影响程度,然后只在FCI得分最高的几个位置建立分支。这种机制让模型能够「少走弯路」,在推理树中更快找到高质量路径。
具体来说,AttnRL首先对回答进行分步,计算步骤-步骤之间的注意力分数矩阵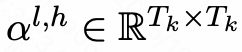 ,其中,
,其中,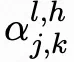 表示步骤j注意步骤k在第l层第h个注意力头的分数。计算步骤k后续所有步骤的注意力分数之和:
表示步骤j注意步骤k在第l层第h个注意力头的分数。计算步骤k后续所有步骤的注意力分数之和:
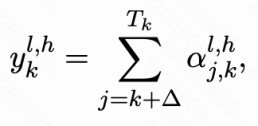
取所有层和注意力头的最大值,即为FCI分数:
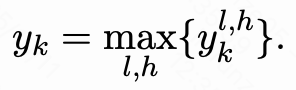
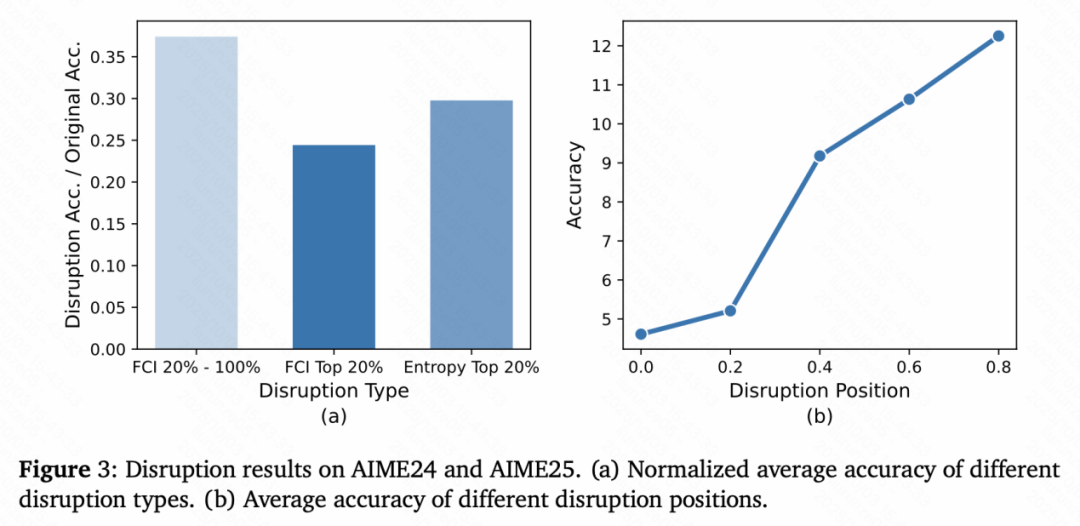
实验结果表明,破坏这些高注意力步骤会显著降低模型的解题准确率,证明它们确实是推理过程的关键节点。
自适应采样:让模型在「最值得学」的地方学习
传统的PSRL方法往往采用固定比例、均匀采样的方式进行探索,无论任务难易都同等对待,导致大量算力浪费在「简单题」上。
AttnRL引入了两种自适应采样机制:
难度感知探索:根据FCI分数过滤掉那些在两次采样中大概率100%正确的「简单题」,对于困难问题,模型会扩展更多「推理树」来探索解法;而对简单问题,则自动缩减计算量;
动态批次调整:根据当前有效样本数动态调整采样批次大小,保证每次训练中,所有样本的梯度都「有贡献」(即非零advantage),大幅提升了训练效率。
高效训练:一步采样,性能反超
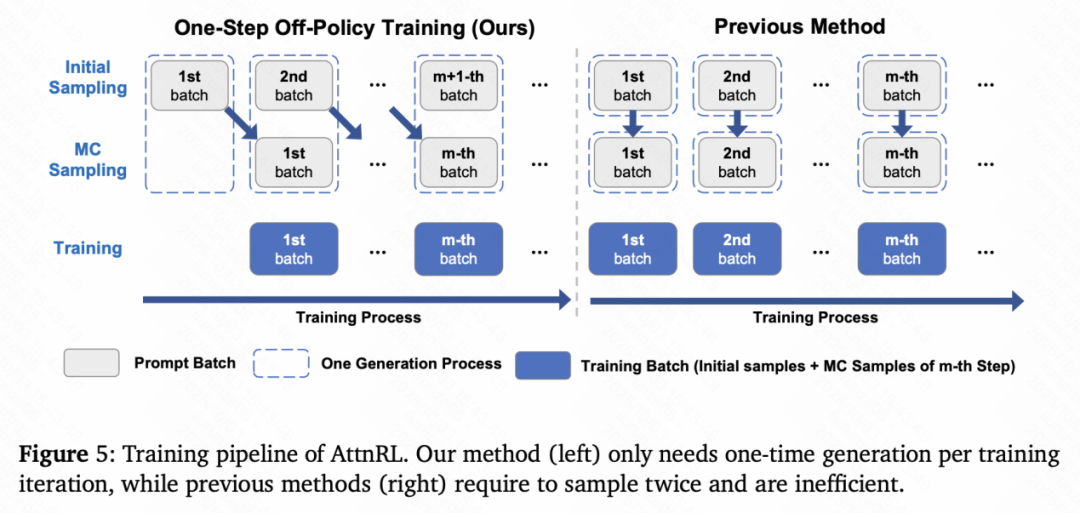
在工程层面,AttnRL设计了一个 One-Step Off-Policy 的训练流程:
以前的 PSRL 方法在每次更新都需要两次生成(初始采样+蒙特卡洛采样),采样成本高。而 AttnRL 在第 m 步训练时对 m‑1 批进行蒙特卡罗采样,对m+1批进行初始采样,将初始采样与蒙特卡罗采样交错执行,每步只生成一次即可得到训练所需的两类样本。
实验结果:性能与效率双赢
主要结果
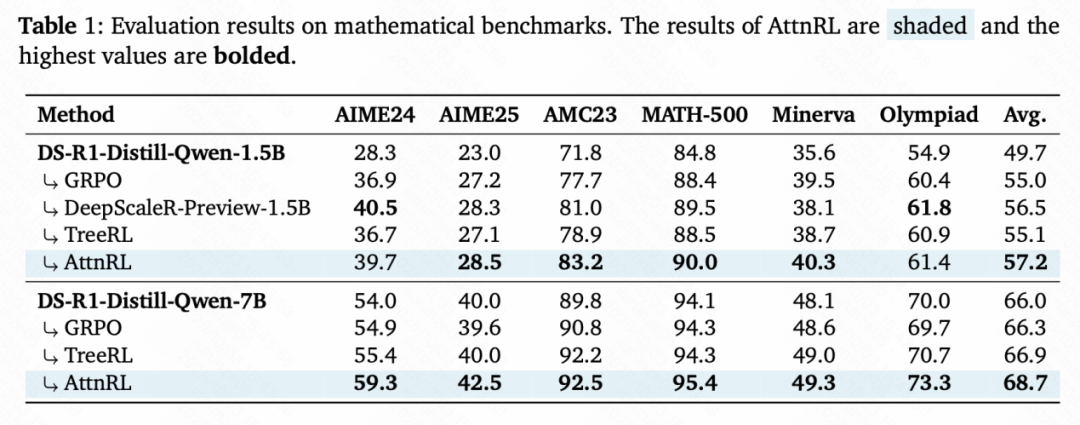
在AIME24/25、AMC23、MATH-500、Minerva、Olympiad等六个数学推理基准上,AttnRL对1.5B与7B两个基座均稳定提升,平均准确率分别达到57.2%与68.7%,显著高于GRPO、TreeRL及强RLVR基线方法;
相比DeepScaleR-Preview-1.5B(1750步,24K上下文),AttnRL仅需500步、8K上下文即实现更优结果。
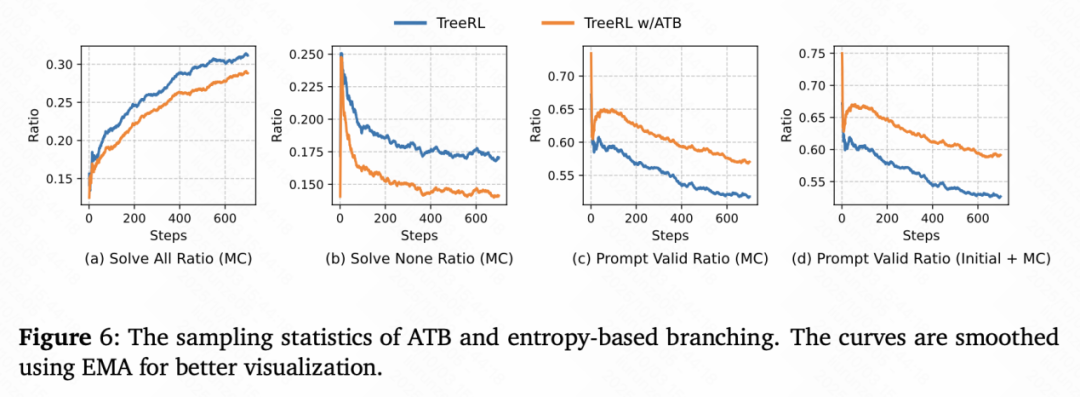
分支采样更高效
基于注意力的分支方法相比于熵分支(TreeRL),在「全对比例」、「全错比例」、「有效比例」等统计上全面占优,AttnRL 在简单题采样到更多错误回答,在困难题采样到更多正确回答,证明了 AttnRL 分支采样更加高效。
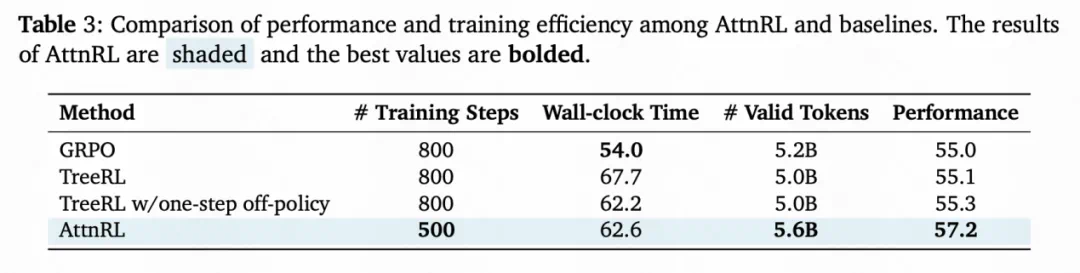
采样更「干净」
自适应采样让每个批次的每个 token 都有非零优势,训练信号密度显著提高。相比于 GRPO 和 TreeRL,AttnRL 在更少的训练步数下达到更高性能,并且动态批次机制确保每批次中所有样本均有效,使 AttnRL 能够训练更多有效token。
未来展望
AttnRL 将「注意力分数」首次用于过程监督强化学习的探索决策,把探索预算投向「影响后续最多」的关键推理步骤,为未来的大模型可解释性与强化学习研究打开了新的方向。它启示我们:在让模型「思考得更好」的路上,效率与智能并非对立,而是可以通过更高效的探索实现共赢。


