
本文介绍了一种用高数据效率强化学习算法 SAC 训练流策略的新方案,可以端到端优化真实的流策略,而无需采用替代目标或者策略蒸馏。SAC FLow 的核心思想是把流策略视作一个 residual RNN,再用 GRU 门控和 Transformer Decoder 两套速度参数化。SAC FLow 在 MuJoCo、OGBench、Robomimic 上达到了极高的数据效率和显著 SOTA 的性能。
作者来自于清华大学和 CMU,通讯作者为清华大学教授丁文伯和于超,致力于强化学习算法和具身智能研究。
研究背景
流策略(Flow-based policy)最近在机器人学习领域十分热门:它具有建模多峰动作分布的表达能力,且比扩散策略更简洁好用,因此被广泛应用于先进的 VLA 模型,例如 π_0、GR00T 等。想要跳出数据集的约束,进一步提高流策略的性能,强化学习是一条有效的路,已经有不少工作尝试用 on-policy 的 RL 算法训练流策略,例如 ReinFlow [1]、 Flow GRPO [2] 等。但当我们使用数据高效的 off-policy RL(例如 SAC )训练流策略时总会出现崩溃,因为流策略的动作经历「K 步采样」推理,因此反向传播的「深度」等于采样步数 K。这与训练经典 RNN 时遇到的梯度爆炸或梯度消失是相同的。
不少已有的类似工作都选择绕开了这个问题:要么用替代目标避免对流策略多步采样的过程求梯度 (如 FlowRL [3]),要么把流匹配模型蒸馏成单步模型,再用标准 off-policy 目标训练 (如 QC-FQL [4])。这样做是稳定了训练,但也抛弃了原本表达更强的流策略本体,并没有真正在训练一个流策略。而我们的思路是:发现流策略多部采样本质就是 sequential model ,进而用先进的 sequential model 结构来稳住训练,直接在 off-policy 框架内端到端优化真实的流策略。
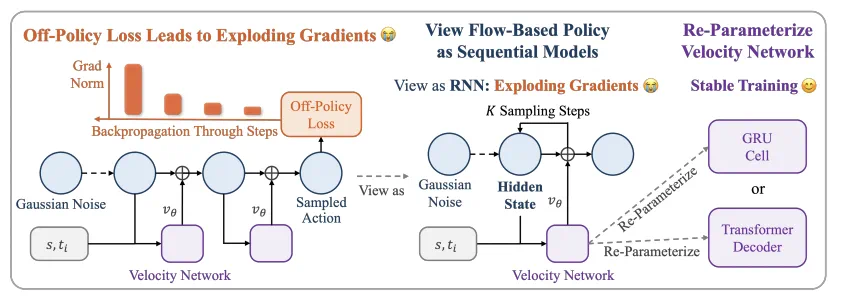
使用 off policy RL 算法训练流策略会出现梯度爆炸。本文提出,我们不妨换一个视角来看,训练流策略等效于在训练一个 RNN 网络(循环计算 K 次),因此我们可以用更高效现代的循环结构(例如 GRU,Transformer)。

论文链接:https://arxiv.org/abs/2509.25756
项目网站:https://sac-flow.github.io/
代码仓库:https://github.com/Elessar123/SAC-FLOW
核心思想:Flow rollout ≈ Residual RNN
把每一步的中间动作 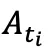 作为隐状态,
作为隐状态,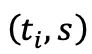 作为输入,那么 Euler 积分
作为输入,那么 Euler 积分 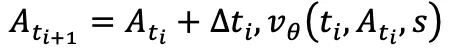 就等价于一个 residual RNN 的单步前向。于是对流策略的 K 步采样过程进行反传就,等价于对一个 RNN 网络反传!这也难怪以往的 off-policy 训练会遇到不稳定的问题。既然如此,就把流策略中的速度网络
就等价于一个 residual RNN 的单步前向。于是对流策略的 K 步采样过程进行反传就,等价于对一个 RNN 网络反传!这也难怪以往的 off-policy 训练会遇到不稳定的问题。既然如此,就把流策略中的速度网络 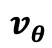 换成为循环而生的现代的稳定结构:
换成为循环而生的现代的稳定结构:
Flow-G(GRU,gated velocity) :给速度网络加上 GRU 风格的门控结构 ,自适应决定「保留当前动作」还是「写入新动作」,抑制梯度放大。
Flow-T(Transformer, decoded velocity) :用 Transformer decoder 对「动作 - 时间 token」做 state-only cross-attention + 预归一残差 FFN ,每一步都在全局 state 语境下稳态细化;保持 Markov 性,不做时间位点之间的自回归混合。
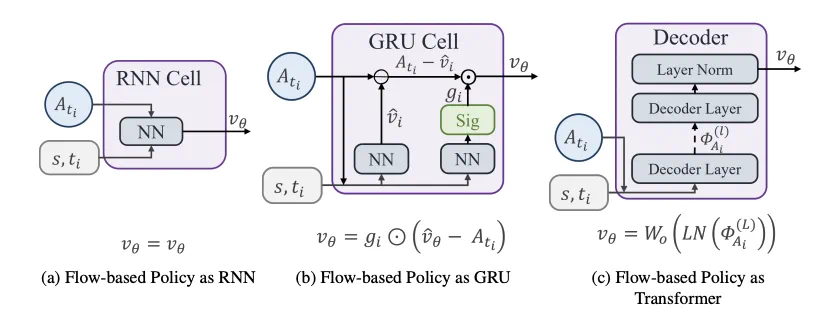
流策略的速度网络参数化方式,从 sequential model 的视角进行展示。
对应的速度网络参数化
Flow-G: 用门控
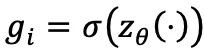 去调和「保留
去调和「保留 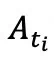 」 和「写入候选
」 和「写入候选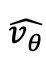 」:
」: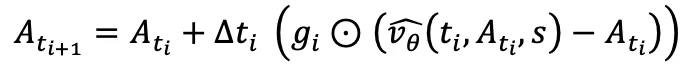 这与 GRU 的更新过程一一对应。
这与 GRU 的更新过程一一对应。Flow-T: 给「动作 - 时间 token」与「全局 state token」分别编码,然后在 decoder 里做 state-only cross-attention (自注意仅作对角 / 逐位置变换,不跨时间混合,为了保留 flow 模型的 Markov 性质),再用 pre-norm 和残差 FFN 构成的多层 Decoder Layer ,最后线性投影到速度
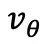 。
。
我们的方法:SAC Flow
1.让 SAC 真正能训练流策略:noise-augmented 对数似然
在直接训练 SAC Flow 之前,还有一个关于 SAC 的小问题需要解决。SAC 需要 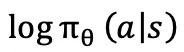 做熵正则化,但确定性的 K 步采样没法直接给出可积的密度。因此,SAC Flow 在每步 rollout 里加高斯噪声 + 配套漂移修正 ,保证末端动作分布不变,同时把路径密度分解为单步高斯似然的连乘,从而得到可计算、可微的
做熵正则化,但确定性的 K 步采样没法直接给出可积的密度。因此,SAC Flow 在每步 rollout 里加高斯噪声 + 配套漂移修正 ,保证末端动作分布不变,同时把路径密度分解为单步高斯似然的连乘,从而得到可计算、可微的 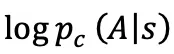 。这样,SAC 的 actor/critic loss 都可以直接用流策略多步采样的对数似然来表示。
。这样,SAC 的 actor/critic loss 都可以直接用流策略多步采样的对数似然来表示。
2.两种训练范式都能用
From-scratch :对于 dense-reward 任务,SAC flow 可以 from scratch 直接训练。
Offline-to-online :对于 sparse-reward 且有示例数据的任务,SAC flow 支持先在数据集上预训练,再进行在线微调。微调时,需要在 SAC actor 里加一个正则项目
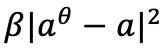 。
。
训练伪代码如下:

实验结果:稳定、快速、样本效率高!
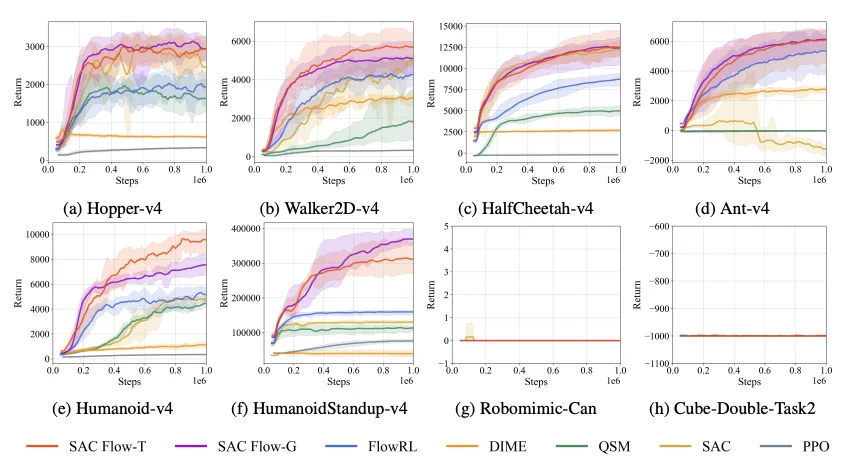
在 From-scratch 条件下,我们主要测试了 Mujoco 的环境上的表现。Flow-G 和 Flow-T 达到了 SOTA 的性能水平。同时可以发现,在稀疏奖励任务中,from-scratch 是不够的,需要使用 offline pretrain。
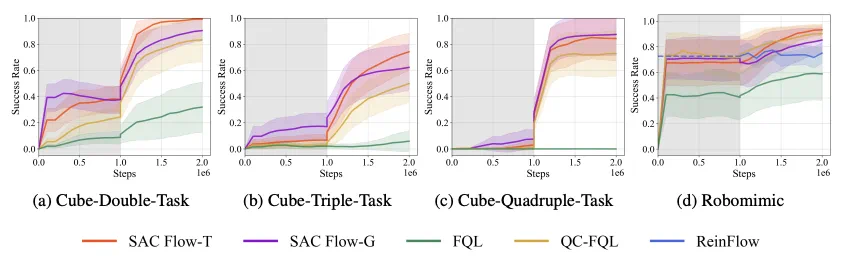
Offline-to-online 训练结果。其中灰色背景下的前 1e6 step 是 offline 训练,后 1e6 steps 是 online 微调。
From-scratch
SAC Flow-T / Flow-G 在 Hopper、Walker2D、HalfCheetah、Ant、Humanoid、HumanoidStandup 上稳定更快收敛 ,最终回报更高。
相比扩散策略基线(如 DIME 、QSM ),Flow -based 方法普遍收敛更快。在此基础上,SAC Flow 进一步超过 FlowRL (因为 FlowRL 使用 Wasserstein 约束限制了性能)。
在最难的 sparse-reward 任务中(如 Robomimic-Can、OGBench-Cube-Double),从零探索仍然很难,这也说明了 offline-to-online 训练的必要性。
Offline-to-online
在 OGBench 的 Cube-Triple / Quadruple 等高难度任务中,SAC Flow-T 收敛更快,整体成功率领先或持平现有 off-policy 基线(FQL、QC-FQL )。
在 Robomimic benchmark 中,我们使用了较大的正则化约束限制,因此 SAC Flow 的表达能力受到限制,表现与 QC-FQL 接近。但在同等在线数据量下,我们的表现依然优于 on-policy 的基线算法 ReinFlow。
消融实验:
1.稳定梯度,防止梯度爆炸
我们直接用 SAC 微调流策略(Naive SAC Flow),其梯度范数在反传路径上呈现爆炸趋势 (绿色)。而 Flow-G / Flow-T 的梯度范数保持平稳(橙色、紫色)。对应地,SAC Flow-T 和 Flow-G 的性能显著更优。
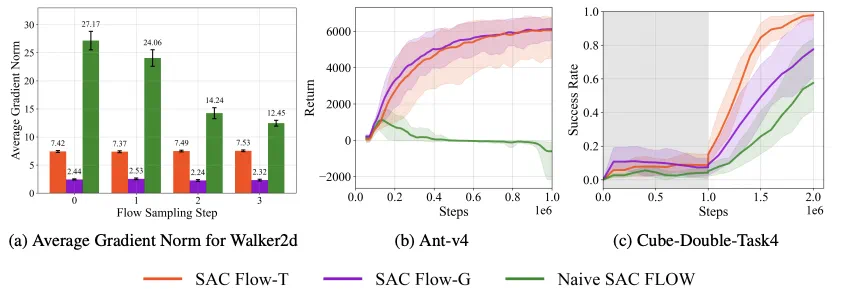
(a)不同采样步上的梯度范数。(b) from-scratch 训练中, Ant 环境下如果直接用 SAC 训练流策略,会导致训练崩溃。(c) 在 offline-to-online 训练中,直接 SAC 训练流策略依然效率较低,不够稳定。
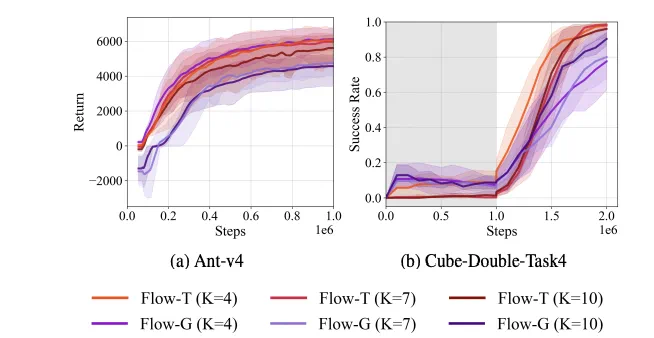
2.对采样步数鲁棒
SAC Flow 对 K (采样步数)是鲁棒的:在 K=4/7/10 条件下都能稳定训练。其中 Flow-T 对采样深度的鲁棒性尤其强。
与类似工作的核心区别
FlowRL 使用 Wasserstein-2 约束的替代目标。与之相比,SAC Flow 则直接端到端优化标准 SAC loss,避免「目标 - 模型错位」。
DIME / QSM 等扩散策略方法同样使用了替代目标。
FQL / QC-FQL 则把流策略首先蒸馏单步模型,然后再做 off-policy RL。相比之下,SAC Flow 不需要蒸馏为单步模型,保留了流模型的建模能力。
什么时候用 Flow-G?什么时候用 Flow-T?
Flow-G :参数量更小、结构更简洁,在需要快速收敛或计算预算有限的场景。
Flow-T :当环境更复杂、需要更强的条件建模和深度时,Flow-T 的稳定性和上限更好。
结语
SAC Flow 的关键词只有三个:序列化 、稳定训练、数据高效。把流策略视作序列模型,进而能够用 GRU / Transformer 的成熟经验稳定梯度回传。加上一些辅助技巧,我们可以直接使用 off-policy RL 的代表算法 SAC 来训练流策略,从而实现数据高效、更快、更稳的收敛。后续,我们将继续推动 SAC-flow 在真实机器人上的效果验证,提升 sim-to-real 的鲁棒性。
参考文献:
[1] Zhang, Tonghe, et al. "ReinFlow: Fine-tuning Flow Matching Policy with Online Reinforcement Learning." arXiv preprint arXiv:2505.22094 (2025).
[2] Liu, Jie, et al. "Flow-grpo: Training flow matching models via online rl." arXiv preprint arXiv:2505.05470 (2025).
[3] Lv, L., Li, Y., Luo, Y., Sun, F., Kong, T., Xu, J., & Ma, X. (2025). Flow-Based Policy for Online Reinforcement Learning.arXiv preprint arXiv:2506.12811.
[4] Li, Q., Zhou, Z., & Levine, S. (2025). Reinforcement learning with action chunking.arXiv preprint arXiv:2507.07969.


