Ctrl-World团队 投稿
量子位 | 公众号 QbitAI
这两天,Physical Intelligence(PI)联合创始人Chelsea Finn在上,对斯坦福课题组一项最新世界模型工作kuakua连续点赞。
生成看起来不错的视频很容易,难的是构建一个真正对机器人有用的通用模型——它需要紧密跟随动作,还要足够准确以避免频繁幻觉。
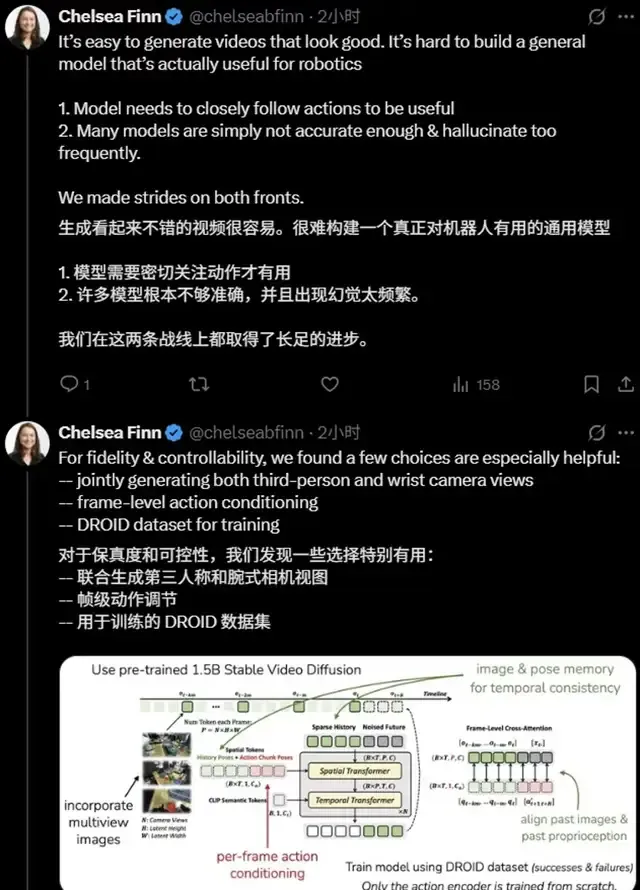
这项研究,正是她在斯坦福带领的课题组与清华大学陈建宇团队联合提出的可控生成世界模型Ctrl-World。
这是一个能让机器人在“想象空间”中完成任务预演、策略评估与自我迭代的突破性方案。
核心数据显示,该模型使用零真机数据,大幅提升策略在某些在下游任务的指令跟随能力,成功率从38.7%提升至83.4%,平均改进幅度达44.7%。
其相关论文《CTRL-WORLD:A CONTROLLABLE GENERATIVE WORLD MODEL FOR ROBOT MANIPULATION》已发布于arXiv平台。

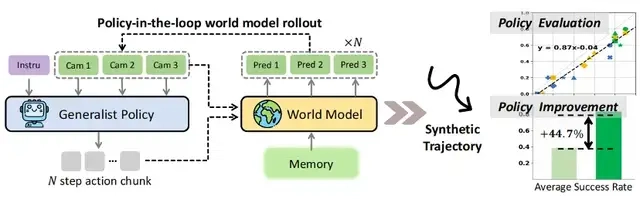
注:Ctrl-World专为通用机器人策略的策略在环轨迹推演而设计。它生成联合多视角预测(包括腕部视角),通过帧级条件控制实现细粒度动作控制,并通过姿态条件记忆检索维持连贯的长时程动态。这些组件实现了:(1)在想象中进行精准的策略评估,并与真实世界轨迹推演对齐(2)通过合成轨迹实现针对性的策略改进
当前,视觉-语言-动作(VLA)模型虽在多种操作任务与场景中展现出卓越性能,但在开放世界场景中仍面临两大核心难题,这也是团队研发CTRL-WORLD的核心动因:
难题一,策略评估成本高,真实测试烧钱又低效。
验证机器人策略性能需在不同场景、任务中反复试错。
以“抓取物体”任务为例,研究者需准备大小、材质、形状各异的物体,搭配不同光照、桌面纹理的环境,让机器人重复成百上千次操作。
不仅如此,测试中还可能出现机械臂碰撞(故障率约5%-8%)、物体损坏(损耗成本单轮测试超千元)等问题,单策略评估周期常达数天。更关键的是,抽样测试无法覆盖所有潜在场景,难以全面暴露策略缺陷。
难题二,策略迭代同样难,真实场景数据永远不够用。
即便在含95k轨迹、564个场景的DROID数据集上训练的主流模型π₀.₅,面对“抓取左上角物体”“折叠带花纹毛巾”等陌生指令或“手套、订书机”等未见过的物体时,成功率仅38.7%。
传统改进方式依赖人类专家标注新数据,但标注速度远赶不上场景更新速度——标注100条高质量折叠毛巾轨迹需资深工程师20小时,成本超万元,且无法覆盖所有异形物体与指令变体。
开放世界尚存在棘手问题,另一边,传统世界模型目前也还面临三大痛点——
为解决真实世界依赖,学界曾尝试用世界模型(即虚拟模拟器)让机器人在想象中训练。
但研究团队在论文《CTRL-WORLD:A CONTROLLABLE GENERATIVE WORLD MODEL FOR ROBOT MANIPULATION》中指出,现有世界模型多数方法聚焦于被动视频预测场景,无法与先进通用策略进行主动交互。
具体来说,存在三大关键局限,阻碍其支持策略在环(policy-in-the-loop)推演:
- 单视角导致幻觉
- 多数模型仅模拟单一第三人称视角,导致“部分可观测性问题”——例如机械臂抓取物体时,模型看不到腕部与物体的接触状态,可能出现“物体无物理接触却瞬移到夹爪中”的幻觉;
- 动作控制不精细
- 传统模型多依赖文本或初始图像条件,无法绑定高频、细微的动作信号,例如机械臂“Z轴移动6厘米”与“Z轴移动4厘米”的差异无法被准确反映,导致虚拟预演与真实动作脱节;
- 长时一致性差
- 随着预测时间延长,微小误差会不断累积,导致“时序漂移”——论文实验显示,传统模型在10秒预演后,物体位置与真实物理规律的偏差,失去参考价值。
为此,清华大学陈建宇与斯坦福大学Chelsea Finn两大团队联合提出CTRL-WORLD,旨在构建一个“能精准模拟、可长期稳定、与真实对齐”的机器人虚拟训练空间,让机器人通过“想象”训练。
Ctrl-World通过三项针对性设计,解决了传统世界模型的痛点,实现“高保真、可控制、长连贯”的虚拟预演。
论文强调,这三大创新共同将“被动视频生成模型”转化为“可与VLA策略闭环交互的模拟器”。
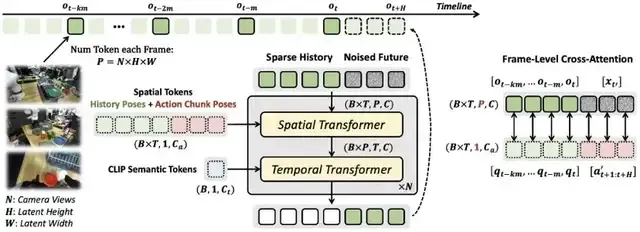
Ctrl-World基于预训练视频扩散模型初始化,并通过以下方式适配为一个可控且时间一致的世界模型:
- 多视角输入与联合预测
- 帧级动作条件控制
- 姿态条件记忆检索
一般来说,以往模型靠单视图预测,存在部分观测问题与幻觉。
而Ctrl-World结合第三人称与腕部视图联合预测,生成的未来轨迹精准且贴合真实情况。

传统世界模型仅模拟单一第三方视角,本质是“信息不全”。
而CTRL-WORLD创新性地联合生成第三方全局视角+腕部第一视角:
- 第三方视角提供环境全局信息(如物体在桌面的整体布局),腕部视角捕捉接触细节(如机械爪与毛巾的摩擦、与抽屉的碰撞位置);
- 模型通过空间Transformer将多视角图像token拼接(单帧含3个192×320图像,编码为24×40latent特征),实现跨视角空间关系对齐。
论文实验验证了这一设计的价值:
在涉及机械臂与物体接触的精细操作任务中(如抓取小型物体),腕部视角可精准捕捉夹爪与物体的接触状态(如捏合力度、接触位置),显著减少“无物理接触却完成抓取的幻觉”。
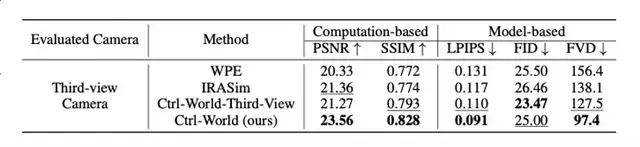
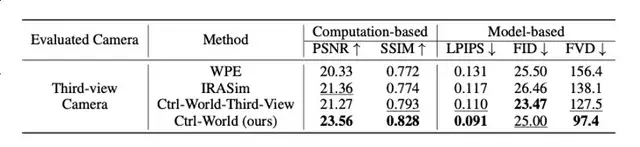
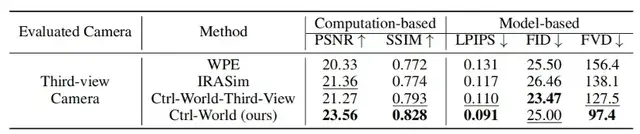
定量数据显示,该设计使物体交互幻觉率降低;在多视角评估中,Ctrl-World的峰值信噪比(PSNR)达23.56,远超传统单视角模型WPE(20.33)和IRASim(21.36),结构相似性(SSIM)0.828也显著高于基线(WPE0.772、IRASim0.774),证明虚拟画面与真实场景的高度契合。
要让虚拟预演“可控”,必须建立“动作-视觉”的强因果关系。
Ctrl-World的解决方案是“帧级动作绑定”:
- 将机器人输出的动作序列(如关节速度)转化为笛卡尔空间中的机械臂姿态参数;
- 通过帧级交叉注意力模块,让每一帧的视觉预测都与对应的姿态参数严格对齐——就像“分镜脚本”对应每一幕剧情,确保“动作A必然导致视觉结果B”。
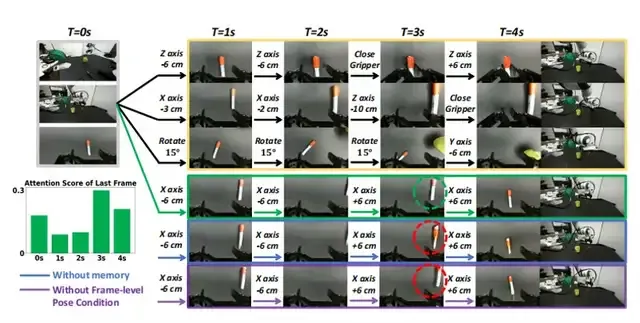
注:上图展示的是Ctrl-World的可控性及其消融实验。不同的动作序列可以在Ctrl-World中以厘米级的精度产生不同的展开结果。移除记忆会导致预测模糊(蓝色),而移除帧级姿势条件会降低控制精度(紫色)。注意力可视化(左侧)在预测(t=4)秒帧时,对具有相同姿势的(t=0)秒帧显示出强烈的注意力,说明了记忆检索的有效性。为了清晰起见,每个动作块都用自然语言表达(例如,“Z轴-6厘米”)。由于空间限制,仅可视化了中间帧的腕部视角。
论文中给出了直观案例:
当机械臂执行不同的空间位移或姿态调整动作时(如沿特定轴的厘米级移动、夹爪开合),Ctrl-World能生成与动作严格对应的预演轨迹,即使是细微的动作差异(如几厘米的位移变化),也能被准确区分和模拟。
定量ablation实验显示,若移除“帧级动作条件”,模型的PSNR会从23.56降至21.20,LPIPS(感知相似度,数值越低越好)从0.091升至0.109,证明该设计是精准控制的核心。
长时预演的“时序漂移”,本质是模型“忘记历史状态”。
Ctrl-World引入“姿态条件记忆检索机制”,通过两个关键步骤解决:
- 稀疏记忆采样:从历史轨迹中以固定步长(如1-2秒)采样k帧(论文中k=7),避免上下文过长导致的计算负担;
- 姿态锚定检索:将采样帧的机械臂姿态信息嵌入视觉token,在预测新帧时,模型会自动检索“与当前姿态相似的历史帧”,以历史状态校准当前预测,避免漂移。

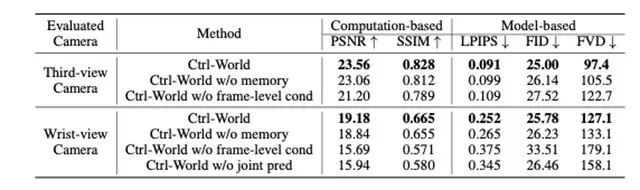
注:上图展示的是Ctrl-World的一致性。由于腕部摄像头的视野在单一轨迹中会发生显著变化,利用多视角信息和记忆检索对于生成一致的腕部视角预测至关重要。绿色框中突出显示的预测是从其他摄像头视角推断出来的,而红色框中的预测则是从记忆中检索得到的。
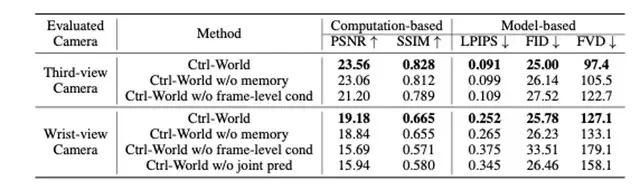
论文实验显示,该机制能让Ctrl-World稳定生成20秒以上的连贯轨迹,时序一致性指标FVD(视频帧距离,数值越低越好)仅97.4,远低于WPE(156.4)和IRASim(138.1)。
ablation实验证明,若移除记忆模块,模型的FVD会从97.4升至105.5,PSNR从23.56降至23.06,验证了记忆机制对长时一致性的关键作用。
团队在DROID机器人平台(含Panda机械臂、1个腕部相机+2个第三方相机)上开展三轮实验测试,从生成质量、评估准确性、策略优化三个维度全面验证CTRL-WORLD的性能:
在10秒长轨迹生成测试中(256个随机剪辑,15步/秒动作输入),CTRL-WORLD在核心指标上全面领先基线模型(WPE、IRASim):
- PSNR:23.56(WPE为20.33,IRASim为21.36),虚拟画面与真实场景的像素相似度提升15%-16%;
- SSIM:0.828(WPE为0.772,IRASim为0.774),物体形状、位置关系的结构一致性显著增强;
- LPIPS:0.091(WPE为0.131,IRASim为0.117),从人类视觉感知看,虚拟与真实画面几乎难以区分;
- FVD:97.4(WPE为156.4,IRASim为138.1),时序连贯性提升29%-38%。
更关键的是,面对训练中未见过的相机布局(如新增顶部视角),CTRL-WORLD能零样本适配,生成连贯多视角轨迹,证明其场景泛化能力。
论文结果显示:
虚拟预演的“指令跟随率”与真实世界的相关系数达0.87(拟合公式y=0.87x-0.04)。
虚拟“任务成功率”与真实世界的相关系数达0.81(y=0.81x-0.11)。
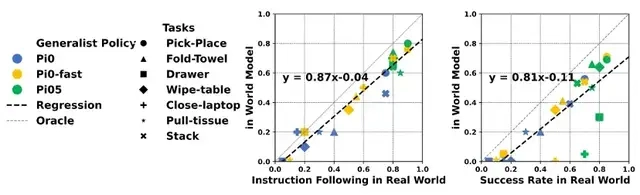
这意味着,研究者无需启动真实机器人,仅通过Ctrl-World的虚拟预演,就能准确判断策略的真实性能,将策略评估周期从“周级”缩短至“小时级”。
Ctrl-World的终极价值在于用虚拟数据改进真实策略。
团队以π₀.₅为基础策略,按以下步骤进行优化(对应论文Algorithm1):
- 虚拟探索:在Ctrl-World中,通过“指令重述”(如将“放手套进盒子”改为“拿起布料放入盒子”)和“初始状态随机重置”,生成400条陌生任务的预演轨迹;
- 筛选高质量数据:由人类标注员筛选出25-50条“成功轨迹”(如准确折叠指定方向的毛巾、抓取异形物体);
- 监督微调:用这些虚拟成功轨迹微调π₀.₅策略。
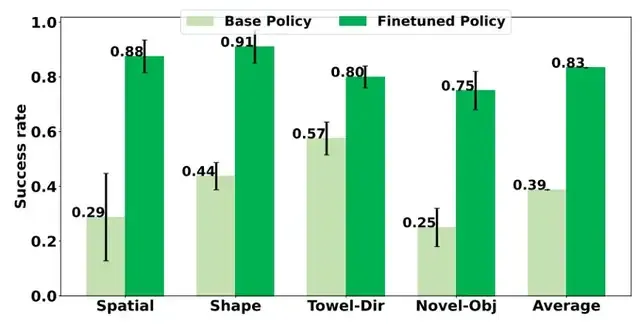
论文给出的细分任务改进数据极具说服力:
- 空间理解任务:识别“左上角物体”、“右下角物体”等指令的成功率,从平均28.75%升至87.5%;
- 形状理解任务:区分“大/小红块”、“大/小绿块”的成功率,从43.74%升至91.25%;
- 毛巾折叠(指定方向):按“左右折叠”、“右左折叠”等指令执行的成功率,从57.5%升至80%;
- 新物体任务:抓取“手套”、“订书机”等未见过物体的成功率,从25%升至75%。
综合所有陌生场景,π₀.₅的任务成功率从38.7%飙升至83.4%,平均提升44.7%——更关键的是,整个过程未消耗任何真实物理资源,成本仅为传统专家数据方法的1/20。
尽管成果显著,团队也坦言CTRL-WORLD仍有改进空间:
首先,复杂物理场景适配不足。
在“液体倾倒”“高速碰撞”等任务中,虚拟模拟与真实物理规律的偏差,主要因模型对重力、摩擦力的建模精度不足。
其次,初始观测敏感性高。
若第一帧画面模糊(如光照过暗),后续推演误差会快速累积。
未来,团队计划从两方面突破——
一方面将视频生成与强化学习结合,让机器人在虚拟世界自主探索最优策略;
另一方面扩大训练数据集(当前基于DROID),加入“厨房油污环境”、“户外光照变化”等复杂场景数据,提升模型对极端环境的适配能力。
总的来说,此前机器人学习依赖“真实交互-数据收集-模型训练”的循环,本质是用物理资源换性能;而CTRL-WORLD构建了“虚拟预演-评估-优化-真实部署”的新闭环,让机器人能通过“想象”高效迭代。
该成果的价值不仅限于实验室。
对工业场景而言,它可降低机械臂调试成本(单条生产线调试周期从1周缩至1天)。
对家庭服务机器人而言,它能快速适配“操作异形水杯”“整理不规则衣物”等个性化任务。
随着视频扩散模型对物理规律建模的进一步精准,未来的CTRL-WORLD有望成为机器人“通用训练平台”,推动人形机器人更快走向开放世界。
论文地址:https://arxiv.org/pdf/2510.10125GitHub链接:https://github.com/Robert-gyj/Ctrl-World


