开源

两个用于科研的开源 AI Agent,改变知识研究的方式
想象一下,如果可以让爱因斯坦、埃隆·马斯克、费曼、史蒂夫·乔布斯、简·古道尔和尤瓦尔·诺亚·赫拉利和你一起合作共同研究并编写研究报告,这是一种什么感受? 我们每天产生的信息比过去一年产生的信息还要多,假如研究人员想在一个小时内访问一万个网站、研究分析数据、并编写报告,这实际上是不可能的。 如今,随着AI 大模型技术的发展,使用AI Agent却可以轻松地做到这一点。

无问芯穹开源全球首款端侧全模态理解模型 Megrez-3B-Omni,支持图像、音频、文本理解
无问芯穹今日宣布,开源无问芯穹端侧解决方案中的全模态理解小模型 Megrez-3B-Omni 和它的纯语言模型版本 Megrez-3B-Instruct。

LG 发布 EXAONE 3.5 开源 AI 模型:长文本处理利器、独特技术有效降低“幻觉”
LG 人工智能研究院本周一(12 月 9 日)发布 EXAONE 3.5 开源 AI 模型,并同步推出面向 LG 员工的企业级 AI 智能体服务 ChatEXAONE。

73页,开源「后训练」全流程!AI2发布高质量Tülu 3系列模型,拉平闭源差距,比肩GPT-4o mini
只进行过「预训练」的模型是没办法直接使用的,存在输出有毒、危险信息的风险,也无法有效遵循人类指令,所以通常还需要进行后训练(post-train),如「指令微调」和「从人类反馈中学习」,以使模型为各种下游用例做好准备。 早期的后训练工作主要遵循InstructGPT等模型的标准方案,如指令调整(instruction tuning)和偏好微调(preference finetuning),不过后训练仍然充满玄学,比如在提升模型编码能力的同时,可能还会削弱模型写诗或遵循指令的能力,如何获得正确的「数据组合」和「超参数」,使模型在获得新知识的同时,而不失去其通用能力,仍然很棘手。 为了解决后训练难题,各大公司都提升了后训练方法的复杂性,包括多轮训练、人工数据加合成数据、多训练算法和目标等,以同时实现专业知识和通用功能,但这类方法大多闭源,而开源模型的性能又无法满足需求,在LMSYS的ChatBotArena上,前50名模型都没有发布其训练后数据。

开源全家桶又添一“元”,腾讯混元大模型公布最新进展
刚刚,腾讯混元大模型公布最新进展:正式上线视频生成能力,这是继文生文、文生图、3D生成之后的又一新里程碑。 与此同时,腾讯开源该视频生成大模型,参数量130亿,是当前最大的视频开源模型。 “用户只需要输入一段描述,即可生成视频,”腾讯混元相关负责人透露,目前的生成视频支持中英文双语输入、多种视频尺寸以及多种视频清晰度。

腾讯版Sora发布即开源!130亿参数,模型权重、推理代码全开放
130亿参数,成为目前参数量最大的开源视频生成模型。 模型权重、推理代码、模型算法等全部上传GitHub与Hugging Face,一点没藏着。 实际效果如何呢?

关于 Meta Llama 3,你知道多少?
2024年,对于人工智能领域来说可谓意义非凡。 继 OpenAI 推出备受赞誉的 GPT-4o mini后,Meta 的 Llama 3.1 模型亦在 . 7月23日 惊艳亮相,再一次掀起了新一轮人工智能热潮。

推理水平对标OpenAI o1!阿里云通义开源最新推理模型QwQ
11月28日,阿里云通义团队发布全新AI推理模型QwQ-32B-Preview,并同步开源。 评测数据显示,预览版本的QwQ,已展现出研究生水平的科学推理能力,在数学和编程方面表现尤为出色,整体推理水平比肩OpenAI o1。 QwQ(Qwen with Questions)是通义千问Qwen大模型最新推出的实验性研究模型,也是阿里云首个开源的AI推理模型。
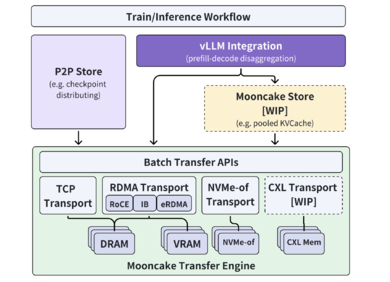
官宣开源 阿里云与清华大学共建AI大模型推理项目Mooncake
2024年6月,国内优质大模型应用月之暗面Kimi与清华大学MADSys实验室(Machine Learning, AI, Big Data Systems Lab)联合发布了以 KVCache 为中心的大模型推理架构 Mooncake。 通过使用以 KVCache 为中心的 PD 分离和以存换算架构,大幅提升大模型应用Kimi智能助手推理吞吐的同时有效降低了推理成本,自发布以来受到业界广泛关注。 近日,清华大学和研究组织9#AISoft,联合以阿里云为代表的多家企业和研究机构,正式开源大模型资源池化项目 Mooncake。

五个基于 LLM 的开源爬虫项目
由于互联网在技术、内容、渠道等方面越来越多样化,并且不断在演变。 传统的爬虫大多时候都要根据网页进行定制开发。 这种道高一尺魔高一丈的循环,意味着要把有限精力投入到无限的变化中,难以动态响应互联网的变化。

一文看尽Meta开源大礼包!全面覆盖图像分割、语音、文本、表征、材料发现、密码安全性等
开源绝对是AI如今发展迅猛的助推剂,而其中的一股重要力量就是来自MetaMeta在人工智能开源界可谓是硕果颇丰,从大模型LLama到图像分割模型Segment Anything,覆盖了各种模态、各种场景,甚至在AI以外的学科,如医学等科学研究进展也都从Meta的开源模型中受益。 最近,Meta发布了一系列新的开源工作,还对已有的开源工作进行了升级迭代,包括 SAM 2.1、句子表征的细化等,开源社区将再迎来一场狂欢! Segment Anything Model 2.1SAM2模型开源以来,总下载量已经超过70万次,在线可用的演示程序也已帮助用户在图像和视频数据中分割了数十万个物体,并且在跨学科(包括医学图像、气象学等研究)中产生了巨大的影响。

炸裂!Anthropic 重磅开源「模型上下文协议」MCP,LLM 应用要变天, AGI真的近了
各位大佬,激动人心的时刻到啦! Anthropic 开源了一个革命性的新协议——MCP(模型上下文协议),有望彻底解决 LLM 应用连接数据难的痛点! 它的目标是让前沿模型生成更好、更相关的响应。

首个可保留情感的音频LLM!Meta重磅开源7B-Spirit LM,一网打尽「音频+文本」多模态任务
在纯文本大模型取得进展的同时,其他模态数据,如语音与文本结合的语言模型(SpeechLMs)也成为了一个热门的研究领域,但现有的模型要么在仅包含语音的数据上进行训练,要么是关注特定任务,如文本转语音(TTS)、自动语音识别(ASR)或翻译,在其他模态数据和任务上的泛化能力十分有限。 在大型语言模型(LLM)性能不断提升的情况下,一个常用的方法是先用ASR模型将语音转录成文本,然后用文本模型来生成新的文本,最后再用TTS模型将文本转换成语音,这种流程的一个显著缺陷就是语音表达性不佳,语言模型无法建模并生成富有表现力的语音数据。 最近,Meta开源了一个基础多模态语言模型Spirit LM,基于一个70亿参数的预训练文本语言模型,交错使用文本和语音数据进行训练,使模型能够自由地混合文本和语音,在任一模态中生成语言内容。

北大等发布多模态版o1!首个慢思考VLM将开源,视觉推理超越闭源模型
北大等出品,首个多模态版o1开源模型来了——代号LLaVA-o1,基于Llama-3.2-Vision模型打造,超越传统思维链提示,实现自主“慢思考”推理。 在多模态推理基准测试中,LLaVA-o1超越其基础模型8.9%,并在性能上超越了一众开闭源模型。 新模型具体如何推理,直接上实例,比如问题是:减去所有的小亮球和紫色物体,剩下多少个物体?
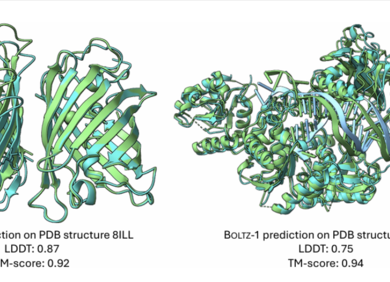
AlphaFold3级性能、开源、可商用,MIT团队推出生物分子预测模型Boltz-1
图示:来自测试集的靶标上的 Boltz-1 的示例预测。 (来源:论文)编辑 | 萝卜皮2024 年 11 月 18 日,麻省理工学院(MIT)的研究人员宣布推出 Boltz-1,这是一个开源模型,旨在准确模拟复杂的生物分子相互作用。 Boltz-1 是第一个完全商业化的开源模型,在预测生物分子复合物的 3D 结构方面达到 AlphaFold3 级精度。

稚晖君后宇树也来玩开源了:机器人操作数据集,采用抱抱脸LeRobot训练测试,网友:泰裤辣!
继稚晖君之后,国内又一家头部机器人公司玩起了开源! 宇树科技,开源Unitree G1机器人操作数据集,包括数据采集、学习算法、数据集和模型,并表示将持续更新。 更令网友意外的是,宇树基于抱抱脸LeRobot开源框架训练并测试。

阿里通义千问开源 Qwen2.5-Coder 全系列模型,号称代码能力追平 GPT-4o
阿里通义千问此前开源了 1.5B、7B 两个尺寸,本次开源带来 0.5B、3B、14B、32B 四个尺寸,覆盖了主流的六个模型尺寸。

AlphaFold3重磅开源,诺奖级AI颠覆世界!GitHub斩获1.8k星,本地即可部署
AlphaFold3源码终于开放了! 六个月前,AlphaFold3横空出世震撼了整个学术界。 AlphaFold的开发人也凭借它在上个月赢得了诺贝尔化学奖。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI绘画
大模型
AI新词
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
智能体
技术
Gemini
英伟达
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
代码
AI for Science
苹果
算法
腾讯
Agent
Claude
芯片
Stable Diffusion
具身智能
xAI
蛋白质
开发者
人形机器人
生成式
神经网络
机器学习
AI视频
3D
RAG
大语言模型
字节跳动
Sora
百度
研究
GPU
生成
工具
华为
AGI
计算
大型语言模型
AI设计
生成式AI
搜索
视频生成
亚马逊
AI模型
DeepMind
特斯拉
场景
深度学习
Transformer
架构
Copilot
MCP
编程
视觉