开源绝对是AI如今发展迅猛的助推剂,而其中的一股重要力量就是来自Meta
Meta在人工智能开源界可谓是硕果颇丰,从大模型LLama到图像分割模型Segment Anything,覆盖了各种模态、各种场景,甚至在AI以外的学科,如医学等科学研究进展也都从Meta的开源模型中受益。

最近,Meta发布了一系列新的开源工作,还对已有的开源工作进行了升级迭代,包括 SAM 2.1、句子表征的细化等,开源社区将再迎来一场狂欢!
Segment Anything Model 2.1
SAM2模型开源以来,总下载量已经超过70万次,在线可用的演示程序也已帮助用户在图像和视频数据中分割了数十万个物体,并且在跨学科(包括医学图像、气象学等研究)中产生了巨大的影响。
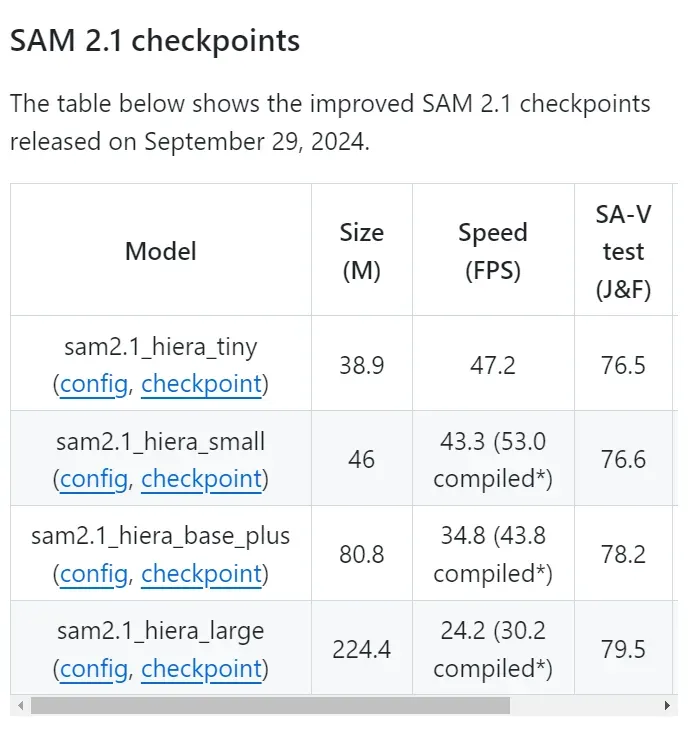
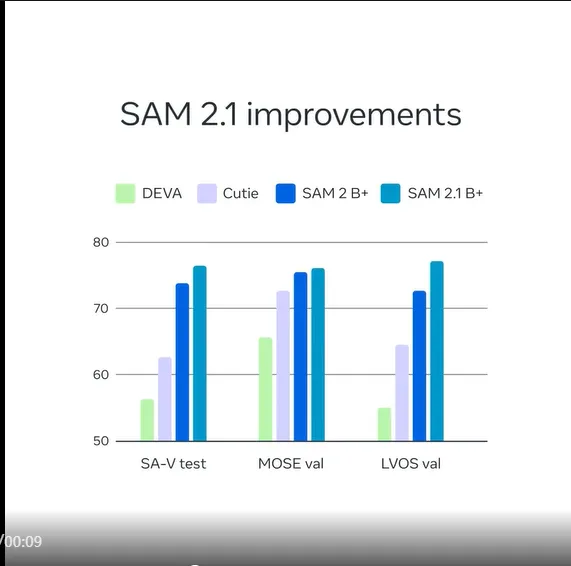
本次Meta更新了Meta Segment Anything Model 2.1 (SAM 2.1)权重,性能更强。
开源链接:https://github.com/facebookresearch/sam2
相比SAM2,研究人员引入了额外的数据增强技术来模拟视觉相似物体和小物体,并且通过在较长的帧序列上训练模型并对「空间」和「物体指向记忆」(object pointer memory)的位置编码进行一些调整,提高了SAM 2的遮挡处理能力(occlusion handling capability)。
研究人员还开源了SAM 2开发者套件,基于SAM 2模型构建下游应用会变得更容易,用户现在也可以使用自己的数据来微调SAM 2的训练代码;页面演示的前端和后端代码也开源了。
Spirit LM:语音+文本的语言模型
大型语言模型经常被用来构建文本到语音的流程:首先通过自动语音识别(ASR)技术将语音转写成文本,然后由大型语言模型(LLM)合成文本,最终再通过文本到语音(TTS)技术将文本转换为语音。
但这个过程可能会影响语音的表达性,使得模型在理解、生成带表达的语音上有所欠缺。
为了解决这个限制,研究人员构建了Spirit LM,也是首个Meta开源的多模态语言模型,能够自由地混合文本和语音;通过在语音和文本数据集上使用逐词交错的方法进行训练,实现了跨模态生成。

论文链接:https://arxiv.org/abs/2402.05755
研究人员开发了两个版本的Spirit LM,以展示文本模型的生成语义能力和语音模型的表达能力:基础版(Base)使用音素标记来模拟语音,而表达版(Expressive)使用音调和风格标记来捕捉关于语调的信息,比如是兴奋、愤怒还是惊讶,然后生成反映这种语调的语音。
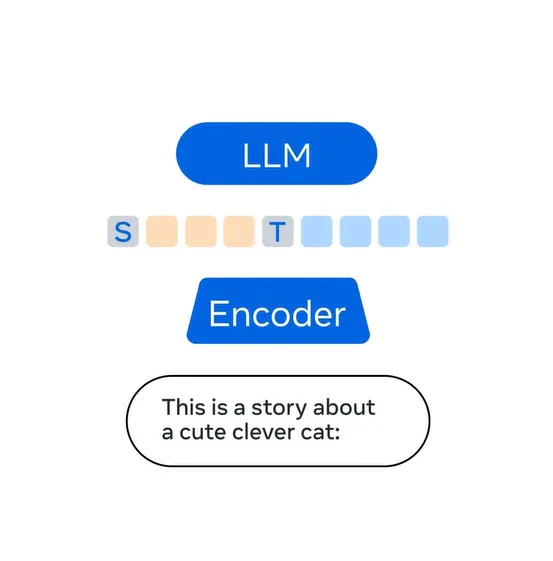
Spirit LM能够生成听起来更自然的语音,并且有能力跨模态学习新任务,比如自动语音识别、文本到语音和语音分类。
Layer Skip:加速生成时间
大型语言模型已经在各个行业和用例中得到了广泛应用,但需要非常高的计算速度和内存量,运行成本非常高。
为了应对这些挑战,Meta引入一种端到端的解决方案层跳过(Layer Skip),可以在不依赖专用硬件或软件的情况下,加速新数据上的LLM生成时间:通过执行模型的部分层,并利用后续层进行验证和修正,来加速LLMs的运行。

论文链接:https://arxiv.org/pdf/2404.16710
代码链接:https://github.com/facebookresearch/LayerSkip
研究人员开源了层跳过的推理代码和微调检查点,包括Llama 3、Llama 2和Code Llama,这些模型已经通过层跳过训练方法进行了优化,显著提高了早期层退出的准确性,层跳过的推理实现可以提升1.7倍模型性能。
层跳过检查点的一个主要特点是在早期层退出和跳过中间层时的鲁棒性,以及各层之间激活的一致性,这种特性为优化和可解释性方面的创新研究铺平了道路。
Salsa:验证后量子密码标准的安全性
在保护数据的安全领域上,密码学研究必须领先于攻击手段。
Meta此次开源的方法Salsa,能够攻击和破解NIST标准中的稀疏秘密(sparse secrets)Krystals Kyber,使研究人员能够对基于人工智能的攻击进行基准测试,并将其与现在以及将来的新攻击手段进行对比。

论文链接:https://arxiv.org/pdf/2408.00882v1
代码链接:https://github.com/facebookresearch/LWE-benchmarking
国家标准技术研究所(NIST)采用的行业标准,「基于格(lattice)的密码学」建立在「带误差的学习」(LWE)的难题之上。
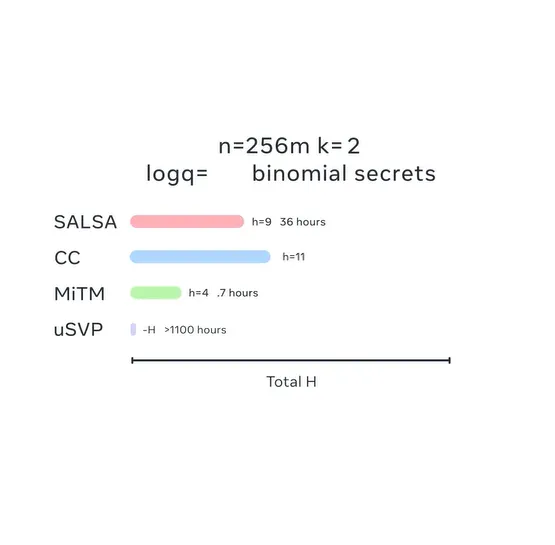
这种难题假设,如果只提供与随机向量有噪声的内积,那么学习一个秘密向量是非常困难的,此前已经有研究人员展示了针对这种方法的机器学习攻击。
Meta Lingua:通过高效的模型训练加速研究
Meta Lingua 是一个轻量级且自包含的代码库,可以大规模训练语言模型。
该项目提供了一个研究友好的环境,使得将概念转化为实际实验变得更加容易,并强调简单性和可重用性以加速研究,平台高效且可定制,研究人员能够以最小的设置和技术负担来快速测试想法。

代码链接:https://github.com/facebookresearch/lingua
为了实现这一点,研究人员做了几个设计选择,确保代码既模块化又自包含,同时保持高效,其中利用了PyTorch中的多个特性,在保持灵活性和性能的同时,使代码更易于安装和维护。
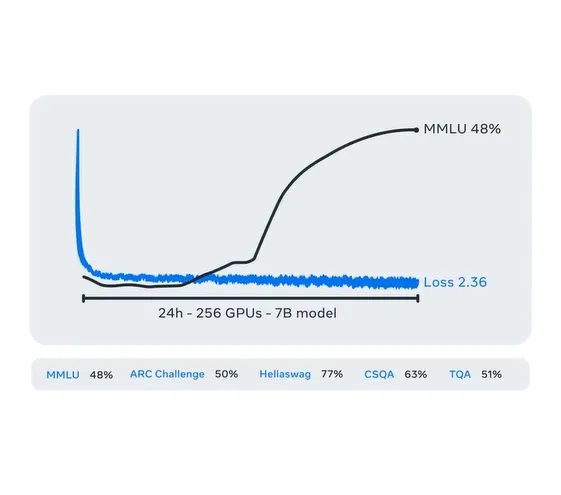
研究人员可以更专注于工作本身,让Lingua平台来负责高效的模型训练和可复现的研究。
Meta Open Materials 2024:促进无机材料发现
传统上,发现推动技术进步的新材料可能需要数十年的时间,但人工智能辅助材料发现可能会彻底改变这一领域,并大大加快发现流程。
Meta最近开源了Open Materials 2024数据集和模型,在Matbench-Discovery排行榜上名列前茅,有望通过开放和可复现的研究进一步推动人工智能加速材料发现的突破。
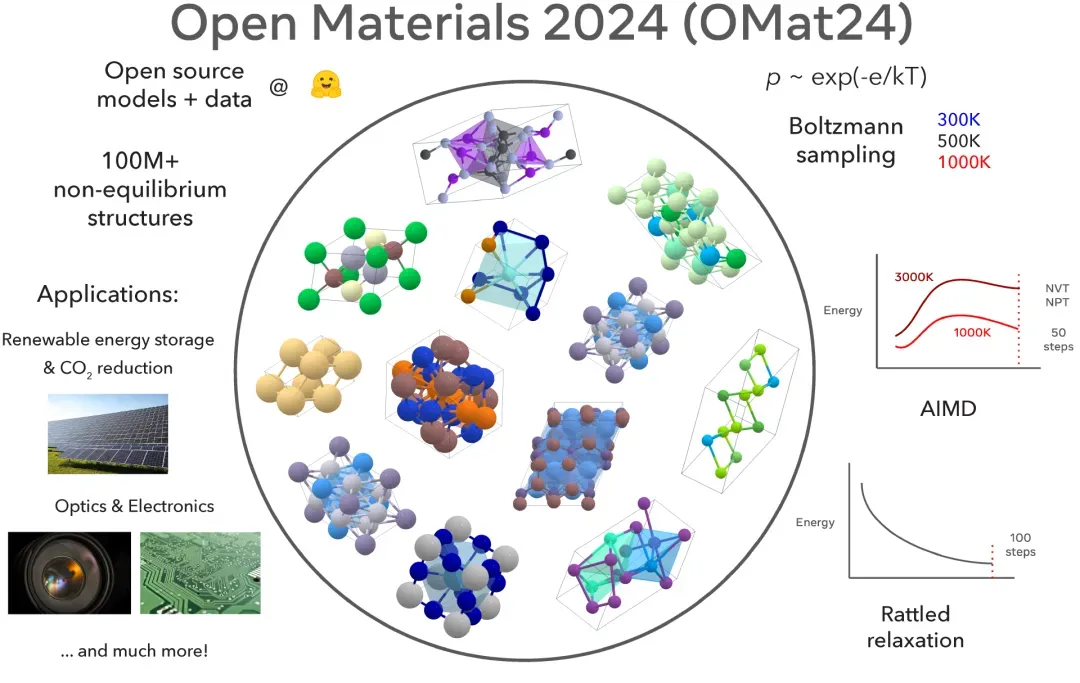
代码链接:https://github.com/FAIR-Chem/fairchem
模型链接:https://huggingface.co/fairchem/OMAT24
数据链接:https://huggingface.co/datasets/fairchem/OMAT24
目前最佳的材料发现模型是基于开源人工智能社区的基础研究构建的封闭模型,而Open Materials 2024提供了基于1亿个训练样本的开源模型和数据,也是最大的开放数据集之一,为材料发现和人工智能研究社区提供了一个有竞争力的开源选择。
Meta Open Materials 2024现在公开可用,并将赋予人工智能和材料科学研究社区加速无机材料发现的能力,并缩小领域内开放和专有模型之间的差距。
Mexma:改进句子表征的token级目标
目前,预训练的跨语言句子编码器通常只使用句子级别的目标进行训练。这种做法可能会导致信息的丢失,特别是对于token级别的信息,这最终会降低句子表示的质量。
Mexma是一个预训练的跨语言句子编码器,通过在训练过程中结合token和句子级别的目标,其性能也超越了以往的方法。

论文链接:https://arxiv.org/pdf/2409.12737
以前训练跨语言句子编码器的方法仅通过句子表示来更新编码器,通过同时使用token级别的目标来更好地更新编码器,从而在这方面进行了改进。
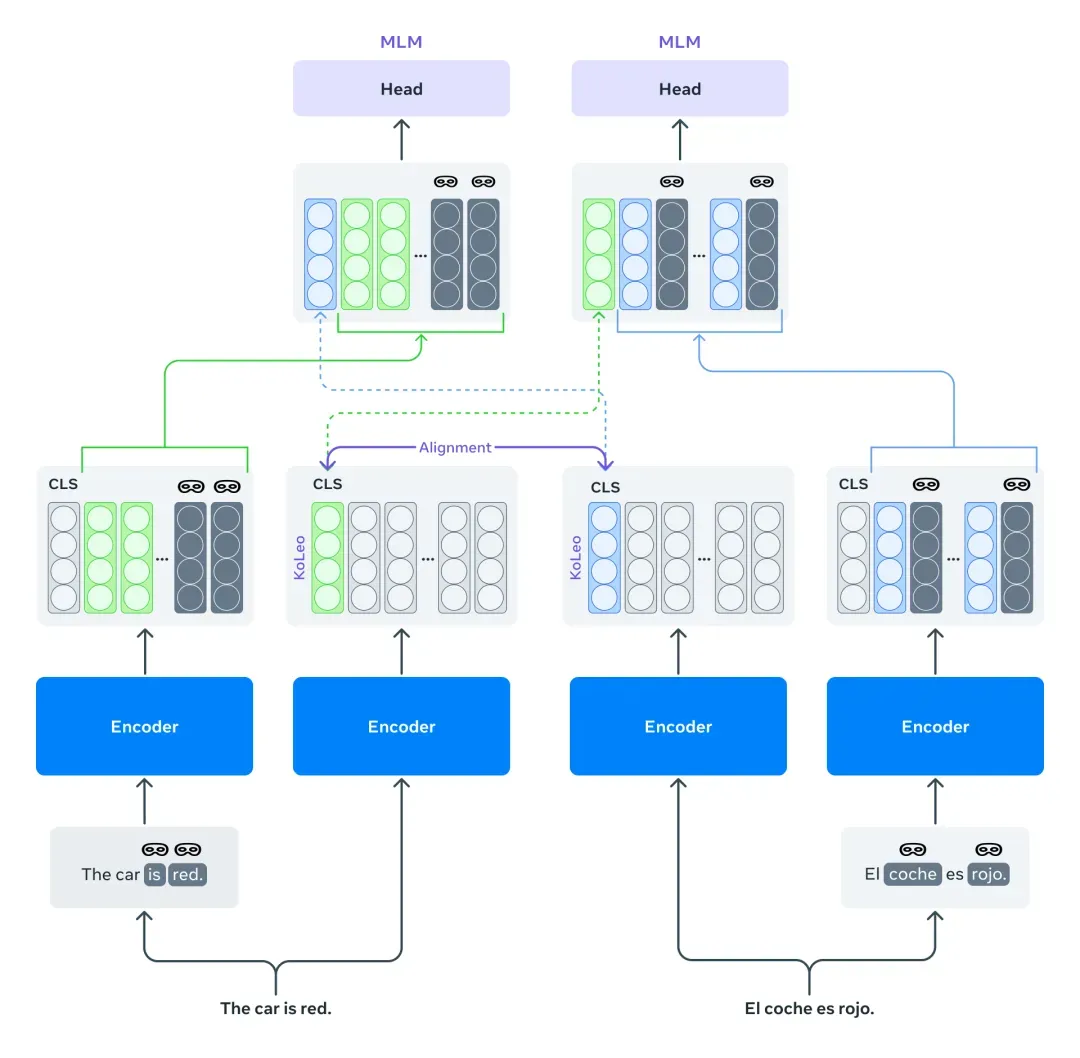
研究人员希望研究社区能够从使用Mexma作为句子编码器中受益,目前支持80种语言,所有语言的句子表示都经过对齐,在挖掘包含两种文本的语言数据时,Mexma能够更准确地识别和比较不同语言中的信息,并且在其他下游任务,如句子分类上表现良好。
Self-Taught Evaluator:生成奖励模型
研究人员推出了自学评估器(Self-Taught Evaluator),可以用于生成合成偏好数据以训练奖励模型,而无需依赖人工标注。
这种方法生成对比的模型输出,并训练一个作为评委的大型语言模型(LLM-as-a-Judge)以生成用于评估和最终判断的推理痕迹,并通过迭代自我改进方案进行优化。

论文链接:https://arxiv.org/abs/2408.02666
研究人员发布了一个经过直接偏好优化训练的模型,该生成式奖励模型在RewardBench上表现强大,但在训练数据创建中没有使用任何人工标注。
其性能表现超越了更大的模型或使用人工标注标签的模型,例如GPT-4、Llama-3.1-405B-Instruct和Gemini-Pro,也可作为AlpacaEval排行榜上的评估器之一,在人类一致率方面名列前茅,同时比默认的GPT-4评估器快约7到10倍。
自从发布以来,人工智能社区已经接受了这种合成数据方法,并用来训练表现优异的奖励模型。