130亿参数,成为目前参数量最大的开源视频生成模型。模型权重、推理代码、模型算法等全部上传GitHub与Hugging Face,一点没藏着。

实际效果如何呢?
不瞒你们说,我真的看见一只大熊猫,在跳广场舞、吃火锅、打麻将,请看VCR:



到底是来自四川的猫!
目前该模型已上线腾讯元宝APP,用户可在AI应用中的“AI视频”板块申请试用。
API同步开放测试,开发者可通过腾讯云接入。
腾讯混元视频生成主打四大特点:
- 超写实画质,模型生成的视频内容具备高清质感、真实感,可用于工业级商业场景例如广告宣传、创意视频生成等商业应用。
- 高语义一致,用户可以进行细致的刻画,例如生成主体的细节,人物概念的组合等。模型可以准确的表达出文本的内容。
- 运动画面流畅,可生成大幅度的合理运动,运动镜头流畅、符合物理规律,不易变形。
- 原生镜头转换,模型原生具备自动生成多视角同主体的镜头切换画面,增强画面叙事感。
那么实际表现能否符合描述?下面结合实例一一拆解。
实测腾讯首个文生视频模型
首先是冲浪题材,涉及到画面大幅度运动,水的物理模拟等难点。
提示词中还特别指定了摄像头的运动,腾讯混元表现出流畅运镜的能力,只是在“最后定格在…”这个要求上稍显不足。
提示词:超大海浪,冲浪者在浪花上起跳,完成空中转体。摄影机从海浪内部穿越而出,捕捉阳光透过海水的瞬间。水花在空中形成完美弧线,冲浪板划过水面留下轨迹。最后定格在冲浪者穿越水帘的完美瞬间。

镜子题材,考验模型对光影的理解,以及镜子内外主体运动是否能保持一致。
提示词中的白床单元素又加大了难度,涉及到的布料模拟,也符合物理规律。
不过人们想象中的幽灵一般没有脚,AI似乎没学到,又或者是跳舞涉及大量腿部动作,产生了冲突。
穿着白床单的幽灵面对着镜子。镜子中可以看到幽灵的倒影。幽灵位于布满灰尘的阁楼中,阁楼里有老旧的横梁和被布料遮盖的家具。阁楼的场景映照在镜子中。幽灵在镜子前跳舞。电影氛围,电影打光。

接下来是腾讯混元视频生成主推的功能之一,在画面主角保持不变的情况下自动切镜头,据了解是业界大部分模型所不具备的能力。
一位中国美女穿着汉服,头发飘扬,背景是伦敦,然后镜头切换到特写镜头。

再来一个综合型的复杂提示词,对主角外貌、动作、环境都有细致描述,画面中还出现其他人物,腾讯混元表现也不错。
特写镜头拍摄的是一位60多岁、留着胡须的灰发男子,他坐在巴黎的一家咖啡馆里,沉思着宇宙的历史,他的眼睛聚焦在画外走动的人们身上,而他自己则基本一动不动地坐着,他身穿羊毛大衣西装外套,内衬系扣衬衫,戴着棕色贝雷帽和眼镜,看上去很有教授风范,片尾他露出一丝微妙的闭嘴微笑,仿佛找到了生命之谜的答案,灯光非常具有电影感,金色的灯光,背景是巴黎的街道和城市,景深,35毫米电影胶片。

最后附上来自官方的写prompt小tips:
- 用法1:提示词=主体+场景+运动
- 用法2:提示词=主体(主体描述)+场景(场景描述)+运动(运动描述)+(镜头语言)+(氛围描述)+(风格表达)
- 用法3:提示词=主体+场景+运动+(风格表达)+(氛围描述)+(运镜方式)+(光线)+(景别)
- 多镜头生成:提示词=[场景1]+镜头切换到[场景2]
- 两个动作生成:提示词=[主体描述]+[动作描述]+[然后、过了一会等连接词]+[动作描述2]
怎么样,你学会了吗?
更多腾讯混元生成的视频,以及与Sora同提示词PK,还可以看看量子位在内测阶段的尝试。
最大的开源视频生成模型。
看完效果,再看看技术层面有哪些亮点。
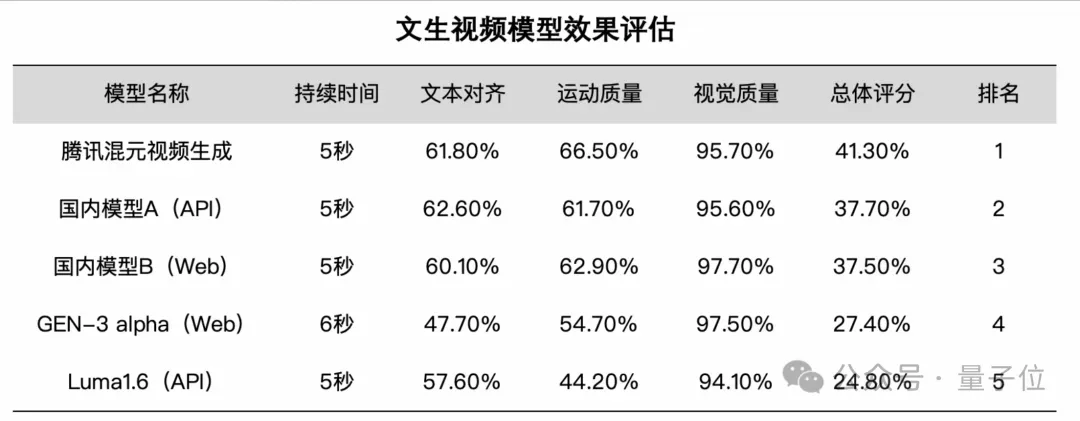
首先从官方评估结果看,混元视频生成模型在文本视频一致性、运动质量和画面质量多个维度效果领先。
然后从目前公开资料看,腾讯混元视频生成模型还有三个亮点。
1、文本编码器部分,已经适配多模态大模型
当下行业中多数视觉生成模型的文本编码器,适配的主要是上一代语言模型,如OpenAI的CLIP和谷歌T5及各种变种。
腾讯在开源图像生成模型Hunyuan-DiT中适配的是T5和CLIP的结合,这次更进一步,直接升级到了新一代多模态大语言模型(Multimodal Large Language Model)。
由此能够获得更强大的语义跟随能力,体现在能够更好地应对画面中存在的多个主体,以及完成指令中更多的细节。
2、视觉编码器部分,支持混合图片/视频训练,提升压缩重建性能
视频生成模型中的视觉编码器,在压缩图片/视频数据,保留细节信息方面起着关键作用。
混元团队自研了3D视觉编码器支持混合图片/视频训练,同时优化了编码器训练算法,显著提升了编码器在快速运行、纹理细节上的压缩重建性能,使得视频生成模型在细节表现上,特别是小人脸、高速镜头等场景有明显提升。
3、从头到尾用full attention(全注意力)的机制,没有用时空模块,提升画面流畅度。
混元视频生成模型采用统一的全注意力机制,使得每帧视频的衔接更为流畅,并能实现主体一致的多视角镜头切换。
与“分离的时空注意力机制”分别关注视频中的空间特征和时间特征,相比之下,全注意力机制则更像一个纯视频模型,表现出更优越的效果。
更多细节,可以参见完整技术报告~
官网:https://aivideo.hunyuan.tencent.com
代码:https://github.com/Tencent/HunyuanVideo
模型:https://huggingface.co/tencent/HunyuanVideo
技术报告:https://github.com/Tencent/HunyuanVideo/blob/main/assets/hunyuanvideo.pdf


