开源
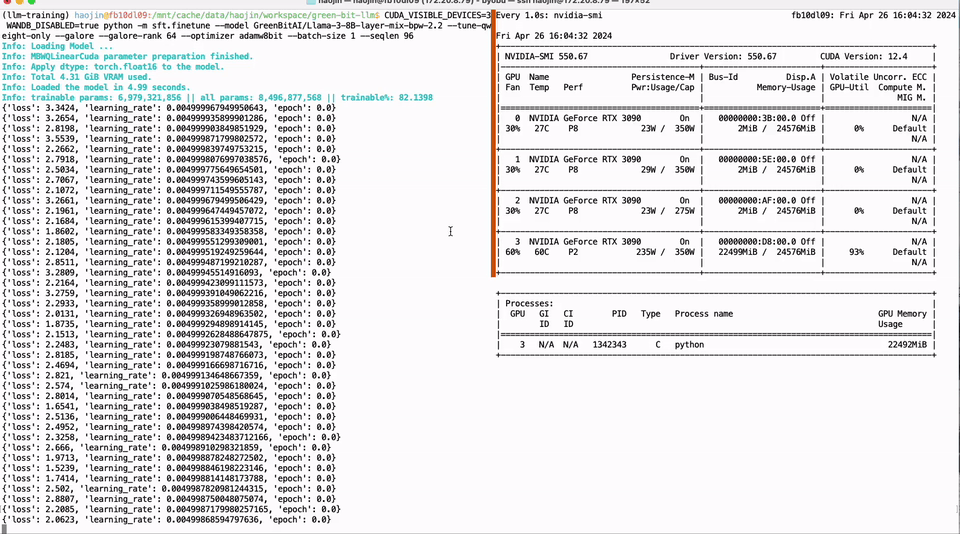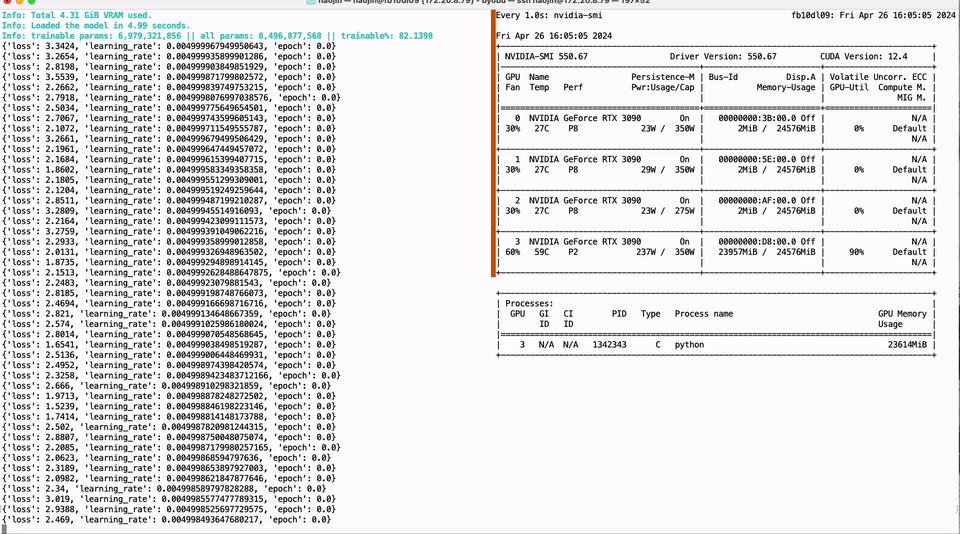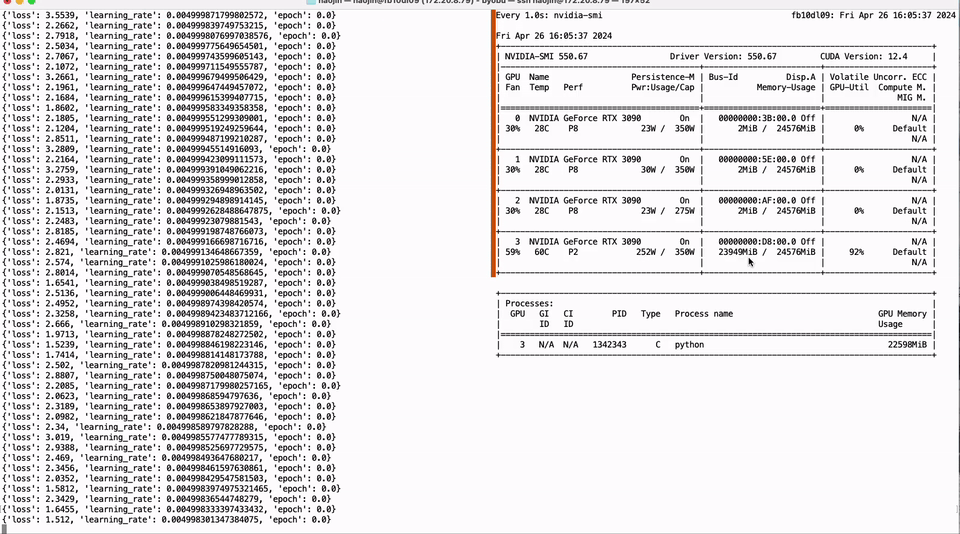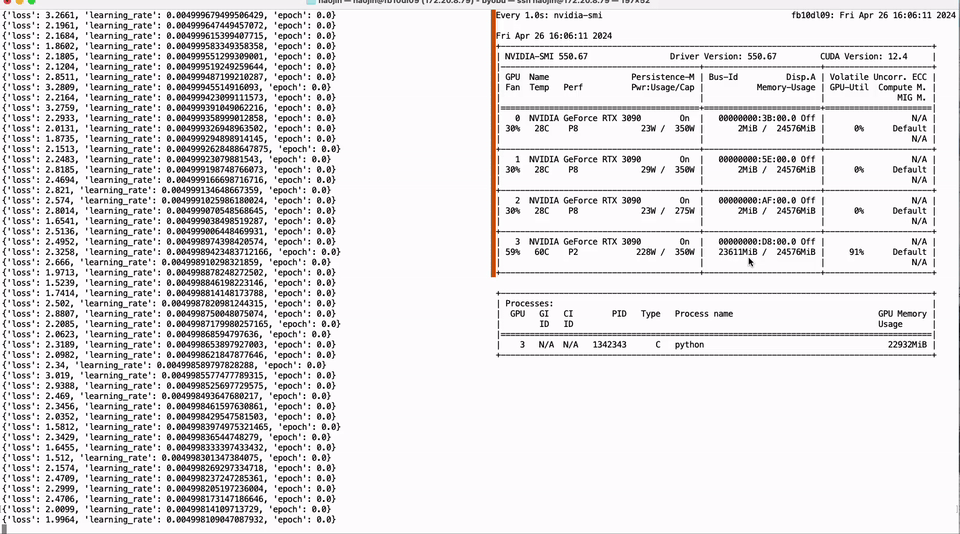
只需单卡RTX 3090,低比特量化训练就能实现LLaMA-3 8B全参微调
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。
投稿邮箱:[email protected];[email protected]

WOT大会日程上线:我们找来数十位大模型实践企业现身说法
这两天的技术圈里,估计大家都在摩拳擦掌等待体验OpenAI的GPT-4o(o为Omni缩写,意为“全能”)有多“全能”吧。我们无意给市场泼冷水,只是要提醒大家,想要让大模型真正落地,市场的热,并不意味着应用实践的成熟。尤其在企业级场景中,为什么大模型落地理想很丰满现实很骨感?为什么很少有企业能把大模型用在核心业务中?是不想用、还是用不好?在即将于6月21-22日在北京召开的WOT全球技术创新大会上,经过持续数月的发掘、走访、调研,我们找来了数十位已经在大模型应用上起跑并领先半个身位的实践企业,力求给你启发和答案。倾

对话零一万物:大模型产品要找到 TC-PMF
上次零一万物(以下简称“零一”)开发布会还是在 2023 年 11 月,宣布成立后的模型首秀:发布中英双语大模型“Yi”,并将其开源。 这一次,时隔半年,零一不仅将基座模型卷到千亿量级,甚至还直接拿出一款 C 端新品“万知”,零一万物创始人李开复称其为“AI-First 版 office”。 在模型层,零一发布了千亿参数的 Yi-Large 闭源模型,在第三方评测基准斯坦福大学的英语排行 AlpacaEval 2.0上,Yi-Large 可与 GPT-4 比肩(如下图所示);并全面升级了开源模型系列 Yi-1.5,分为 34B、9B、6B三个版本,且提供了 Yi-1.5-Chat 微调模型可供开发者选择。

别再说国产大模型技术突破要靠 Llama 3 开源了
Meta 表示,Llama 3 已经在多种行业基准测试上展现了最先进的性能,提供了包括改进的推理能力在内的新功能,是目前市场上最好的开源大模型。 根据Meta的测试结果,Llama 3 8B模型在语言(MMLU)、知识(GPQA)、编程(HumanEval)等多项性能基准上均超过了Gemma 7B和Mistral 7B Instruct,70B 模型则超越了名声在外的闭源模型 Claude 3的中间版本 Sonnet,和谷歌的 Gemini Pro 1.5 相比三胜两负。 Meta还透露,Llama 3的 400B 模型仍在训练中。

苹果发布 OpenELM,基于开源训练和推理框架的高效语言模型
在 WWDC24 之前,苹果在 Hugging Face 平台上发布了一个“具有开源训练和推理框架的高效语言模型”,名为 OpenELM。当然,这是一项开源语言模型,其源码及预训练的模型权重和训练配方可在苹果 Github 库中获取。IT之家将官方简介翻译如下:大型语言模型的可重复性和透明性对于推进开放研究、确保结果的可信度以及调查数据和模型偏差以及潜在风险至关重要。为此,我们发布了 OpenELM,一个最先进的开源语言模型。OpenELM 使用分层缩放策略,可以有效地分配 Transformer 模型每一层的参数

Meta 发布 Llama 3,号称是最强大的开源大语言模型
感谢Meta 公司今天发布新闻稿,宣布推出下一代大语言模型 Llama 3,共有 80 亿和 700 亿参数两种版本,号称是最强大的开源大语言模型。Meta 声称,Llama 3 的性能优于 Claude Sonnet、Mistral Medium 和 GPT-3.5,IT之家附上 Llama 3 的主要特点如下:向所有人开放:Meta 开源 Llama 3 的 80 亿参数版本,让所有人都能接触最前沿的人工智能技术。全球各地的开发人员、研究人员和好奇心强的人都可以进行游戏、构建和实验。更聪明、更安全:Llama

中国电信开源 TeleChat-12B 星辰语义大模型,年内开源千亿级参数大模型
感谢中国电信已开源 120 亿参数 TeleChat-12B 星辰语义大模型,还表示将于年内开源千亿级参数大模型。相较 1 月开源的 7B 版本,12 版版本在内容、性能和应用等方面整体效果提升 30%,其中多轮推理、安全问题等领域提升超 40%。据介绍,TeleChat-12B 将 7B 版本 1.5T 训练数据提升至 3T,优化数据清洗、标注策略,持续构建专项任务 SFT (监督微调) 数据,优化数据构建规范,大大提升数据质量;同时,基于电信星辰大模型用户真实回流数据,优化奖励模型和强化学习模型,有效提升模型问

百度李彦宏称开源 AI 模型会越来越落后
感谢百度创始人、董事长兼 CEO 李彦宏今日在 Create 2024 百度 AI 开发者大会上表示,开源模型会越来越落后。李彦宏介绍,因为基础模型文心 4.0 可以根据需要,兼顾效果、响应速度、推理成本等各种考虑,剪裁出适合各种场景的更小尺寸模型,并且支持精调和 post pretrain。这样通过降维剪裁出来的模型,比直接用开源模型调出来的模型,同等尺寸下,效果明显更好;同等效果下,成本明显更低,“所以开源模型会越来越落后”。李彦宏还发布了文心大模型 4.0 的工具版,文心大模型的算法训练效率号称提升到了原来的
360 智脑 7B 参数大模型开源,支持 50 万字长文本输入
感谢360 公司日前在 GitHub 上开源了 360 智脑 7B(70 亿参数模型)。360 智脑大模型采用 3.4 万亿 Tokens 的语料库训练,以中文、英文、代码为主,开放 4K、32K、360K 三种不同文本长度。360 表示,360K(约 50 万字)是当前国产开源模型文本长度最长的。360 表示,他们在 OpenCompass 的主流评测数据集上验证了模型性能,包括 C-Eval、AGIEval、MMLU、CMMLU、HellaSwag、MATH、GSM8K、HumanEval、MBPP、BBH、L

10 秒总结 YouTube 视频,原阿里首席 AI 科学家贾扬清打造浏览器插件 Elmo
原阿里首席 AI 科学家贾扬清在 X(推特)上分享了插件 Elmo,该插件能在 10 秒内总结 Google Next 主题演讲,生成一句话概括、摘要、主要观点。该插件由贾扬清去年创办的 AI 公司 Lepton AI 打造。贾扬清表示,Elmo 采用了数据公司 Databricks 推出的开源大模型 DBRX。据悉,DBRX 具有 1320 亿个参数,采用 MoE 架构,在性能上超过了 GPT-3.5 和其他一些开源模型。经过IT之家的测试,时长达 1 小时 22 分的苹果 2023 秋季发布会,Elmo 仅用时

阿里通义千问开源 320 亿参数模型,已实现 7 款大语言模型全开源
感谢4 月 7 日,阿里云通义千问开源 320 亿参数模型 Qwen1.5-32B。IT之家注意到,通义千问此前已开源 5 亿、18 亿、40 亿、70 亿、140 亿和 720 亿参数 6 款大语言模型。此次开源的 320 亿参数模型,将在性能、效率和内存占用之间实现更理想的平衡。例如,相比通义千问 14B 开源模型,32B 在智能体场景下能力更强;相比通义千问 72B 开源模型,32B 的推理成本更低。通义千问团队希望 32B 开源模型能为企业和开发者提供更高性价比的模型选择。目前,通义千问共开源了 7 款大语
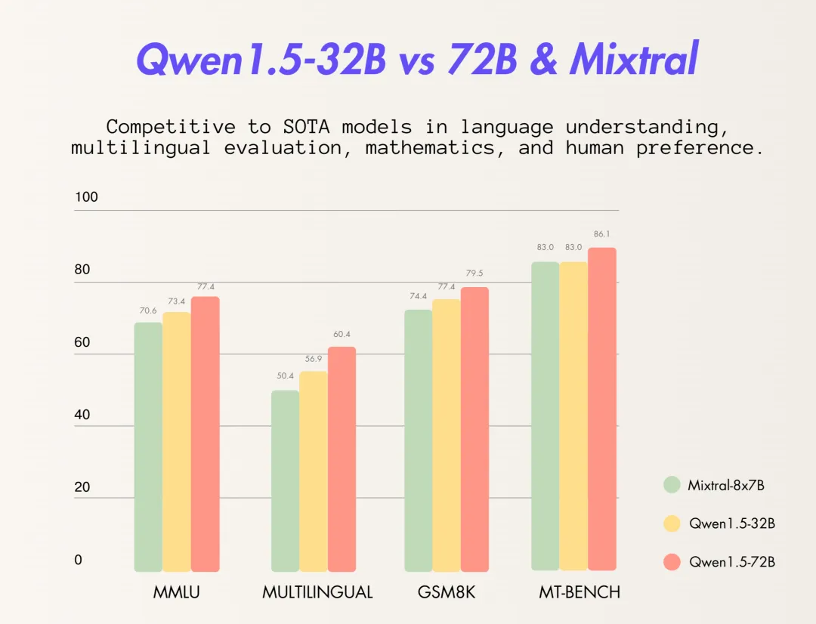
通义千问开源320亿参数模型,已实现7款大语言模型全开源
4月7日消息,阿里云通义千问开源320亿参数模型Qwen1.5-32B,可最大限度兼顾性能、效率和内存占用的平衡,为企业和开发者提供更高性价比的模型选择。目前,通义千问共开源了7款大语言模型,在海内外开源社区累计下载量突破300万。通义千问此前已开源5亿、18亿、40亿、70亿、140亿和720亿参数的6款大语言模型并均已升级至1.5版本,其中,几款小尺寸模型可便捷地在端侧部署,720亿参数模型则拥有业界领先的性能,多次登上HuggingFace等模型榜单。此次开源的320亿参数模型,将在性能、效率和内存占用之间实

元象首个MoE大模型开源:4.2B激活参数,效果堪比13B模型
元象发布XVERSE-MoE-A4.2B大模型 , 采用业界最前沿的混合专家模型架构 (Mixture of Experts),激活参数4.2B,效果即可媲美13B模型。该模型全开源,无条件免费商用,让海量中小企业、研究者和开发者可在元象高性能“全家桶”中按需选用,推动低成本部署。GPT3、Llama与XVERSE等主流大模型发展遵循规模理论(Scaling Law), 在模型训练和推理的过程中,单次前向、反向计算时,所有参数都被激活,这被称为稠密激活 (densely activated)。 当 模型规模增大时,

Databricks 推出 1320 亿参数大语言模型 DBRX,号称“现阶段最强开源 AI”
Databricks 近日在推出了一款通用大语言模型 DBRX,号称是“目前最强开源 AI”,据称在各种基准测试中都超越了“市面上所有的开源模型”。IT之家从官方新闻稿中得知,DBRX 是一个基于 Transformer 的大语言模型,采用 MoE(Mixture of Experts)架构,具备 1320 亿个参数,并在 12T Token 的源数据上进行预训练。研究人员对这款模型进行测试,相较于市场上已有的 LLaMA2-70B、Mixtral、Grok-1 等开源模型,DBRX 在语言理解(MMLU)、程式设

周鸿祎自称“开源信徒”:宣布将开源 360 智脑 7B 模型,支持 50 万字长文本输入
感谢360 创始人周鸿祎近日透露即将开源 360 智脑 7B(70 亿参数模型),支持 360k(50 万字)长文本输入。周鸿祎表示,前段时间大模型行业卷文本长度,100 万字“很快将是标配”。“我们打算将这个能力开源,大家没必要重复造轮子,定为 360k 主要是为了讨个口彩。”他还自称“开源的信徒”,信奉开源的力量。据介绍,360 智脑长文本能力已入驻大模型产品“360AI 浏览器”。周鸿祎还谈到了小模型的优势:其认为小模型速度快、用户体验也好,单机单卡就能跑,具备更高的性价比。目前,360AI 浏览器已向用户免

开源大模型王座再易主,1320亿参数DBRX上线,基础、微调模型都有
「太狂野了」。这是迄今为止最强大的开源大语言模型,超越了 Llama 2、Mistral 和马斯克刚刚开源的 Grok-1。本周三,大数据人工智能公司 Databricks 开源了通用大模型 DBRX,这是一款拥有 1320 亿参数的混合专家模型(MoE)。DBRX 的基础(DBRX Base)和微调(DBRX Instruct)版本已经在 GitHub 和 Hugging Face 上发布,可用于研究和商业用途。人们可以自行在公共、自定义或其他专有数据上运行和调整它们,也可以通过 API 的形式使用。基础版::

号称全球最强开源 AI 模型,DBRX 登场:1320 亿参数,语言理解、编程能力等均超 GPT-3.5
初创公司 Databricks 近日发布公告,推出了开源 AI 模型 DBRX,声称是迄今为止全球最强大的开源大型语言模型,比 Meta 的 Llama 2 更为强大。DBRX 采用 transformer 架构,包含 1320 亿参数,共 16 个专家网络组成,每次推理使用其中的 4 个专家网络,激活 360 亿参数。Databricks 在公司博客文章中介绍,在语言理解、编程、数学和逻辑方面,对比 Meta 公司的 Llama 2-70B、法国 Mistral AI 公司的 Mixtral 以及马斯克旗下 xA

2024全球开发者先锋大会首日顺利召开
3月23日,“2024全球开发者先锋大会”(GDC)在上海徐汇盛大开幕。大会以“模速空间——开发者的模力之源”为主题,促进全球范围内最尖端技术、最热门议题和最先锋人才的深入交流与对话,以上海模速空间创新生态社区为抓手,不断优化生态环境,引导全球顶尖人才向上海汇聚,助推上海成为高科技产业高地。从GAIDC到GDC,今年“开发者”的范畴从AI扩展到整个技术领域,涵盖数字孪生、人工智能、5G、机器人、区块链、VR/AR、边缘计算、仿真等一系列新一代信息技术。通过开发者生态持续运营,让人才引领科技创新,让科技吸引金融助力,
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI绘画
大模型
AI新词
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
智能体
技术
Gemini
英伟达
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
代码
AI for Science
苹果
算法
腾讯
Agent
Claude
芯片
Stable Diffusion
具身智能
xAI
蛋白质
开发者
人形机器人
生成式
神经网络
机器学习
AI视频
3D
RAG
大语言模型
字节跳动
Sora
百度
研究
GPU
生成
工具
华为
AGI
计算
大型语言模型
AI设计
生成式AI
搜索
视频生成
亚马逊
AI模型
DeepMind
特斯拉
场景
深度学习
Transformer
架构
Copilot
MCP
编程
视觉