在纯文本大模型取得进展的同时,其他模态数据,如语音与文本结合的语言模型(SpeechLMs)也成为了一个热门的研究领域,但现有的模型要么在仅包含语音的数据上进行训练,要么是关注特定任务,如文本转语音(TTS)、自动语音识别(ASR)或翻译,在其他模态数据和任务上的泛化能力十分有限。
在大型语言模型(LLM)性能不断提升的情况下,一个常用的方法是先用ASR模型将语音转录成文本,然后用文本模型来生成新的文本,最后再用TTS模型将文本转换成语音,这种流程的一个显著缺陷就是语音表达性不佳,语言模型无法建模并生成富有表现力的语音数据。
最近,Meta开源了一个基础多模态语言模型Spirit LM,基于一个70亿参数的预训练文本语言模型,交错使用文本和语音数据进行训练,使模型能够自由地混合文本和语音,在任一模态中生成语言内容。

项目主页:https://speechbot.github.io/spiritlm/
论文链接:https://arxiv.org/pdf/2402.05755
代码链接:https://github.com/facebookresearch/spiritlm
开源链接:https://huggingface.co/spirit-lm/Meta-spirit-lm
将语音和文本序列拼接成一条token流,并使用一个小型的、自动整理(automatically-curated)的语音-文本平行语料库,采用逐词交错的方法进行训练。
Spirit LM有两个版本:基础版(Base)使用语音音素单元(HuBERT),表达版(Expressive)还额外使用音高和风格单元来模拟表达性,以增强模型在生成语音时的表现力,也就是说模型不仅能够理解和生成基本的语音和文本,还能在表达情感和风格方面表现得更加丰富和自然。
对于两个版本的模型,文本都使用子词BPE标记进行编码,最终得到的模型既展现了文本模型的语义能力,也具备语音模型的表达能力;模型还能够在少量样本的情况下跨模态学习新任务(例如自动语音识别、文本转语音、语音分类)。
不过需要注意的是,和其他预训练模型一样,Sprit LM也可能会生成一些不安全的内容,所有基于该技术的应用都需要进行额外的安全测试和调整。
Spirit LM
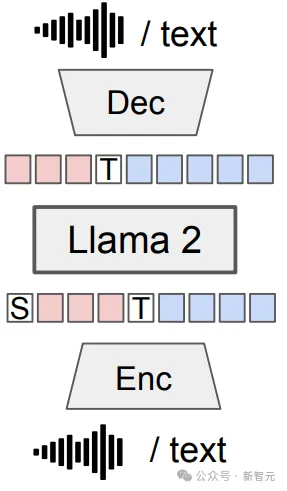
模型的架构比较简单,训练过程就是基本的「预测下一个词」,不过「词」是通过编码器从语音或文本中提取的,然后通过解码器以原来的模态进行重新呈现;训练数据包括三种:仅包含文本的序列、仅包含语音的序列以及交错的语音-文本序列的混合数据。
基础版
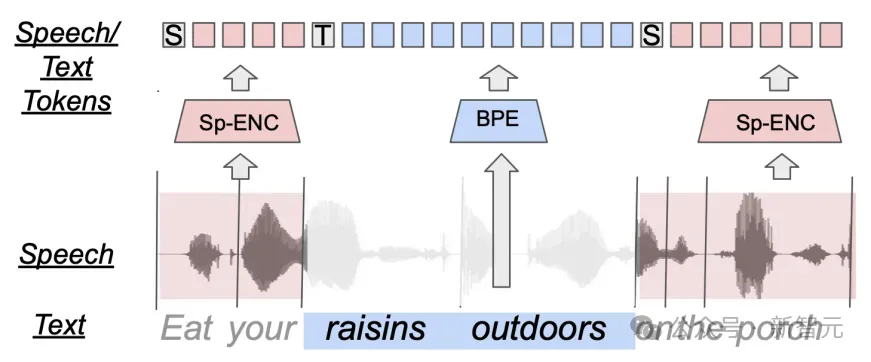
语音编码器
使用的HuBERT模型,该模型在多个数据集的混合上进行训练,包括多语言的LibriSpeech、Vox Populi、Common Voice、Spotify以及Fisher,最后得到一个包含501个音素语音token的词汇表。
语音和文本分词器
使用LLaMA默认的分词器来处理文本,使用前述的HuBERT分词器来处理语音;为了提高模型的质量,对HuBERT的token进行了去重处理;对于单模态数据集(仅文本和仅语音),在分词后的数据前加上相应的模态标记。
文本数据:[TEXT]这是一个文本句子
音频数据:[SPEECH][Hu262][Hu208][Hu499][Hu105]
交错语音和文本(Interleaving Speech and Text)
对于对齐的语音+文本数据集,通过在单词级别交错语音和文本来混合:[TEXT]the cat [SPEECH][Hu3][Hu7]..[Hu200][TEXT]the mat
研究人员认为,交错训练可以帮助模型学习语音和文本之间的对应关系,从而实现更好的文本到语音的转换;在每个训练步骤中,句子中的语音和文本部分是随机采样的。
语音解码器
在从语音token进行语音合成方面,研究人员在Expresso数据集上训练了一个HifiGAN声码器,其依赖于HuBERT语音token和Expresso特定说话人的嵌入向量。
在训练期间,HifiGAN模型会输入重复的token,但同时也会训练一个时长预测模块,可以更准确地知道每个语音token在实际语音中应该持续多久,最终生成一个语音波形。
表达版
HuBERT能够从语音中捕获良好的音素信息,但在表达性方面表现不佳。
研究人员的目标是在不依赖生物特征识别的情况下,模型依然能够理解和保留输入语音中的情感,所以需要用额外的音高token和风格token来补充HuBERT的音素语音token,并将其包含在语言模型训练中,以便训练后的Spirit LM Expressive模型能够捕获并生成更具表现力的语音。
pitch(音高) token
在语音合成和处理中,音高是一个关键因素,决定了声音的高低,对人类理解语句的情感和语气来说非常关键。音高token可以用来捕捉音高变化。当我们说话时,声音的高低起伏不仅可以表达不同的情感,比如兴奋时声音高亢,悲伤时声音低沉,还可以帮助我们在口语交流中区分不同的词语和句子的意图。
研究人员在Expresso数据集上训练了一个VQ-VAE模型,码本大小为64,下采样率为128,即每秒可以产生12.5个音高token;在训练音高量化器时,使用pyaapt8提取基频(F0);使用FCPE9,一个基于Transformer的快速音高估计器,来提高推理速度。
style(风格) token
研究人员提取了语音风格特征来捕捉输入语音的表达风,在输入片段上进行平均池化处理,每秒生成一个特征,然后在Expresso数据集上微调特征来预测表达风格,从而进一步从语音风格特征中去除说话人信息,最后在Expresso数据集的规范化特征上训练了一个有100个单元的k均值聚类。
表达性语音分词器(Expressive Speech Tokenization)
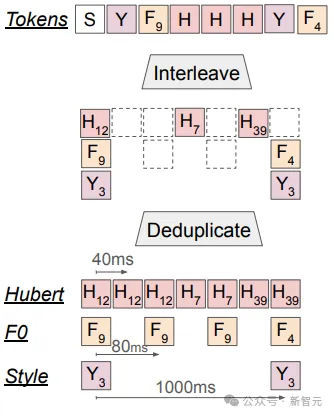
将三种类型的标记(每秒25次的HuBERT标记、每秒12.5次的音高标记和每秒1次的风格标记)按照对应的时间戳进行排序,混合成一个单一的token序列。
与Spirit LM基础版相同,表达版同样对HuBERT的token和音高token进行去重,最后输入序列类似于:[SPEECH][St10][Pi0][Hu28][Hu22][Pi14][Hu15][Pi32][Hu78][Hu234][Hu468]
表达性语音解码器(Expressive Speech Decoder)
研究人员训练了一个HifiGAN模型,依赖于HuBERT token、音高token、风格token以及来自Expresso声音的1-hot说话人嵌入向量。同时还训练了一个时长预测器来预测HuBERT token持续时间。在推理过程中,将每个HuBERT token与相应的音高token和风格标记token,并根据需要进行重复。
实验结果
Spirit LM能够在接收语音token或文本token的提示时,生成语义和表达上一致的内容,将通过定量评估一系列需要生成文本或语音token的基准测试,特别评估Spirit LM在单模态和跨模态场景中的语义能力。

自动语音识别(ASR)和文本转语音(TTS)
与文本语言模型类似,SPIRIT语言智能体可以通过少量样本提示来执行特定任务。
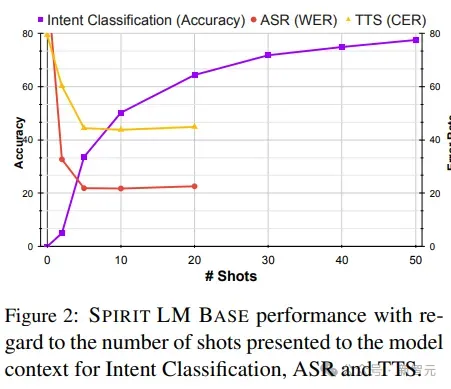
可以看到,Spirit LM使用10个样本的提示能够获得最佳性能,最佳模型在Librispeech清洁数据上的词错误率为21.9,文本转语音的字符错误率为45.5
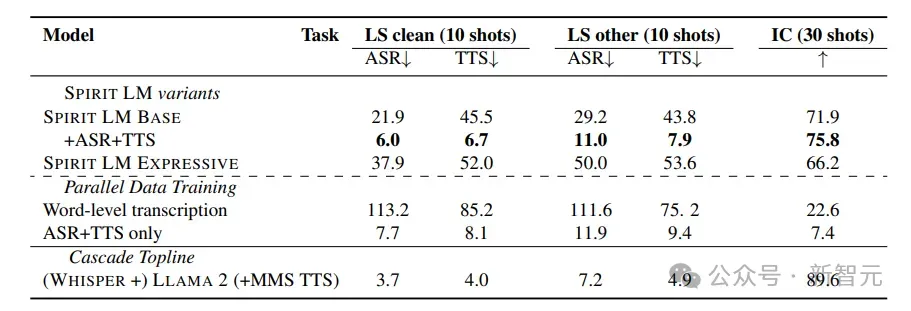
在训练中加入平行的ASR和TTS样本可以极大提高性能,但加入ASR和TTS数据对其他任务的影响非常有限。
在执行语音意图分类(IC)任务时可以发现,随着样本数量的增加,准确率也提高了,模型准确率达到了79%
跨模态对齐
为了更好地理解模型在仅在交错数据和原始语音和文本上训练的情况下,如何实现良好的跨模态性能的隐藏机制,研究人员查看了模型特征的token级相似性,其中特征来自于HuBERT token的输入序列和相应的BPE token,计算了从不同层提取的语音和文本特征的相同单词的最大相似性。
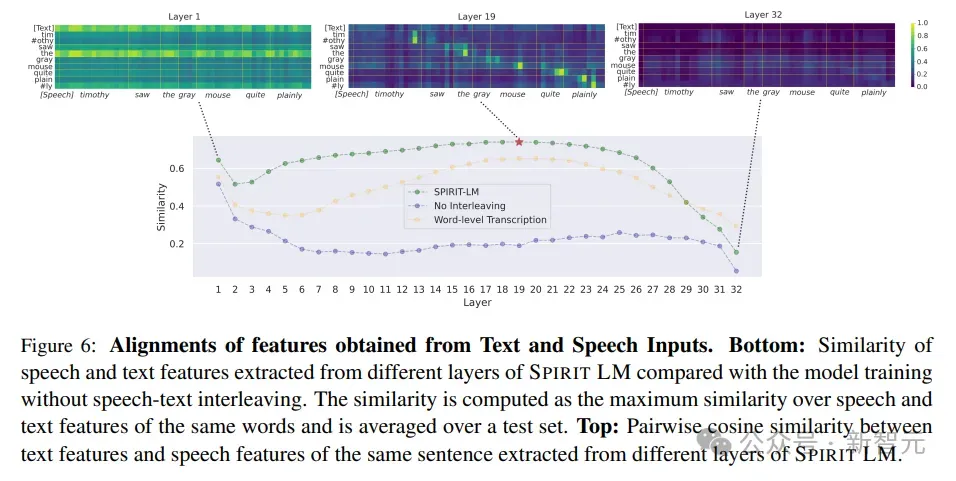
结果发现,模型内部口语和书面序列之间的相似性从第2层和第20层开始增加,并且在早期到中间层中,在用单词级转录训练的模型中效果较差,表明模态混合可以对齐语音和文本,使模型能够将语音序列与相应的文本序列映射起来。
表达性建模
当不给智能体任何先前的样本,直接根据语音或文本提示生成内容(零样本)时,可以发现带有额外音高和风格token的表达版模型在大多数情况下都比基础版模型的表现更好,只是在文本内容生成(文本到文本)方面两者表现差不多。
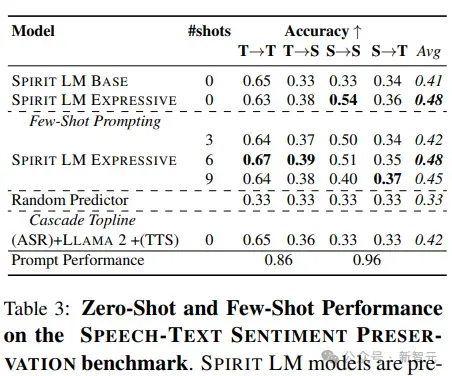
当给模型少量样本来学习时,可以发现这种方法对于除了语音内容生成(语音到语音)之外的所有情况都有帮助。无论是零样本还是少量样本,保持情感的连续性在相同类型的数据(比如文本到文本或语音到语音)中比在不同类型的数据(比如语音到文本)中做得更好;在所有测试中,语音到文本的方向得分最低。
此外,研究人员还直接评估了模型对输入提示的处理能力,结果发现,无论是哪种提示,模型都能得到很高的评分,表明还有很大的空间来进一步提高模型在保持情感表达方面的能力,也意味着,智能体在理解和生成情感丰富的内容方面还有很大的潜力可以挖掘。