DeepSeek

刚刚,新版DeepSeek-R1正式开源!直逼o3编程强到离谱,一手实测来了
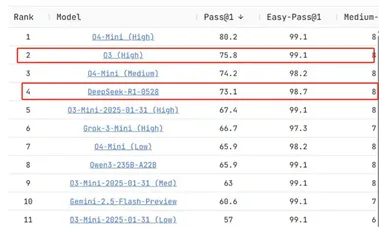
就在今天凌晨,新版DeepSeek-R1正式开源了! DeepSeek-R1-0528模型权重已上传到HuggingFace,不过模型卡暂未更新。 项目地址:,DeepSeek-R1完成了超进化,编码能力强到离谱,而且思考时间更长了。
DeepSeek 全新开源R1-0528 模型登场,性能媲美 OpenAI o3 模型
今天凌晨,知名的开源大模型平台 DeepSeek 发布了其最新版本 R1(0528),引起了广泛关注。 此次发布没有附带详细说明,DeepSeek 选择了 “悄然” 开放模型,预计后续会发布模型卡,进一步介绍其功能。 据悉,R1-0528版本的性能在著名代码测试平台 Live CodeBench 上的测试结果显示,其表现与 OpenAI 最新的 o3模型相当。

DeepSeek R1模型发布0528版 各方面全面提升
DeepSeek官方宣布其R1模型已完成小版本试升级,并已开放给用户进行测试。 此次升级后的模型被命名为「DeepSeek-R1-0528」,在多项测试中展现出惊人的性能。 新版DeepSeek-R1-0528在编程能力、审美设计以及代码完成度上均实现了显著提升。

「DeepSeek 技术解析」:LLM 训练中的强化学习算法
我们将深入探讨 DeepSeek 模型训练策略中的关键创新之一[1, 2]:群组相对策略优化(Grouped Relative Policy Optimization,GRPO)[3]。 为确保本文自成体系并阐明 GRPO 的理论基础,我们将首先介绍强化学习的基础概念,重点解析强化学习(RL)及基于人类反馈的强化学习(RLHF)在 LLM 训练中的核心作用。 接着我们将探讨不同的强化学习范式,包括基于价值的强化学习、基于策略的强化学习和 Actor-Critic 强化学习,回顾经典算法如置信域策略优化(TRPO)和近端策略优化(PPO),最后解析 GRPO 带来的优化创新。

利用DeepSeek与Python自动生成测试用例!
在当今快节奏的软件开发领域,自动化测试已然成为保障软件质量的中流砥柱。 传统手动编写测试用例的方式,非但耗时费力,还极易遗漏关键场景。 所幸,AI 技术的飞速发展为我们带来了全新的解决方案。

OpenAI没做到,DeepSeek搞定了!开源引爆推理革命
DeepSeek-R1引爆了LLM推理革命。 至今,过去一百多天了,引发了持续复制DeepSeek-R1的热潮。 DeepSeek-R1的秘籍在于强化学习微调算法:群体相对策略优化(Group Relative Policy Optimization,GRPO)。

AI实战派:解密DeepSeek企业级项目!AI不是炫技,而是回归需求的必然答案
嘉宾 | 陈亮、张云波主持人 | 薛彦泽撰稿 | 李美涵在AI创业的浪潮里,最迷人的地方莫过于人人都知道这里是风口,却仍然能够各自找到属于自己的机会点。 在众多试图乘上AI风口的创业者中,亨宝科技的CEO张云波和AI创智坊的主理人陈亮无疑是特别的存在。 张云波早年投身于鸿蒙生态,今年年初就敏锐捕捉到DeepSeek大模型兴起的契机,迅速将注意力投向AI领域的应用开发。

首个 AI 翻译实战榜单发布,GPT-4o 领跑市场
在全球 AI 翻译技术迅速发展的背景下,首个应用型 AI 翻译测评榜单 TransBench 正式发布。 这一榜单由阿里国际 AI Business 团队、上海人工智能实验室和北京语言大学联合推出,旨在为行业提供标准化的翻译质量评估。 传统翻译评测不同,TransBench 引入了幻觉率、文化禁忌词和敬语规范等新指标,专注于大模型翻译中的关键问题。

杭州市政府工作报告点名 DeepSeek,力挺算法模型企业发展
据澎湃新闻报道,在5月22日开幕的杭州市十四届人大五次会议上,市长姚高员所作的政府工作报告中特别提到了人工智能企业 DeepSeek(深度求索)及其开源大模型。 报告回顾了2024年杭州的工作成就,肯定了 DeepSeek 等一批大模型在低成本下取得出色表现,并指出其发展“震动全球同业”。 DeepSeek 作为杭州本土新兴科技力量的代表,与其他五家初创公司一同在去年底至今年初迅速崛起,被誉为“杭州六小龙”。

24B模型编程超DeepSeek全家桶,32G内存苹果电脑就能跑,专门针对真实GitHub Issue训练
Mistral沉默好久,果然在憋大招。 刚刚发布最新开源编程模型Devstral,在软件工程任务上一举超过DeepSeek全家桶和Qwen3 235B。 并且参数只有24B,可以在单卡RTX4090甚至32G内存的Mac上运行。

RAG系列:基于 DeepSeek + Chroma + LangChain 开发一个简单 RAG 系统
创建 Next 项目首先,使用 npx create-next-app@latest 根据提示完成 Next 项目的创建:复制创建好项目之后,在 src/app 目录下新建 rag 目录,本次 demo 的代码都将放在这里。 知识库构建接下来,我们将构建知识库,主要目标是将准备好的 pdf 通过向量化存到向量数据库中,以便后续的检索。 由于本次 RAG 系统的开发都要依赖 LangChain 框架,所以我们先在项目中安装 LangChain 框架和核心依赖:复制文档加载LangChain 的 DocumentLoaders[1] 提供了种类丰富的文档加载器,可加载文件系统的文件也可以加载线上文件,包括 csv、docx、pdf、pptx、html、github、youtube等等。

DeepSeek发布大模型训练端到端论文,展示卓越工程深度
近日,DeepSeek发布了一篇关于大模型训练的最佳端到端技术论文,引发业界广泛关注。 该论文全面阐述了DeepSeek在大模型研发中的技术突破,涵盖软件、硬件及混合优化方案,展现了其令人惊叹的工程深度。 在**软件**层面,论文详细介绍了多头潜在注意力机制(MLA),显著降低推理过程中的内存占用;FP8混合精度训练通过低精度计算提升效率,同时保证数值稳定性;DeepEP通信库优化了专家并行(EP)通信,支持FP8低精度操作,加速MoE模型训练与推理;LogFMT对数浮点格式则通过均匀化激活分布,进一步优化计算效率。

CoT推理大溃败?哈佛华人揭秘:LLM一思考,立刻就「失智」
DeepSeek-R1火了,推理模型火了,思维链(Chain-of-Thought,CoT)火了! 模型很聪明,问题是:它还听你的话吗? 思维链很好,但代价呢?

华为 + DeepSeek 推理性能创新高,技术报告公布
华为不仅已经将昇腾在超大规模 MoE 模型推理部署的技术报告分享了出来,在一个月时间内,还会把实现这些核心技术的相关代码也都会陆续开源出来。

北大DeepSeek论文或预定ACL Best Paper!梁文锋署名
重磅惊喜! 北大与DeepSeek合作,并由梁文锋亲自提交到arXiv的论文,将有望斩获ACL 2025最佳论文(ACL Best Paper)。 图片论文地址:,总投稿数高达8000多篇,创历史之最,而ACL 2024总投稿数仅为4407,几乎翻倍!

微软纳德拉应对 AI 新挑战,DeepSeek 崛起引发战略调整
R1的处理成本仅为OpenAI的3.6%,且开源免费,威胁微软对OpenAI的巨额投资。纳德拉迅速组织团队评估并应对,最终选择拥抱竞争,将R1整合进微软云服务Azure。这一事件揭示了纳德拉对AI商品化的独特思考,以及微软在AI战略上的灵活调整。

DeepSeek-V3 发布新论文,揭示低成本大模型训练的奥秘
近日,DeepSeek 团队发布了关于其最新模型 DeepSeek-V3的一篇技术论文,重点讨论了在大规模人工智能模型训练中遇到的 “扩展挑战” 以及与硬件架构相关的思考。 这篇长达14页的论文不仅总结了 DeepSeek 在开发 V3过程中的经验与教训,还为未来的硬件设计提供了深刻的见解。 值得注意的是,DeepSeek 的 CEO 梁文锋也参与了论文的撰写。

英伟达发布新 RL 范式:受 DeepSeek-R1 启发,重塑 AI 模型外部工具能力
英伟达联合推出 Nemotron-Research-Tool-N1 系列模型,受 DeepSeek-R1 启发,采用新型强化学习(RL)范式,强化模型推理能力。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉