DeepSeek
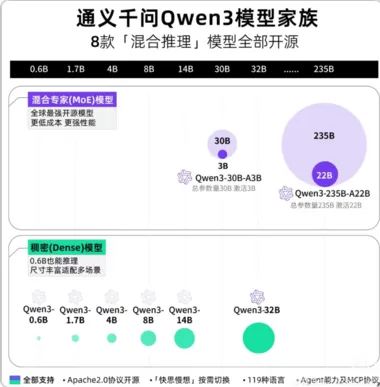
性能与效率的双赢:Qwen3横空出世,MoE架构大幅降低部署成本
阿里云旗下通义千问(Qwen)团队正式发布Qwen3系列模型,共推出8款不同规格的模型,覆盖从移动设备到大型服务器的全部应用场景。 这是国内首个全面超越DeepSeek R1的开源模型,也是首个配备混合思维模式的国产模型。 模型阵容丰富,满足各类部署需求Qwen3系列包含6款Dense模型和2款MoE模型:Dense模型:0.6B、1.7B、4B、8B、14B、32BMoE模型:Qwen3-235B-A22B (总参数235B,激活参数22B)Qwen3-30B-A3B (总参数30B,激活参数3B)所有模型均支持128K上下文窗口,并配备了可手动控制的"thinking"开关,实现混合思维模式。

三招教你私有化部署 DeepSeek
在数字化转型的进程中,企业不仅需要高效、智能的工具来提升运营效率,还需确保数据安全与满足隐私保护要求。 DeepSeek 私有化部署正是为解决这一需求而生的,它通过将 DeepSeek 智能助手从公共云端迁移至企业内部服务器,为企业提供了一种安全、可控且高度定制化的解决方案。 这种部署方 式不仅能够满足企业对敏感数据的保护需求,还能根据具体业务场景进行灵活 调整,从而为企业数字化转型提供强有力的支持。

全国首个黑土侵蚀阻控技术智慧配置平台上线试运行
近日,由中国科学院东北地理与农业生态研究所牵头,西北农林科技大学、中国科学院南京土壤研究所、中国农业科学院农业资源与农业区划研究所、吉林农业大学、吉林省水土保持科学院等联合开发的“智保黑土”上线试运行,这是全国首个大语言模型驱动的黑土侵蚀阻控技术智慧配置平台。

宝马中国宣布新车型接入DeepSeek 含5系、全新X3
宝马中国宣布旗下的新车型将在第三季度接入先进的 DeepSeek 技术。 这一技术将应用于搭载第九代操作系统的多款新车,标志着宝马在智能车载系统方面迈出了重要一步。 根据规划,首批适配车型包括 BMW5系长轴距版、纯电动 i5以及全新 X3长轴距版等,届时,现有车主也将能够体验到这一全新功能。

美国政府「AI行动计划」万言书发布! OpenAI与Anthropic呼吁联手封锁中国AI
AI战打到现在,下一步怎么走? 4月25日,美国网络与信息技术研究与发展(NITRD)公开了美国各界就「AI行动计划」提交的全部书面意见。 网站链接:,在现在这届政府是行不通了,现在,特朗普政府需要一个全新的AI行动计划,继续保持美国的AI领先地位。

如何用DeepSeek+Cursor加速开发微信小程序(实战级指南)
一、工具链核弹级组合1. 双AI引擎配置复制技术协同原理:• Cursor:实时代码生成/缺陷修复(相当于AI程序员)• DeepSeek:业务逻辑设计/架构优化(相当于CTO)2. 环境闪电部署复制二、小程序开发加速流水线1.

李彦宏谈DeepSeek现存痛点 称Deepseek又慢又贵
今日,百度在武汉举办的Create2025AI开发者大会上,创始人李彦宏以“模型的世界,应用的天下”为主题发表近60分钟演讲,正式发布文心大模型4.5Turbo与X1Turbo版本,并披露DeepSeek模型在百度生态中的落地进展与现存挑战。 李彦宏透露,百度旗下文小言、百度搜索、百度地图等核心产品已接入DeepSeek满血版模型,在智能客服、搜索增强等场景实现效率提升。 但他同时坦言,DeepSeek目前仍存在技术局限:“该模型仅支持文本处理,无法完成图片、音频、视频的多模态内容生成,而百度智能云超六成企业客户对多模态能力有明确需求。

李飞飞/DeepSeek前员工领衔,复现R1强化学习框架,训练Agent在行动中深度思考
什么开源算法自称为DeepSeek-R1(-Zero) 框架的第一个复现? 新强化学习框架RAGEN,作者包括DeepSeek前员工Zihan Wang、斯坦福李飞飞团队等,可训练Agent在行动中深度思考。 图片论文一作Zihan Wang在DeepSeek期间参与了Deepseek-v2和Expert Specialized Fine-Tuning等工作,目前在美国西北大学读博。

DeepSeek在数据领域的30个应用场景
在这个数据AI的时代,DeepSeek作为新一代AI模型正在改变我们处理、分析和理解数据的方式。 本文为您揭秘DeepSeek在数据领域的30个颠覆性应用场景,带大家一窥AI如何重塑数据价值链。 一、数据获取与处理篇1.

国家知识产权局:中国成为全球AI专利最大拥有国,占比达60%
国家知识产权局局长申长雨在国务院新闻办公室的发布会上透露,中国在人工智能领域正展现出强劲的发展势头。 根据世界知识产权组织的报告,中国已成为全球人工智能专利的最大拥有国,专利数量占全球总量的60%。 这一成就不仅反映了中国在科技创新方面的突破,也彰显了其在新兴产业中的领导地位。

宝马将在中国新车型中引入DeepSeek人工智能
在近日于上海举行的汽车展上,德国汽车制造商宝马(BMW)宣布,将于今年晚些时候在其新车型中集成中国初创公司 DeepSeek 的人工智能技术。 宝马首席执行官奥利弗・齐普塞(Oliver Zipse)在展会上表示,这一举措标志着宝马在中国市场进一步加强与本地科技公司的合作。 齐普塞强调,中国在人工智能领域的创新步伐迅速,宝马希望借助这种技术提升其汽车的智能化水平。

外媒:DeepSeek震撼世界 中国大学成为AI人才池
近年来,美国频繁渲染所谓的“中美争夺AI霸权”,尽管这一说法是否契合现实尚存争议,但不可否认的是,在美国的AI战略视野中,中国已被明确界定为核心竞争对手。 《巴伦周刊》报道称,当前美国在AI创新领域依然保持领先地位,不过中国正在快速缩小差距。 在学术研究、资本投入以及政策战略布局等关键层面,中国展现出强大的追赶态势:海量论文产出彰显科研活力,持续增长的投资为产业发展注入动力,而系统的政策支持更是为AI技术发展筑牢根基。

更懂公务员的大模型:写作/意图理解/公文排版全拿捏,部署成本直降90%,来自金山
当政务大模型具备推理能力,部署成本直降90%,写作效率提升71.58%、意图理解提升34.87%、公文排版能力提升12%。 如上新进展,来自金山办公。 时隔四个月,金山自研政务大模型完成推理能力升级。

这样在本地搭建DeepSeek可以直接封神:本地部署+避坑指南(升级版)
本文旨在提供一个全面且详细的DeepSeek本地部署指南,帮助大家在自己的设备上成功运行DeepSeek模型。 无论你是AI领域的初学者还是经验丰富的开发者,都能通过本文的指导,轻松完成DeepSeek的本地部署。 一、本地部署的适用场景DeepSeek本地部署适合以下场景:高性能硬件配置:如果你的电脑配置较高,特别是拥有独立显卡和足够的存储空间,那么本地部署将能充分利用这些硬件资源。

基于 Spring AI + MCP + DeepSeek-R1-7B 构建企业级智能 Agent 工具调用系统
在大模型 Agent 发展浪潮下,如何通过模型驱动外部工具调用(Tool Calling)已成为构建智能业务系统的关键能力。 本文将手把手带你通过 Spring AI MCP(Model Context Protocol) DeepSeek-R1-7B 打造一个可落地的企业级智能 Agent。 项目背景与架构设计技术选型Spring AISpring 官方推出的 AI 接入框架,支持 LangChain、MCP、RAG 等能力;MCP(Model Context Protocol)模型与工具之间通信的协议桥梁;DeepSeek-R1-7B国产高性能开源大模型,已支持 Chat Completion、Tool Calling 接口;Ragflow用作 RAG 架构引擎(可选);系统功能用户向模型提问模型判断是否调用工具(如数据库查询)MCP 注册的工具服务完成任务模型生成最终响应环境准备安装依赖复制本地部署 DeepSeek-R1-7B 模型推荐使用 vLLM 启动 DeepSeek-R1-7B 模型服务:复制构建 Spring AI MCP 工具服务示例业务:产品信息查询复制注册 MCP 工具复制模型端配置(Ragflow 示例)在 ragflow.config.yaml 中配置模型地址及 MCP 工具启用:复制前端调用(可选)复制测试效果用户输入:复制输出结果:复制模型会自动触发 query-product 工具,无需用户指定,展示 Agent 工具能力。

DeepSeek 梁文锋入选《时代》周刊“2025 年全球最具影响力 100 人”
梁文锋出现在了“Pioneers(拓荒者)”分类中。企业家名人中,AMD CEO 苏姿丰、Meta CEO 马克・扎克伯格也成功上榜,不过均在“Titans(巨人、伟人)”分类中。

DeepSeek创始人梁文锋荣登《时代》“2025年全球最具影响力100人”榜单
近日,DeepSeek创始人梁文锋入选《时代》杂志“2025年全球最具影响力100人”榜单,成为全球科技与金融领域的领军人物之一。 与此同时,梁文锋还凭借330亿元人民币的财富首次登上了2025年3月27日发布的《胡润全球富豪榜》,进一步巩固了他在全球商业界的影响力。 梁文锋的成功之路始于2008年,当时他开始带领团队利用机器学习等前沿技术,探索全自动量化交易。
微信首个AI助手 “元宝” 正式上线,可以添加为微信好友
微信平台推出了首个 AI 助手 ——“元宝”。 用户只需在微信中搜索 “元宝”,添加为好友后,即可轻松与其进行对话。 与传统的聊天机器人不同,元宝以好友的身份出现,无需下载其他应用或小程序,聊天时甚至会显示 “对方正在输入...” 的信息,带来更加真实的互动体验。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉