DeepSeek

Poe:DeepSeek使用率下降50%,快手崛起、OpenAI暴涨
今天凌晨,全球著名大模型整合应用平台Poe发布了,2025年春季AI模型使用趋势报告。 结果显示,DeepSeek R1的使用率从2月中旬的峰值7%下降到了4月底的3%,整体使用率下降超过50%;OpenAI由于在GPT-4o推出新的文生图功能后,例如,吉卜力风格、仿真自拍等类型图片,实现病毒式增长使用率暴涨。 下面「AIGC开放社区」将从文本、视频、推理、图像和音频5大领域为大家解读这份报告。

绝!三招教你私有化部署 DeepSeek
在数字化转型的进程中,企业不仅需要高效、智能的工具来提升运营效率,还需确保数据安全与满足隐私保护要求。 DeepSeek 私有化部署正是为解决这一需求而生的,它通过将 DeepSeek 智能助手从公共云端迁移至企业内部服务器,为企业提供了一种安全、可控且高度定制化的解决方案。 这种部署方 式不仅能够满足企业对敏感数据的保护需求,还能根据具体业务场景进行灵活 调整,从而为企业数字化转型提供强有力的支持。

DeepSeek回应“崩了”:部分功能已恢复正常
今日,DeepSeek突发状况引发网友广泛关注与热议,迅速成为网络焦点。 大量网友反馈,在使用DeepSeek时遭遇严重问题。 不少人表示,点进DeepSeek后页面疯狂转圈,根本无法正常使用。

(更新:对话功能恢复正常)DeepSeek 出现服务问题,登录失败、无法对话
据IT之家小伙伴反馈,DeepSeek 今日下午出现服务问题,主要影响网页端对话。#deepseek崩了##deepseek#

DeepSeek公开致谢腾讯技术团队 助力DeepSeek通信框架提速100%
DeepSeek近日发文公开致谢腾讯技术团队,称其对DeepSeek开源通信框架DeepEP的优化是一项“huge speedup”级别的代码贡献。 此次优化聚焦于在多种网络环境下提升通信性能。 经测试,优化后的DeepEP在RoCE网络环境下性能提升高达100%,在IB(InfiniBand)网络环境下提升约30%,显著增强了通信效率,为AI大模型训练提供了更稳定、高效的底层支撑。

低价大模型 DeepSeek 实用指南
火爆全网的国产大模型 DeepSeek,其 API 价格仅为同类模型的几十分之一。 图片DeepSeek 网页端与 API 应用场景DeepSeek 网页端界面简洁直观,但 API 使用需要一定技巧。 本文将从对话、知识库、AI 翻译、AI 编程及 Python 调用等多个场景,分篇评测 DeepSeek API 的实际应用。

DeepSeek 致谢腾讯技术团队,DeepEP 开源通信框架性能显著提升
经测试,优化后的通信框架性能在 RoCE 网络环境提升 100%,IB 网络环境提升 30%,为企业开展 AI 大模型训练提供更高效的解决方案。

腾讯元宝宣布文生图功能升级:混元和 DeepSeek 都已支持生图
腾讯元宝宣布文生图功能升级,结合混元和DeepSeek技术,用户只需一句话指令即可生成高质量图像。新功能已在元宝全端上线,支持复杂场景和艺术风格生成。#腾讯元宝# #AI生图#

DeepSeek开源的文件系统,是如何提升大模型效率的?
在 AI 领域里,大模型通常具有百亿甚至数千亿参数,训练和推理过程对计算资源、存储系统和数据访问效率提出了极高要求。 2 月 28 日,DeepSeek 开源了一种高性能分布式文件系统 3FS,官方表示其目的是解决人工智能训练和推理工作负载的挑战。 作为一种并行文件系统,3FS 可以在 180 节点集群中实现 6.6 TiB/s 的聚合读取吞吐量,对于提高 DeepSeek V3、R1 大模型的训练数据预处理、数据集加载、检查点保存/重新加载、嵌入向量搜索和 KVCache 查找等工作的效率有重要帮助。

DeepSeek还没登场,Qwen3 已经抢先引爆AI开源圈
AI 社区原本期盼 DeepSeek 发布重磅新品,却意外迎来了另一款令人瞩目的中国开源模型:Qwen3 正式登场。 此次发布的旗舰型号为 Qwen3-235B-A22B。 其中,235B 代表总参数量;而 A22B 指的是该模型采用了“专家混合”(Mixture of Experts,简称 MoE)架构,实际在每次查询中激活的参数量仅约为 220亿(22B)。

深夜突袭,DeepSeek-Prover-V2加冕数学王者!671B数学推理逆天狂飙
就在刚刚,DeepSeek-Prover-V2正式发布。 此次DeepSeek-Prover-V2提供了两种模型尺寸:7B和671B参数。 DeepSeek-Prover-V2-671B:在DeepSeek-V3-Base基础上训练,推理性能最强。
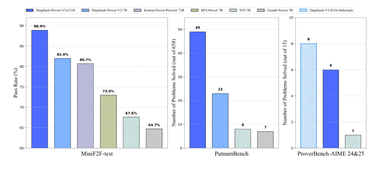
数学推理新标杆!DeepSeek-Prover-V2 实现数学证明的飞跃
在人工智能领域,最近一项重磅技术发布引发广泛关注 ——DeepSeek-Prover-V2。 这一模型不仅在推理性能上取得了显著提升,还被誉为通向人工通用智能(AGI)的关键一步。 DeepSeek-Prover-V2在推理能力和训练效率上都进行了革命性的创新,给数学推理研究带来了新的希望。

DeepSeek-Prover-V2 登场:AI 数学推理新王者,88.9% 通过率设新标杆
深度求索(DeepSeek)昨日(4 月 30 日)在 AI 开源社区 Hugging Face 上,发布名为 DeepSeek-Prover-V2-671B 的新模型,随后在 GitHub 等平台上公布了论文信息。

看不懂新开源的DS-Prover V2版本?解读来了,攻克像人类一样数学证明,达到SoTA水平,不知道如何测?样题来了
五一凌晨,DeepSeek终于更新了新开源的 DeepSeek-Prover V2的自述文件。 速览一下: - 解决近 90% 的 miniF2F 问题(88.9%) - 显著提高 PutnamBench 上的 SoTA 性能 - 在正式版本中对 AIME 24 和 25 问题取得了惊艳的通过率点评:亮点上来看,DeepSeek-Prove V2模型在死磕LLM在推理数学问题上能给出答案但却给不出严格正确的推理步骤的问题。 而且在一中先进模型中达到了SoTA的水平,图四是前十榜单。

DeepSeek-Prover-V2-671B 模型开源,数学推理领域迎来新突破
中国 AI 初创公司 DeepSeek 再次掀起开源 AI 领域的热潮,正式发布其最新开源模型 DeepSeek-Prover-V2-671B。 这一拥有6710亿参数的超大规模语言模型,专为数学推理和问题解决设计,展现了 DeepSeek 在高效 AI 开发上的持续创新能力。 根据社交媒体上的最新讨论,这一模型被认为是 DeepSeek 在数学领域的重要里程碑,或将推动全球 AI 研究与应用的进一步发展。

DeepSeek-Prover-V2-671B 新模型开源发布
DeepSeek-Prover-V2-671B 使用了更高效的 safetensors 文件格式,并支持 BF16、FP8、F32 等多种计算精度,方便模型更快、更省资源地训练和部署。

Meta AI 独立App炸场上线!小扎力挺开源:与 DeepSeek、Qwen 一起对抗“闭源”AI
Meta又搞了个大活。 就在LlamaCon开发者大会上,这家社交巨头一口气发布了Meta AI独立App和Llama 云 API,正式把自家的AI推到了“社交 个性化 开放生态”的新维度。 图片是的,你没看错——继在WhatsApp、Instagram、Facebook、Messenger里塞满AI助手之后,Meta终于把AI单独做成了App,直接对标ChatGPT。

DeepSeek定制训练:微调与推理技术应用
一. 前言介绍本文内容:模型加载与预处理:详细讲解如何加载预训练模型、分词器,并处理输入数据集。 LoRA配置:介绍如何使用LoRA技术配置模型,并高效进行微调,节省计算资源。
资讯热榜
标签云
AI
人工智能
OpenAI
AIGC
模型
ChatGPT
谷歌
DeepSeek
AI新词
AI绘画
大模型
机器人
数据
Midjourney
开源
Meta
微软
智能
用户
GPT
学习
英伟达
Gemini
智能体
技术
马斯克
Anthropic
图像
AI创作
训练
LLM
论文
AI for Science
代码
腾讯
苹果
算法
Agent
Claude
芯片
具身智能
Stable Diffusion
xAI
蛋白质
人形机器人
开发者
生成式
神经网络
机器学习
AI视频
3D
大语言模型
字节跳动
RAG
Sora
百度
研究
GPU
生成
华为
工具
AGI
计算
生成式AI
AI设计
大型语言模型
搜索
亚马逊
AI模型
视频生成
特斯拉
DeepMind
场景
Copilot
深度学习
Transformer
架构
MCP
编程
视觉