AI 社区原本期盼 DeepSeek 发布重磅新品,却意外迎来了另一款令人瞩目的中国开源模型:
Qwen3 正式登场。
此次发布的旗舰型号为 Qwen3-235B-A22B。其中,235B 代表总参数量;而 A22B 指的是该模型采用了“专家混合”(Mixture of Experts,简称 MoE)架构,实际在每次查询中激活的参数量仅约为 220亿(22B)。
但最引人关注的是:
Qwen3 已能与一线模型如 DeepSeek R1、o3 Mini、Grok 3 和 Gemini 2.5 Pro 相媲美。
性能实测:全面对标顶级大模型
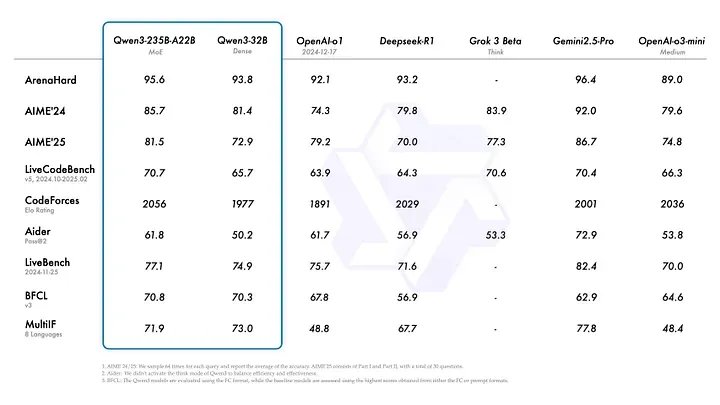
根据官方博客提供的多项基准测试数据:
 图片
图片
- 在 ArenaHard 测试中,Qwen3 已超越了 o3 Mini,且与 Gemini 2.5 Pro 非常接近。
- 在 AIME 24 和 25 测试中,其表现介于 Gemini 2.5 Pro 和 o3 Mini 之间。
- 在编程相关的 LiveCodeBench 和 CodeForces 测试中,甚至超过了 Gemini 2.5 Pro。
这一系列表现彰显了 Qwen3 的强大竞争力。
 图片
图片
模型种类丰富,覆盖多种需求
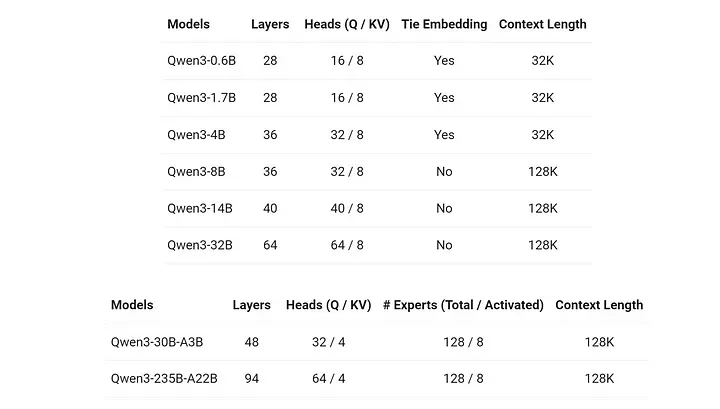
此次发布除了旗舰的 MoE 模型外,还包含了从 32B 到 6B 参数量不等的 6 款稠密模型(Dense Models,非专家混合型),以满足不同算力需求的场景。
所有模型都将开源发布于:
- HuggingFace
- ModelScope
- Kaggle
🚀 令人期待的独特功能
Qwen3 一位开发者暗示,该模型具有一些“未在官方模型卡中详细说明的特殊功能”,未来将在科研及产品开发方面带来新可能。
已公开的关键功能包括:
- 可在**常规模式(Regular Mode)与深度思考模式(Extended Thinking Mode)**间自由切换;
- 提供高效的“思考预算”管理机制(Thinking Budget),即允许用户自由控制模型用于推理的 Token 数量,投入更多 Token 时效果显著提升;
- 支持多达 119 种语言,具备明显增强的代码生成与智能代理(Agentic)能力。
庞大的训练数据集与创新的训练策略
Qwen3 采用的数据集规模空前,接近 Qwen2.5 所用 **18 万亿 Token(18T)**的两倍,达到约 35 万亿 Token(35T)。
在训练过程中,研究团队还创新性地利用自家模型迭代强化训练数据:
- 使用 Qwen2.5VL 模型从文档中提取文本内容;
- 再以 Qwen2.5 基础模型对上述文本内容进行提升优化;
- 同时借助 Qwen2.5 Math 与 Coder 模型生成高质量合成数据。
这种逐步迭代的训练方法,使模型在每个阶段都实现了性能的递进式提升。
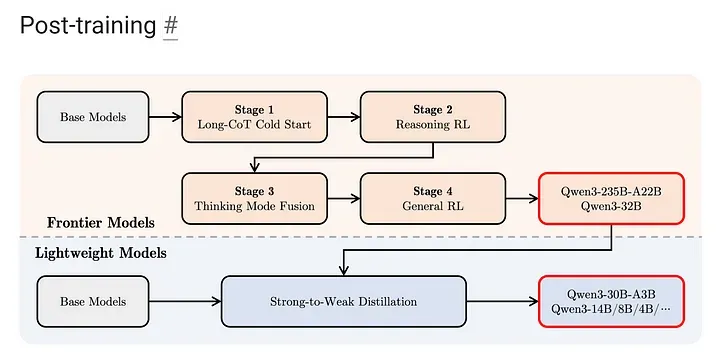
此外,训练过程分为三个预训练阶段与四个后续训练阶段:
 图片
图片
预训练阶段:
- 通用语言数据:约 30 万亿 Token;
- 知识密集型数据:额外 5 万亿 Token;
- 扩展上下文长度至 32K Token。
后续训练阶段:
- 长链思考训练(Long Chain-of-Thought);
- 强化学习微调(Reinforcement Learning);
- 思考模式融合(Thinking Mode Fusion);
- 一般化强化学习。
对更轻量级模型,则采取了知识蒸馏(Distillation)的方式,从大模型向小模型传递能力,从而实现了在边缘设备与手机端的高效部署。
完全开源,商业友好
Qwen3 全系列模型采用 Apache 2.0 协议 完全开源,允许开发者:
- 商业化应用;
- 创建衍生作品;
- 以合规署名方式自由销售基于 Qwen3 构建的产品。
开发团队表示:
“我们相信,AI 模型的开发正在从以训练模型为中心,转向以训练智能代理(Agent)为核心的新时代。”
市场竞争日益激烈
随着 Qwen3 的强势发布,以及 DeepSeek 可能即将公布的新模型,未来几周 AI 领域势必掀起新一轮的技术竞赛热潮。
AI 从业者与观察人士无不期待,这场竞争将如何推动技术边界持续扩展。
观点与讨论
本次 Qwen3 的突然崛起,不仅标志着中国开源 AI 模型的又一里程碑,也意味着行业格局或将再次面临洗牌。


